







文章目录
什么是线性判别分析
引自周志华老师的《机器学习》
线性判别分析是一种经典的线性学习方法,给定训练样例集,设法将样例投影到一条直线上,使得同类样例的投影点尽可能的近,异类样例的投影点尽可能原,在对新样本进行分类时,将其投影到同样的这条直线上,在根据投影点的位置来确定新样本的类别
一个直观的例子: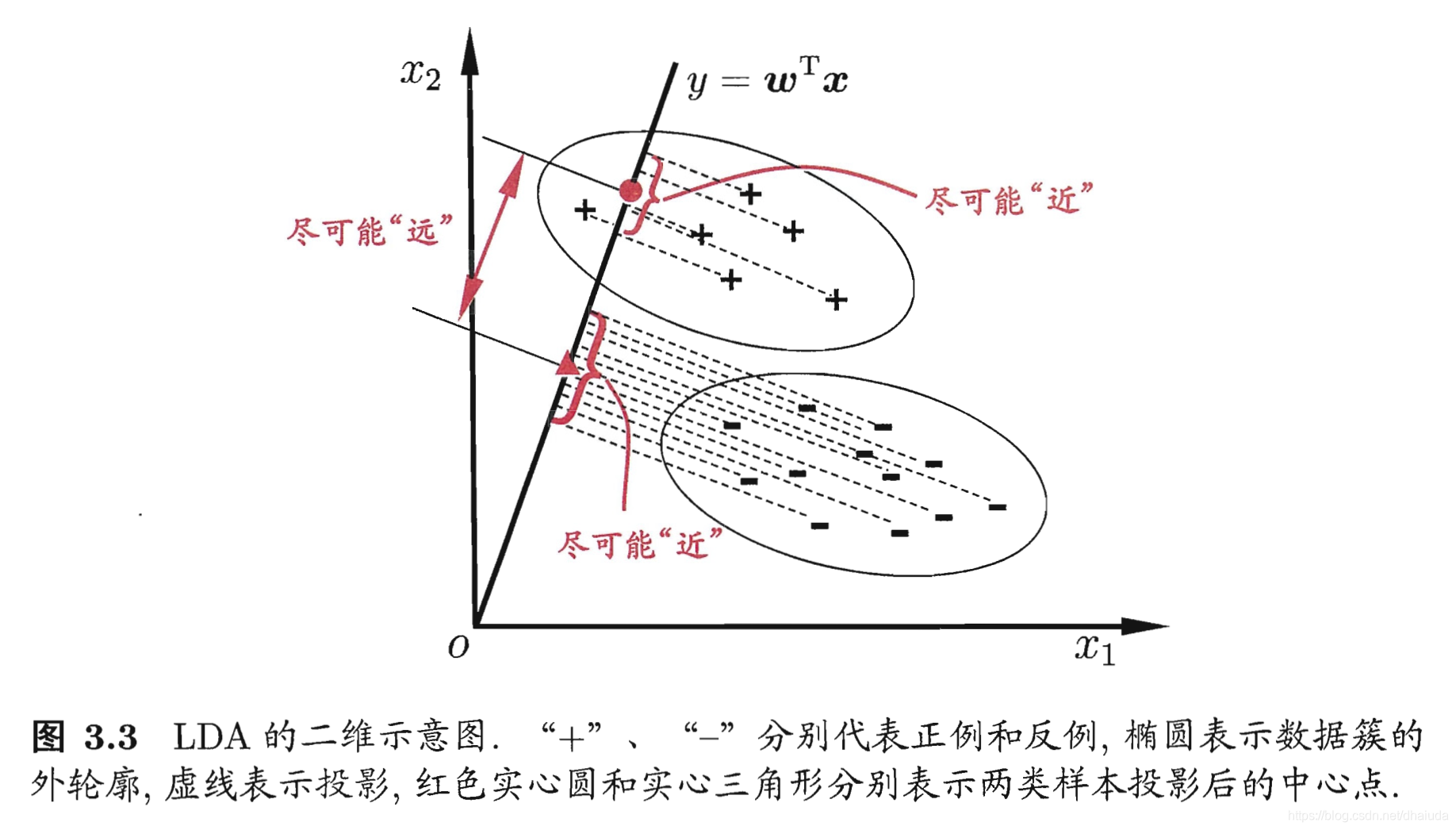
线性判别分析的作用
1、分类
2、降维,其将高维空间的点映射到一条直线上,用一个实数来表示高维空间的点,此时点的描述信息会会全部丢失,例如用三个维度(形状、甜度、颜色)来描述苹果,有一个苹果在这三个维度的得分为(1,2,3),则可以用(1,2,3)来表述这个苹果的特征,利用线性判别分析投影到直线后,我们用一个实数来表示这个苹果,但是我们无法知道苹果的甜度是多少
基本思想
线性判别分析具有两个关键点
- 1、投影后,不同类别的点尽可能远离
- 2、投影后,相同类别的点尽可能靠近
对于关键点1,我们可以使用投影后,不同类别的中心点之间的距离来衡量,中心点距离越远,类别之间的区分度越高
对于关键点2,我们可以使用方差来衡量投影后同类别点之间的散乱程度(方差的统计意义便是衡量点与点之间的散乱程度),方差越小,投影后同类别的数据之间越靠近
如何将点投影到直线上
周志华老师的《机器学习》一书并没有明显说明如何将点投影到直线上,那么我们如何用式子去刻画点投影到直线这个动作呢?
我们来看看维基百科对于线性回归的定义 我是链接:
线性判别分析 (LDA)是对费舍尔的线性鉴别方法的归纳,这种方法使用统计学,模式识别和机器学习方法,试图找到两类物体或事件的特征的一个线性组合,以能够特征化或区分它们
LDA试图通过特征的线性组合来特征化或区分它们,若特征为( x 1 x_{1} x1, x 2 x_{2} x2,…, x d x_{d} xd),那么LDA的输出应该是
y = w 1 x 1 + w 2 x 2 + . . . + w d x d (1.0) \begin{aligned} y=w_1x_1+w_2x_2+...+w_dx_d \end{aligned}\tag{1.0} y=w1x1+w2x2+...+wdxd(1.0)
令 w w w=( w 1 w_1 w1, w 2 w_2 w2,…, w d w_d wd),x=( x 1 x_1 x1, x 2 x_2 x2,…, x d x_d xd),则式1.0可重写为
y = w T x (1.1) \begin{aligned} y=w^Tx \end{aligned}\tag{1.1} y=wTx(1.1)
式1.1可看成是向量 w w w与向量 x x x的点乘,向量点乘可以写成: w T ∗ x w^T*x wT∗x=| w w w|| x x x|cos θ \theta θ,其几何意义为向量 x x x在向量 w w w方向的投影长度的| w w w|倍,投影的直线为向量 w w w所在方向的直线,可见线性判别分析不是把点投射到直线上,而是将点投射到直线后。在拉长| w w w|倍,由于所有的投影点都拉长了| w w w|倍,所以点与点之间的相对位置不变(虽然点与点的距离发生了变化,但只要相对位置不变,影响就不会很大)。线性判别分析用投影长度来刻画投影后点的位置。
二分类线性判别分析
接下来的任务就是如何使用式1.1去刻画第二节所述的两个关键点,我们从一个例子入手
假设我们现有一个问题——判断一个工厂生产的零件是不是好零件,一个零件只有好和坏之分,因此这是一个二分类问题,设一个零件具有d个特征,假设我们有一批样本数据,
好零件的样本为:
(
x
11
,
x
12
,
.
.
.
,
x
1
d
)
,
(
x
21
,
x
22
,
.
.
.
,
x
2
d
)
,
.
.
.
,
(
x
n
1
,
x
n
2
,
.
.
.
,
x
n
d
)
(x_{11},x_{12},...,x_{1d}),(x_{21},x_{22},...,x_{2d}),...,(x_{n1},x_{n2},...,x_{nd})
(x11,x12,...,x1d),(x21,x22,...,x2d),...,(xn1,xn2,...,xnd)
坏零件的样本为:
(
x
11
′
,
x
12
′
,
.
.
.
,
x
1
d
′
)
,
(
x
21
′
,
x
22
′
,
.
.
.
,
x
2
d
′
)
,
.
.
.
,
(
x
n
1
′
,
x
n
2
′
,
.
.
.
,
x
n
d
′
)
(x_{11}',x_{12}',...,x_{1d}'),(x_{21}',x_{22}',...,x_{2d}'),...,(x_{n1}',x_{n2}',...,x_{nd}')
(x11′,x12′,...,x1d′),(x21′,x22′,...,x2d′),...,(xn1′,xn2′,...,xnd′)
好零件与坏零件都有n个样本。
如何刻画类别的中心点之间的距离
线性判别分析使用均值来刻画类别中心点,好零件的均值向量 x ‾ \overline{x} x为
( ∑ i = 1 n x i 1 n , ∑ i = 1 n x i 2 n , . . . . . , ∑ i = 1 n x i d n ) (\frac{\sum_{i=1}^nx_{i1}}{n},\frac{\sum_{i=1}^nx_{i2}}{n},.....,\frac{\sum_{i=1}^nx_{id}}{n}) (n∑i=1nxi1,n∑i=1nxi2,.....,n∑i=1nxid)
投影后,各样本的值为
∑ i = 1 d w i x 1 i , ∑ i = 1 d w i x 2 i , . . . , ∑ i = 1 d w i x n i \sum_{i=1}^dw_ix_{1i},\sum_{i=1}^dw_ix_{2i},...,\sum_{i=1}^dw_ix_{ni} i=1∑dwix1i,i=1∑dwix2i,...,i=1∑dwixni
投影后,样本的均值为
∑ i = 1 d w i x 1 i + ∑ i = 1 d w i x 2 i + . . . + ∑ i = 1 d w i x n i n (1.2) \begin{aligned} \frac{ \sum_{i=1}^dw_ix_{1i}+\sum_{i=1}^dw_ix_{2i}+...+\sum_{i=1}^dw_ix_{ni}}{n} \end{aligned}\tag{1.2} n∑i=1dwix1i+∑i=1dwix2i+...+∑i=1dwixni(1.2)
1.2可变为:
w 1 ∑ i = 1 n x i 1 n + w 2 ∑ i = 1 n x i 2 n + . . . + w d ∑ i = 1 n x i d n (1.3) \begin{aligned} \frac{w_1\sum_{i=1}^nx_{i1}}{n}+\frac{w_2\sum_{i=1}^nx_{i2}}{n}+...+\frac{w_d\sum_{i=1}^nx_{id}}{n} \end{aligned}\tag{1.3} nw1∑i=1nxi1+nw2∑i=1nxi2+...+nwd∑i=1nxid(1.3)
1.3可变为:
( w 1 , w 2 , . . . , w d ) T ∗ ( ∑ i = 1 n x i 1 n , ∑ i = 1 n x i 2 n , . . . . . , ∑ i = 1 n x i d n ) ⇒ w T x ‾ (1.4) \begin{aligned} (w_1,w_2,...,w_d)^T*(\frac{\sum_{i=1}^nx_{i1}}{n},\frac{\sum_{i=1}^nx_{i2}}{n},.....,\frac{\sum_{i=1}^nx_{id}}{n})\Rightarrow w^T\overline{x} \end{aligned}\tag{1.4} (w1,w2,...,wd)T∗(n∑i=1nxi1,n∑i=1nxi2,.....,n∑i=1nxid)⇒wTx(1.4)
同理可得坏零件的均值为:
w T x ′ ‾ (1.5) \begin{aligned} w^T\overline{x'} \end{aligned}\tag{1.5} wTx′(1.5)
类别的中心点之间的距离可以通过下列式子进行刻画
( w T x ‾ − w T x ′ ‾ ) 2 ⇒ w T ( x ‾ − x ′ ‾ ) ( x ‾ − x ′ ‾ ) T w (1.6) \begin{aligned} (w^T\overline{x}-w^T\overline{x'})^2 \Rightarrow w^T (\overline{x}-\overline{x'})(\overline{x}-\overline{x'})^Tw \end{aligned}\tag{1.6} (wTx−wTx′)2⇒wT(x−x′)(x−x′)Tw(1.6)
如何刻画投影后相同类别的散乱程度
对于好零件来说,令 x i x_i xi表示 ( x i 1 , x i 2 , . . . , x i d ) (x_{i1},x_{i2},...,x_{id}) (xi1,xi2,...,xid),投影后的方差为:
∑ i = 1 n ( w T x i − w T x ‾ ) 2 = ∑ i = 1 n ( w T ( x i − x ‾ ) ( x i − x ‾ ) T w ) \sum_{i=1}^n(w^Tx_i-w^T\overline{x})^2=\sum_{i=1}^n(w^T(x_i-\overline{x})(x_i-\overline{x})^Tw) i=1∑n(wTxi−wTx)2=i=1∑n(wT(xi−x)(xi−x)Tw)
由于矩阵的加法与乘法满足分配率,所以上式可以变为:
w
T
(
∑
i
=
1
n
(
x
i
−
x
‾
)
(
x
i
−
x
‾
)
T
)
w
(1.7)
w^T(\sum_{i=1}^n(x_i-\overline{x})(x_i-\overline{x})^T)w \tag{1.7}
wT(i=1∑n(xi−x)(xi−x)T)w(1.7)
同理可得坏零件投影后的的方差为
w T ( ∑ i = 1 n ( x i ′ − x ′ ‾ ) ( x i ′ − x ′ ‾ ) T ) ) w (1.8) w^T(\sum_{i=1}^n(x_i'-\overline{x'})(x_i'-\overline{x'})^T))w\tag{1.8} wT(i=1∑n(xi′−x′)(xi′−x′)T))w(1.8)
将式1.7与式1.8相加得:
w T ( ∑ i = 1 n ( x i − x ‾ ) ( x i − x ‾ ) T ) ) w + w T ( ∑ i = 1 n ( x i ′ − x ′ ‾ ) ( x i ′ − x ′ ‾ ) T ) ) w = w T ( ∑ i = 1 n ( x i ′ − x ′ ‾ ) ( x i ′ − x ′ ‾ ) T + ∑ i = 1 n ( x i − x ‾ ) ( x i − x ‾ ) T ) w (1.9) \begin{aligned} &w^T(\sum_{i=1}^n(x_i-\overline{x})(x_i-\overline{x})^T))w+w^T(\sum_{i=1}^n(x_i'-\overline{x'})(x_i'-\overline{x'})^T))w\\ =&w^T(\sum_{i=1}^n(x_i'-\overline{x'})(x_i'-\overline{x'})^T+\sum_{i=1}^n(x_i-\overline{x})(x_i-\overline{x})^T)w \end{aligned}\tag{1.9} =wT(i=1∑n(xi−x)(xi−x)T))w+wT(i=1∑n(xi′−x′)(xi′−x′)T))wwT(i=1∑n(xi′−x′)(xi′−x′)T+i=1∑n(xi−x)(xi−x)T)w(1.9)
由于 ∑ i = 1 n ( x i − x ‾ ) ( x i − x ‾ ) T ) \sum_{i=1}^n(x_i-\overline{x})(x_i-\overline{x})^T) ∑i=1n(xi−x)(xi−x)T)和 ∑ i = 1 n ( x i ′ − x ′ ‾ ) ( x i ′ − x ′ ‾ ) T \sum_{i=1}^n(x_i'-\overline{x'})(x_i'-\overline{x'})^T ∑i=1n(xi′−x′)(xi′−x′)T为标量,所以式1.9取最小值时,1.7与1.8也具有最小值
如何用式1.9与式1.6刻画LDA的两个关键点
令 S b S_b Sb表示 ( x ‾ − (\overline{x}- (x− x ′ ‾ ) \overline{x'}) x′) ( x ‾ − (\overline{x}- (x− x ′ ‾ ) T \overline{x'})^T x′)T, S w S_w Sw表示 ( ∑ i = 1 n ( x i , − x ′ ‾ ) ( x i ′ − x ′ ‾ ) T + ∑ i = 1 n ( x i − x ‾ ) ( x i − x ‾ ) T ) (\sum_{i=1}^n(x_i^,-\overline{x'})(x_i'-\overline{x'})^T+\sum_{i=1}^n(x_i-\overline{x})(x_i-\overline{x})^T) (∑i=1n(xi,−x′)(xi′−x′)T+∑i=1n(xi−x)(xi−x)T),先明确一点, S b S_b Sb与 S w S_w Sw均为标量, S b S_b Sb为类间散度矩阵, S w S_w Sw为类内散度矩阵
线性判别分析具有的两个关键点为
- 1、投影后,不同类别的点尽可能远离,令式1.6最大化
- 2、投影后,相同类别的点尽可能靠近,令式1.9最小化
因此,线性判别法的最终关键点为求下列函数的最大值
J = w T S b w w T S w w J=\frac{w^TS_bw}{w^TS_ww} J=wTSwwwTSbw
此时我们已经将问题转换为函数极值问题了,这里使用拉格朗日乘子法求解,我们将分母限制为长度为1(这是用拉格朗日乘子法一个很重要的技巧),则有:
c = w T S b w − λ ( w T S w w − 1 ) = S b ( w 1 2 + w 2 2 + . . . . + w d 2 ) − λ [ S w ( w 1 2 + w 2 2 + . . . . + w d 2 ) ] + λ \begin{aligned} c&=w^TS_bw- \lambda(w^TS_ww-1)\\ &=S_b(w_1^2+w_2^2+....+w_d^2)-\lambda[S_w(w_1^2+w_2^2+....+w_d^2)]+\lambda \end{aligned} c=wTSbw−λ(wTSww−1)=Sb(w12+w22+....+wd2)−λ[Sw(w12+w22+....+wd2)]+λ
极值处的导数为0,函数 s s s对 w w w求偏导有:
∂ c ∂ w 1 = 2 w 1 S b − 2 λ w 1 S w ∂ c ∂ w 2 = 2 w 2 S b − 2 λ w 2 S w . . . . . . ∂ c ∂ w d = 2 w 1 S b − 2 λ w 1 S w \frac{\partial c}{\partial w_1}=2w_1S_b-2\lambda w_1S_w\\ \frac{\partial c}{\partial w_2}=2w_2S_b-2\lambda w_2S_w\\ ......\\ \frac{\partial c}{\partial w_d}=2w_1S_b-2\lambda w_1S_w ∂w1∂c=2w1Sb−2λw1Sw∂w2∂c=2w2Sb−2λw2Sw......∂wd∂c=2w1Sb−2λw1Sw
令上述式子等于0,则有
2
S
b
w
−
2
λ
S
w
w
=
0
⇒
S
b
w
=
λ
S
w
w
2S_bw-2\lambda S_ww=0\Rightarrow S_bw=\lambda S_ww
2Sbw−2λSww=0⇒Sbw=λSww
S
b
w
S_bw
Sbw其实为
( x ‾ − x ′ ‾ ) ( x ‾ − x ′ ‾ ) T w (\overline{x}-\overline{x'})(\overline{x}-\overline{x'})^Tw (x−x′)(x−x′)Tw
( x ‾ − (\overline{x}- (x− x ′ ‾ ) T w \overline{x'})^Tw x′)Tw为标量,我们设它为 λ w \lambda_w λw,则有
λ w ( x ‾ − x ′ ‾ ) = λ S w w ⇒ S w − 1 ( x ‾ − x ′ ‾ ) = λ λ w w \lambda_w(\overline{x}-\overline{x'})=\lambda S_ww\Rightarrow S_w^{-1}(\overline{x}-\overline{x'})=\frac{\lambda}{\lambda w}w λw(x−x′)=λSww⇒Sw−1(x−x′)=λwλw
其实 S w − 1 ( x ‾ − S_w^{-1}(\overline{x}- Sw−1(x− x ′ ‾ ) \overline{x'}) x′)就是最优解,假设 w 1 w_1 w1是最优解,则 S w − 1 ( x ‾ − S_w^{-1}(\overline{x}- Sw−1(x− x ′ ‾ ) \overline{x'}) x′)为 λ λ w w 1 \frac{\lambda}{\lambda w}w_1 λwλw1,我们把 λ λ w w 1 \frac{\lambda}{\lambda w}w_1 λwλw1代入函数 J J J,会发现参数 λ λ w \frac{\lambda}{\lambda w} λwλ被约掉了,所以 S w − 1 ( x ‾ − S_w^{-1}(\overline{x}- Sw−1(x− x ′ ‾ ) \overline{x'}) x′)就是最优解
如果您想了解更多有关深度学习、机器学习基础知识,或是java开发、大数据相关的知识,欢迎关注我们的公众号,我将在公众号上不定期更新深度学习、机器学习相关的基础知识,分享深度学习中有趣文章的阅读笔记。


















 1257
1257

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









