




 本文介绍了如何使用OCR技术、二值转化和PIL库自动化构造移动端UI的文字重叠样本,以供AI模型训练。通过筛选文字区域,计算像素均值,最终在原图上生成异常样本。
本文介绍了如何使用OCR技术、二值转化和PIL库自动化构造移动端UI的文字重叠样本,以供AI模型训练。通过筛选文字区域,计算像素均值,最终在原图上生成异常样本。
做这个东西有什么用?
在自动化过程中进行文字重叠智能诊断,需要训练AI模型,训练AI模型的前提是构造异常样本,传统手工收集的样本量级太低,所以需要自动化去构造数据样本,本文章说明了 文字重叠样本如何构造。
1.通过ocr识别页面中的文字位置,识别阈值大于0.95进行筛选,删除数字区域和比较短的文字区域
原图

筛选
reader = easyocr.Reader(['ch_sim', 'en'])
ret = []
result_1 = reader.readtext(path)
for info in result_1:
if info[2] > 0.70:
if len(str(info[1])) >= 3 and not bool(re.search(r'\d', str(info[1]))):
print("筛选之后的文字==> ", str(info[1]))
ret.append(info)
筛选之后的文字==> 宝宝辅食
筛选之后的文字==> 母婴童装
筛选之后的文字==> 等着你来挑
筛选之后的文字==> 休闲零食正品货
筛选之后的文字==> 立即购买
筛选之后的文字==> 京东超市
筛选之后的文字==> 京东电器
筛选之后的文字==> 女生衣橱
筛选之后的文字==> 免费水果
筛选之后的文字==> 京东到家
筛选之后的文字==> 生活:缴费
筛选之后的文字==> 领京豆
筛选之后的文字==> 京东会员
筛选之后的文字==> 京东秒杀
筛选之后的文字==> 京东直播
筛选之后的文字==> 超值精选
筛选之后的文字==> 享优惠福利
筛选之后的文字==> 排行榜
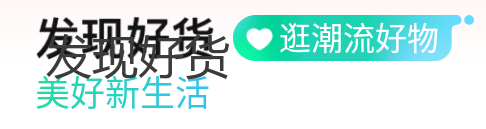
筛选之后的文字==> 发现好货
筛选之后的文字==> 逛潮流好物
筛选之后的文字==> 闭眼跟榜买
筛选之后的文字==> 美好新生活
筛选之后的文字==> 购物车
2.随机挑选一个文字区域,二值转化,计算面积较少的区域为文字区域
i = random.sample(ret, 1)[0]
ret.remove(i)
start_xy = i[0][0]
end_xy = i[0][-2]
print("随机挑选文字进行重叠样本实验==>", i[1])
# 找到黑色坐标集合
black_ls, white_ls, size = find_black_xy(img_2, start_xy, end_xy)
if len(black_ls) >= len(white_ls):
print("判定白色字体")
return i,white_ls, size
print("判定黑色字体")
return i, black_ls, size
本地挑选的为京东会员,并判定为黑色字,如果是白色字体直接舍弃,重新获取,因为白色字体多为图片上的文字,不符合构造需求

3.获取文字区域集合,计算文字像素均值
def compute_area_rgb_avg(img_0, black_ls):
r = 0
g = 0
b = 0
count = len(black_ls)
for i in black_ls:
x = i[0]
y = i[1]
# 注意 cv读取的图像是BGR图像
r += img_0[y, x][2]
g += img_0[y, x][1]
b += img_0[y, x][0]
print("Select area rgb value ==>", [r / count, g / count, b / count])
输出:Select area rgb value ==> [50.33875338753388, 50.33875338753388, 50.33875338753388]
4.利用PIL在原图上构造重叠样本
def draw_pic(path, img, size, area, color, text):
"""
指定坐标,颜色,文本,进行划线
:param size: 通过area 获取像素h*3/4 换算的
:param area: ocr识别的文字区域,然后随机挑选的 [x0,y0,x1,y1]
:param color: 动态获取的颜色
:return:
"""
from PIL import ImageFont, ImageDraw, Image
import numpy as np
x = area[0]
y = area[1]
# 设置需要显示的字体
font_path = r'C:\Windows\Fonts\msyh.ttc'
font = ImageFont.truetype(font_path, int(size))
img_pil = Image.fromarray(img)
draw = ImageDraw.Draw(img_pil)
# 随机偏移
offset = 15
offset_xy = random.sample([(x + offset, y), (x, y + offset), (x + offset, y + offset)], 1)[0]
# 绘制文字信息
draw.text(offset_xy, text, font=font, fill=color)
bk_img = np.array(img_pil)
save_img(bk_img)
5. 最终效果


















 1230
1230

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









