




我是一个临近毕业正在实训的学生,我的专业修要用到VMware、idea、pycharm等软件,其中VMware修要用到Hadoop集群,所以我写这篇文章来帮和我一样的人在VMware中安装Hadoo集群。
必要条件:VMware、xshall、xfpt三个软件,hadoop的tar包(我的是2.7.3版本)。
首先我们需要用xshall链接VMware,进入root权限(root权限很重要,如果不是root权限有很多配置更改后保存会报错;代码:su root)
用xshall打开xfpt,将Hadoop的tar包导入指定文件夹(我的是在 /opt/software;这个文件夹是自己建立的),解压缩:tar -zxvf hadoop-2.7.3.tar.gz
进入解压完的文件目录:cd /opt/software
进入hadoop配置文件目录:cd /hadoop-2.7.3/etc/hadoop
为Hadoop配置Java环境:进入配置文件 vi hadoop-env.sh
将JAVA_HOME的值修改为对应的JDK目录,我的是:
export JAVA_HOME=/opt/software/jdk1.8.0_181
修改核心配置(我的老师交给我们的配置 )
1. vi core-site.xml
将下面的配置添加到最后面的标签里
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/root/hadptmp/</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
</configuration>
2. vi hdfs-site.xml
同上
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:50090</value>
</property>
</configuration>
3.配置mapreduce
复制模板文件,并编辑
配置导入
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
4.yarn: vi yarn-site.xml
配置
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
修改从节点

添加从节点主机名

将Hadoop拷贝到从节点
scp -r hadoop-2.7.3 slave1:$PWD
scp -r hadoop-2.7.3 slave2:$PWD
配置Hadoop的环境变量(要退出hadoop文件目录)
vi /etc/profile
在末尾添加下面两行代码
export HADOOP_HOME=/opt/software/hadoop-2.7.3/
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
重新加载配置文件:source /etc/profile
启动集群
初始化:hadoop namenode -format
启动:start-all.sh
验证
输入jps(查看有关于Java的进程)
master节点出现
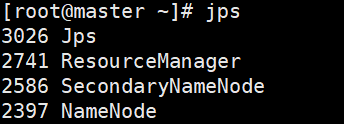
slave1节点
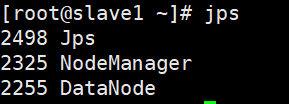
slave2节点
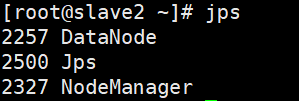
安装成功

















 2438
2438

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









