




作者介绍:简历上没有一个精通的运维工程师。请点击上方的蓝色《运维小路》关注我,下面的思维导图也是预计更新的内容和当前进度(不定时更新)。
我们上一章介绍了Docker基本情况,目前在规模较大的容器集群基本都是Kubernetes,但是Kubernetes涉及的东西和概念确实是太多了,而且随着版本迭代功能在还增加,笔者有些功能也确实没用过,所以只能按照我自己的理解来讲解。
前面我们在讲解各种资源的时候部署过很多集群,但是都是单机版形式的,正在生产集群是需要高可用的,所以以下就来演示一个生产高可用集群当前最新版本Kubernetes v1.32.2,为了后续部分演示所以这里启用了3个Node节点,如果只验证高可用实际上不用Node也可以。
1.架构
| IP | 角色 | OS |
| 192.168.31.100 | Master | Rocky 9.5 |
| 192.168.31.101 | Master | Rocky 9.5 |
| 192.168.31.102 | Master | Rocky 9.5 |
| 192.168.31.111 | Node | Rocky 9.5 |
| 192.16831.112 | Node | Rocky 9.5 |
| 192.168.31.113 | Node | Rocky 9.5 |
| 192.168.31.105 | VIP | / |
这里我们使用了一个VIP来作为统一入口,避免单点风险,这个VIP实现功能要求的所有IP二层互通。
2.环境初始化
包括,修改主机名,hosts,关闭selinux,防火墙,时间同步,等基础配置参考我前面的部署文档Kubernetes(k8s)-安装k8s(docker版)。
3.安装Containerd
注:Kubernetes最后一个支持的Docker的版本是v1.23.12,后面默认就是Containerd。
wget https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo -O /etc/yum.repos.d/docker-ce.repo
yum install -y containerd.io#生成全量的配置文件,默认里面几乎没什么配置
containerd config default > /etc/containerd/config.toml
#修改镜像地址和cgroup配置
vi /etc/containerd/config.toml
sandbox_image = "registry.aliyuncs.com/google_containers/pause:3.10"
SystemdCgroup = true
#启动containerd
systemctl start containerd
systemctl enable containerd4.安装kubernetes基础软件
#从1.28开始,这里要写具体的版本,是和以前不一样的地方
vi /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes-new/core/stable/v1.32/rpm/
enabled=1
gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes-new/core/stable/v1.32/rpm/repodata/repomd.xml.key
#安装必要的软件
yum -y install kubelet kubeadm kubectl
systemctl start kubelet && systemctl enable kubelet
5.配置内核参数
#调整内核参数
echo "net.bridge.bridge-nf-call-ip6tables=1" >> /etc/sysctl.d/kubernetes.conf
echo "net.bridge.bridge-nf-call-iptables=1" >> /etc/sysctl.d/kubernetes.conf
echo "net.ipv6.conf.all.disable_ipv6=1" >> /etc/sysctl.d/kubernetes.conf
echo "net.ipv4.ip_forward=1" >> /etc/sysctl.d/kubernetes.conf
sysctl --system#添加内核模块自启动,Dcoekr版本不需要,但是Containerd需要
vi/etc/modules-load.d/k8s.conf
#添加下面的模块
br_netfilter
以上配置完成以后,所有机器都重启一次,然后检查内核模块是否正常加载,确保所有准备工作都是符合预期的。
6.配置VIP
这里我们选择100和101这2台服务器来承担vip的责任,因为3节点的集群只允许挂1台,挂2台集群是不可用的。本小节操作只在100和101服务器执行。
由于我们还没讲解这个keepalived软件,大家可以照着执行即可。
yum -y install keepalived#100服务配置vi /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id LVS_DEVEL
}
vrrp_instance VI_1 {
state MASTER # 设置为主节点
interface ens3 # 网络接口,根据实际情况修改
virtual_router_id 51 # VRRP 路由ID,主备节点必须相同
priority 100 # 优先级,主节点必须高于备份节点
advert_int 1 # VRRP通告间隔,单位秒
authentication {
auth_type PASS # 认证类型
auth_pass 1111 # 认证密码,主备节点必须相同
}
virtual_ipaddress {
192.168.31.105 # 虚拟IP地址,可以根据实际情况修改
}
}#101服务配置vi /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id LVS_DEVEL
}
vrrp_instance VI_1 {
state BACKUP # 设置为备份节点
interface ens3 # 确保使用正确的网络接口名称
virtual_router_id 51 # VRRP 路由ID,主备节点必须相同
priority 50 # 优先级,备份节点必须低于主节点
advert_int 1 # VRRP通告间隔,单位秒
authentication {
auth_type PASS # 认证类型
auth_pass 1111 # 认证密码,主备节点必须相同
}
virtual_ipaddress {
192.168.31.105 # 虚拟IP地址,与主节点相同
}
}#启动服务
systemctl start keepalived
systemctl enable keepalived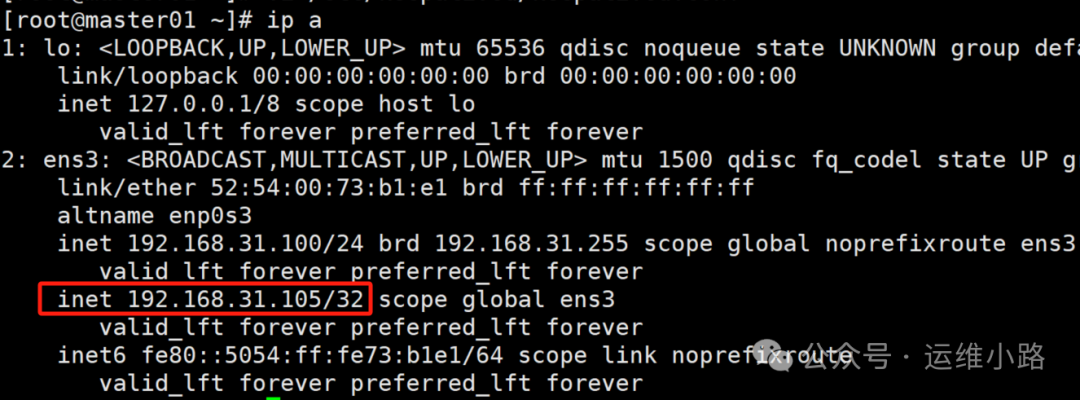
7.准备集群配置文件
因为这里需要把证书加到100年,所以只能通过配置文件形式,命令行方式不能直接实现,根据资料这个支持是从v1.31开始支持。
这里主要指定了一些临时token,并指定了容器运行时,和证书路径及VIP信息,etcd路径,和镜像下载地址,版本,默认域名,Pod和Service的IP地址段,证书包含的IP地址(也可以用域名替代,避免后面出现IP更换的问题)CA和签发证书的时间。
#vi kubeadm-config.yaml
apiVersion: kubeadm.k8s.io/v1beta4
bootstrapTokens:
- groups:
- system:bootstrappers:kubeadm:default-node-token
token: ufw2x5.c255p8a0437pxp0x
ttl: 24h0m0s
usages:
- signing
- authentication
kind: InitConfiguration
nodeRegistration:
criSocket: unix:///var/run/containerd/containerd.sock
imagePullPolicy: IfNotPresent
imagePullSerial: true
---
apiVersion: kubeadm.k8s.io/v1beta4
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controlPlaneEndpoint: 192.168.31.105:6443
controllerManager: {}
dns: {}
etcd:
local:
dataDir: /var/lib/etcd
imageRepository: registry.aliyuncs.com/google_containers
kind: ClusterConfiguration
kubernetesVersion: v1.32.2
networking:
dnsDomain: cluster.local
podSubnet: 10.20.0.0/16
serviceSubnet: 10.10.0.0/16
proxy: {}
scheduler: {}
apiServer:
certSANs:
- 192.168.31.105
- 192.168.31.100
- 192.168.31.101
- 192.168.31.102
- 127.0.0.1
caCertificateValidityPeriod: 876000h0m0s
certificateValidityPeriod: 876000h0m0s8.安装集群
kubeadm init --config=kubeadm-config.yaml --upload-certs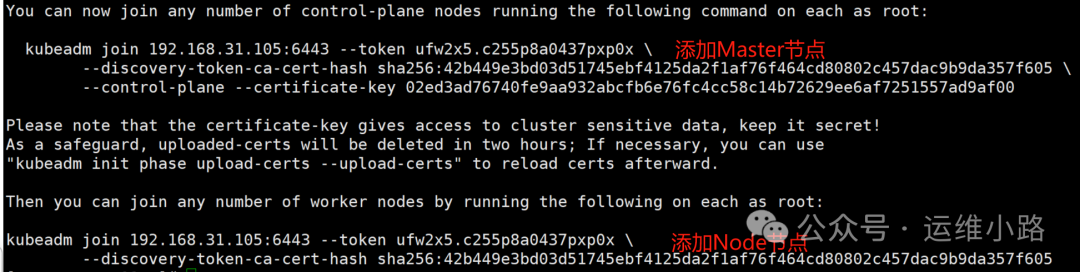
#配置kubectl,可以一台服务器,也可以所有master
mkdir -p $HOME/.kube
cp -i /etc/kubernetes/admin.conf $HOME/.kube/config9.添加网络插件
#由于我配置修改了Pod的ip地址,所以需要下下载,然后修改
wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
sed -i 's/10.244/10.20/g' kube-flannel.yml
kubectl apply -f kube-flannel.yml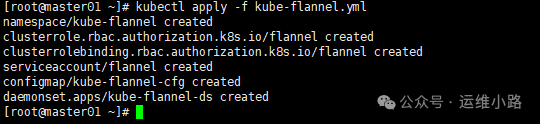
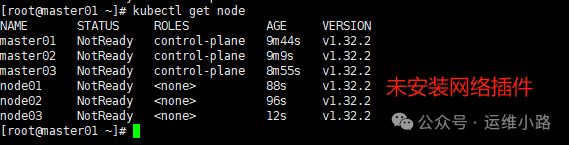
10.检查集群状态
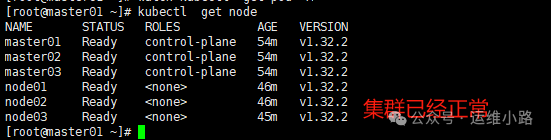
#node节点链接使用vip
cat /etc/kubernetes/kubelet.conf |grep server
server: https://192.168.31.105:644311.检查高可用&证书
这里我们关闭了master01节点,这个时候显示master01已经是NotReady,VIP也飘逸到了master02节点。并且集群也可以正常使用。
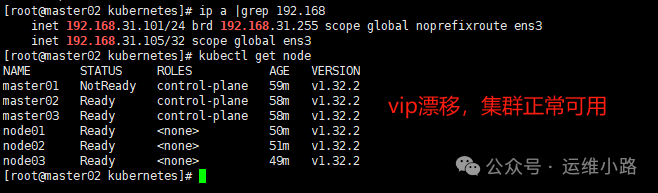
#无论是CA证书,还是CA签发的证书都是100年
kubeadm certs check-expiration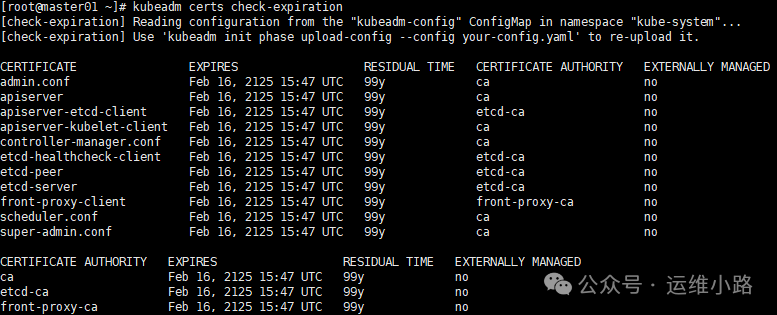
#kubelet的证书也是100年
[root@master01 ~]# openssl x509 -in /var/lib/kubelet/pki/kubelet-client-current.pem -noout -enddate
notAfter=Feb 16 15:47:21 2125 GMT运维小路
一个不会开发的运维!一个要学开发的运维!一个学不会开发的运维!欢迎大家骚扰的运维!
关注微信公众号《运维小路》获取更多内容。

















 666
666

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









