




在概率模型的应用中,一个中心任务是在给定观测(可见)数据变量X的条件下,计算潜在变量Z的后验概率分布,以及计算关于这个概率分布的期望。对于实际应用中的许多模型来说,计算后验概率分布或者计算关于这个后验概率分布的期望是不可⾏的。这可能是由于潜在空间的维度太搞,以至于无法直接计算,或者由于后验概率分布的形式特别复杂,从而期望无法得到解析解。
变分
对于普通的函数f(x),我们可以认为f是一个关于x的一个实数算子,其作用是将实数x映射到实数f(x)。那么类比这种模式,假设存在函数算子F,它是关于f(x)的函数算子,可以将f(x)映射成实数F(f(x)) 。对于f(x)我们是通过改变x来求出f(x)的极值,而在变分中这个x会被替换成一个函数y(x),我们通过改变x来改变y(x),最后使得F(y(x))求得极值。
变分:指的是泛函的变分。它最终寻求的是极值函数:它们使得泛函取得极大或极小值。比如,从A点到B点有无数条路径,每一条路径都是一个函数,这无数条路径,每一条函数(路径)的长度都是一个数,那你从这无数个路径当中选一个路径最短或者最长的,这就是求泛函的极值问题。
变分推断:
我们引入一个识别模型,它被用于逼近真实后验分布
。变分推断的目标是尽量缩小识别模型和后验分布的KL divergence,变分推断的将会得到一组


我们通过对对数边缘概率的分解得到其ELBO与KL divergence的加和的形式。
KL divergence是衡量两个函数的不相似度,当等于0时表示两个分布完全一样。P(x)不变,那么想让KL( q || p )越小,即让ELBO越大,反之亦然。因为KL≥0,所以logP(x)≥ELBO。ELBO被称为变分下界。
平均场理论, Mean field theory
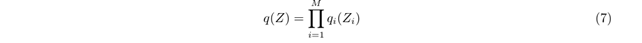
这里我们对每个 的函数形式并没有做任何限制(独立)
随后,通过 的每个因子
进行最优化来完成最大化ELBO的概率分布过程
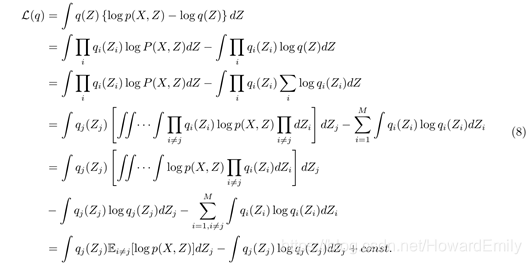
此时令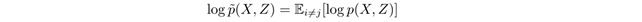
则:
于是,当我们保持所有 不变,去优化
时,可以看到此时的
就是
和
之间KL散度的负值。
当且仅当时取得最小值,即:

















 677
677

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









