






为什么要使用消息队列?
作用1: 削峰填谷(突发大请求量问题)
case1:
- 聊天(比如 QQ ,微信): 在过年的前后的短时间内QPS差距非常大
- 过年前(23:59:59): QPS 只有1万
- 过年后(00:00:00): QPS 会超过 10 万;所有人都在疯狂的发送"新年快乐"这样的新年祝福
- 这时服务器不可能承受瞬间超过平时 10 倍的压力
这时就可以使用消息队列:
- 将消息存在消息队列中
- 按照服务能够消费的速度进行消费
- K8S的弹性伸缩,当压力太大时会自动拓展服务器,加快处理能力;当压力降低会收缩服务器降低成本(k8s 的弹性伸缩也需要时间,如果没有消息队列做削峰填谷,还没有拓展服务器服务就被打爆了)
- 当压力变小后: 将拓展的服务器杀掉,节约成本
作用2: 解耦(单一原则)
case1:
- 用户登录: 关联的功能非常多(token 颁发,消息推送,活动的推荐,计算在线时长等)
- 如果全部做在登录的api 中:登录的代码可能超过几千行,开发困难,并且难以维护.
原则是一次只做一件事
- 登录就只颁发 token
- 将登录的消息存在消息队列中
- 与登录相关的其他服务(消息推送,活动的推荐,计算在线时长等)订阅登录的消息,然后做进一步的操作
作用3: 异步(减少处理时间)
- 用户登录: 关联的功能非常多(token 颁发,消息推送,活动的推荐,计算在线时长等)
- 要自信的任务非常多,执行时间久(用户等待时间长)
使用消息队列进行异步处理
- 完成关键业务(获取 token,消息放入消息队列)就可以返回
- 服务器后台再逐渐执行其他业务(消息推送,活动的推荐,计算在线时长等),不需要等所有服务执行完成,减少用户等待时间.
如何选择消息队列(kafka&RocketMQ)
成本
按阿里云的计费标准
kafka: 标准版 60MB/s 读写; 500GB 磁盘: ¥1,189.75 /月
RocketMQ: (按每条消息 100 字节算)15000TPS 的61,710/月
两个吞吐量性能相似,价格相差 50 多倍
功能
- kafka: 提供基本的消息队列的功能(生产与消费)
具体可以查阅 kafka 官方文档或者 sdk 的 api
RocketMQ: 提供了更加丰富的功能
- 消息的种类: 提供普通消息;顺序消息,延时消息,事务消息 4 种
- 生产: 提供普通的 send 与 request 两种模式
- 消费: 提供了 push 与 pull 两种模式,同时提供消息过滤功能
具体可以查阅 RocketMQ 官方文档或者 sdk 的 api
性能
- kafka
写
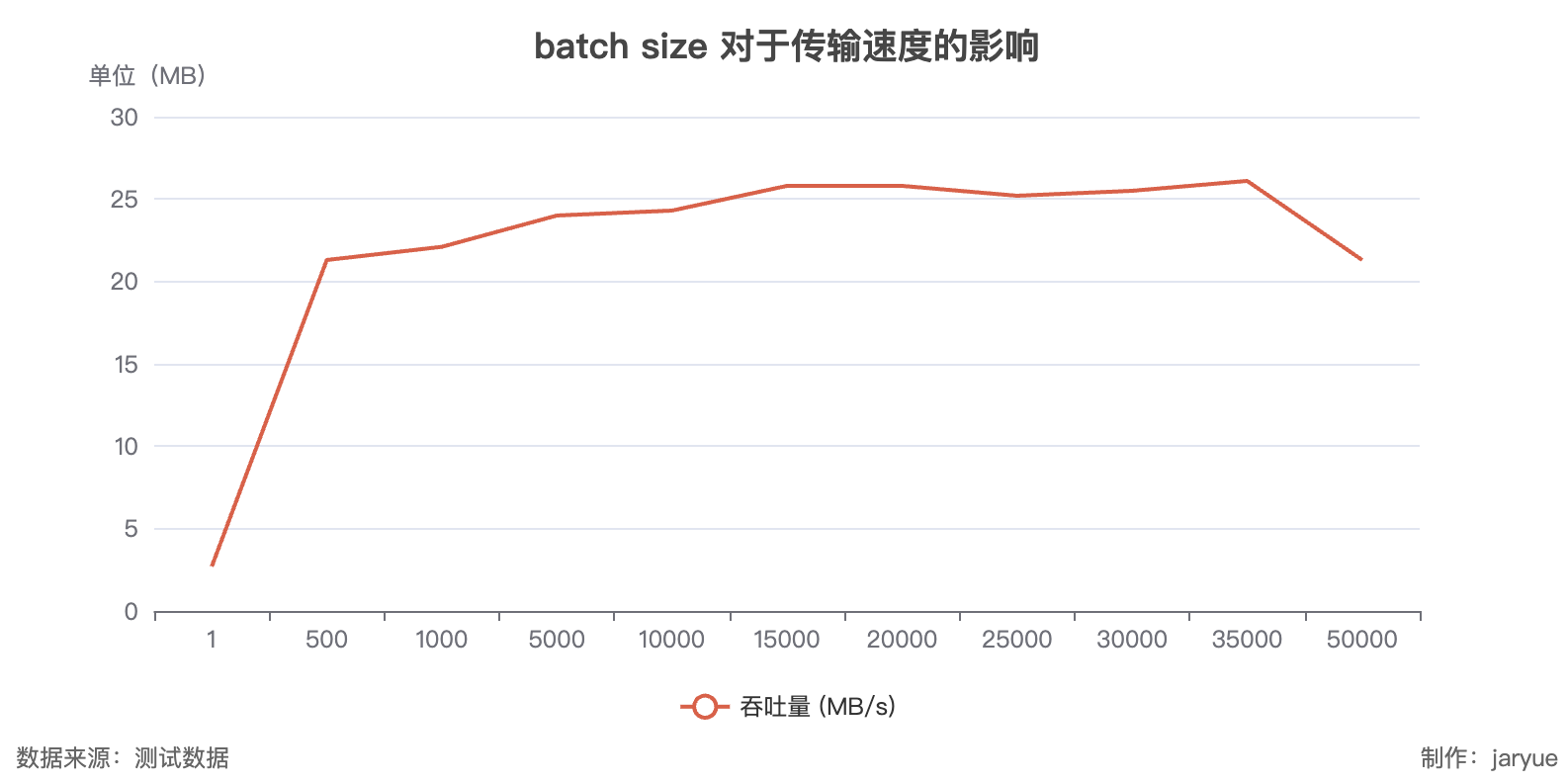
读
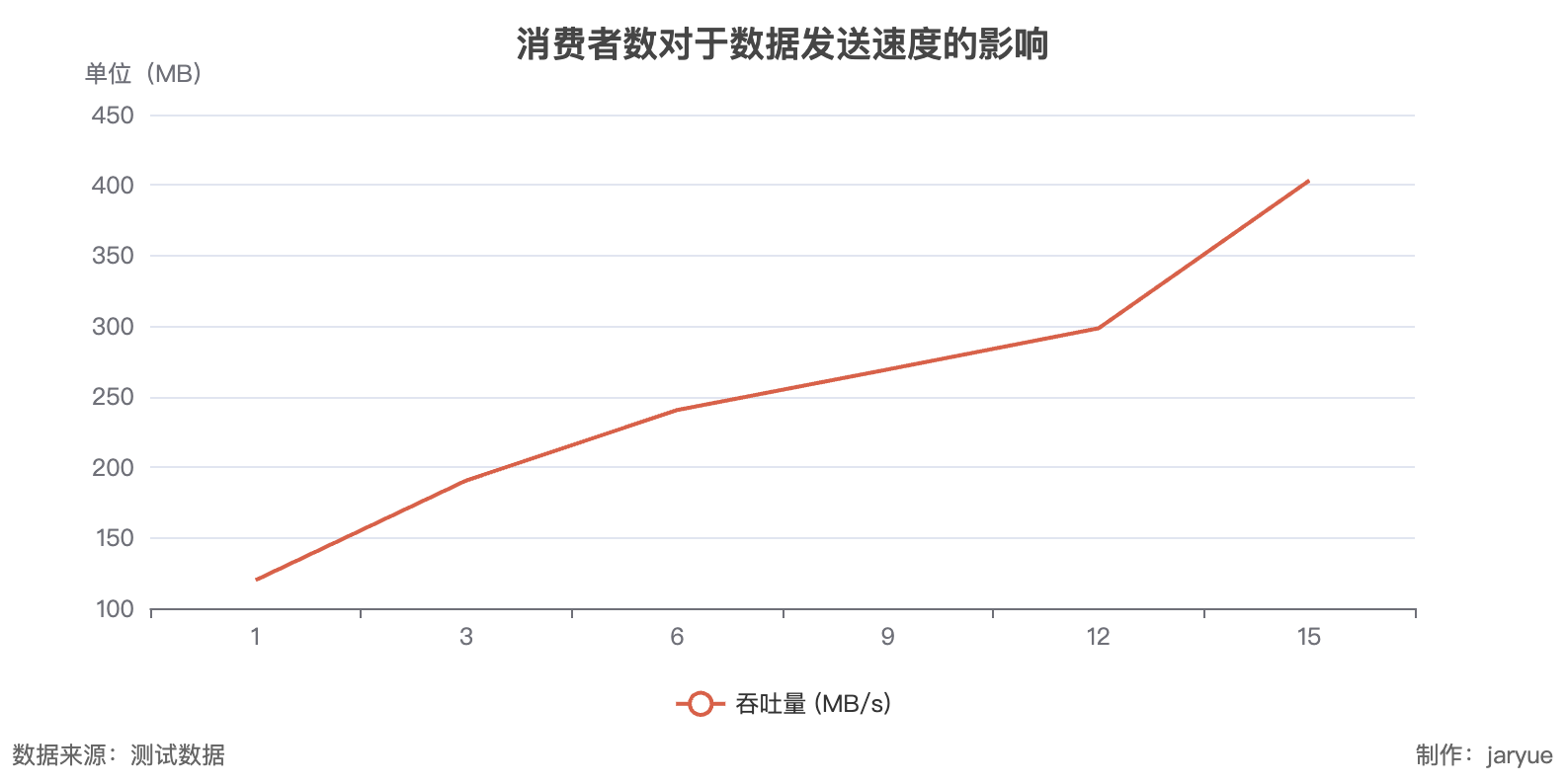
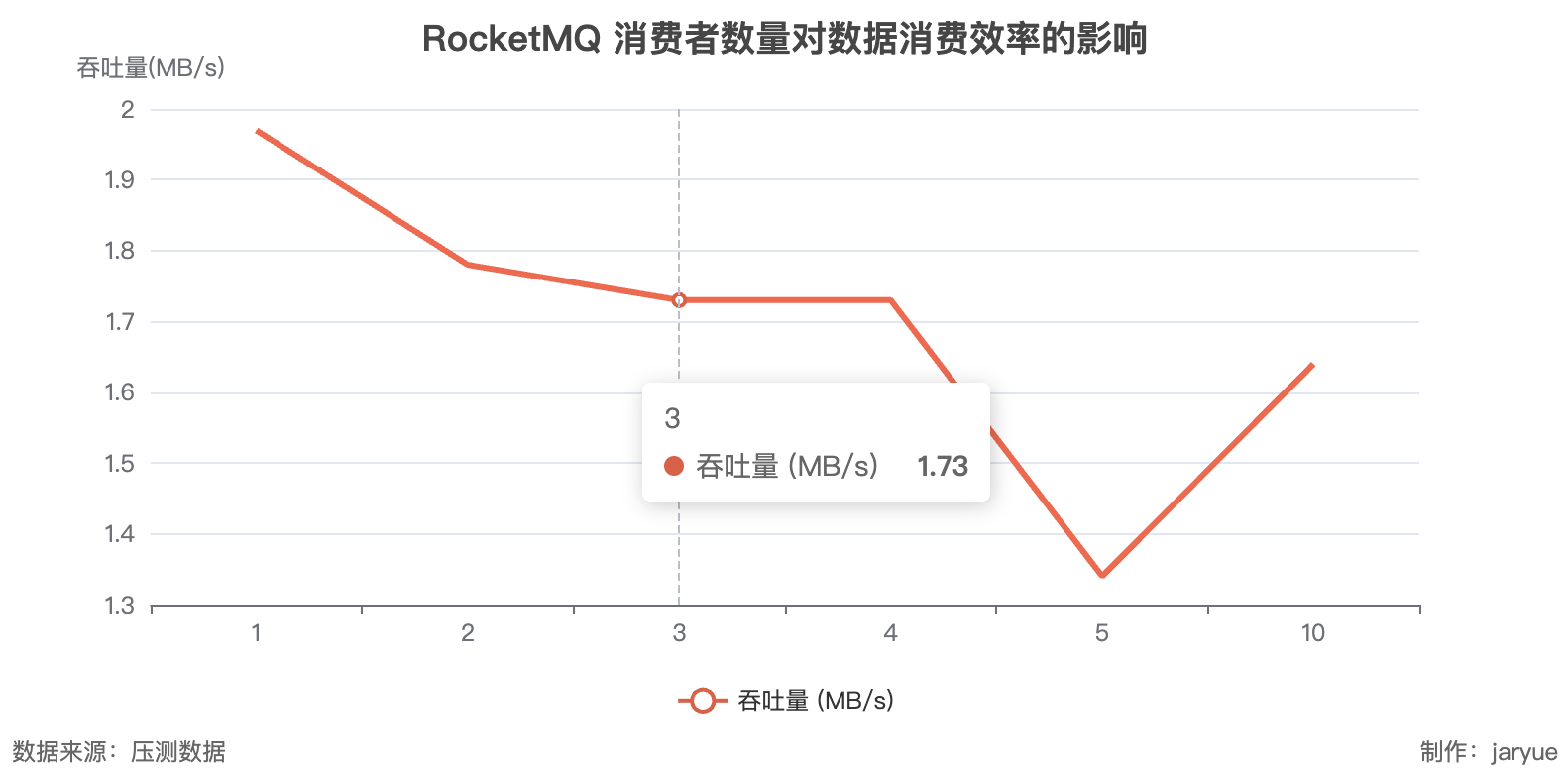
- RocketMQ
写
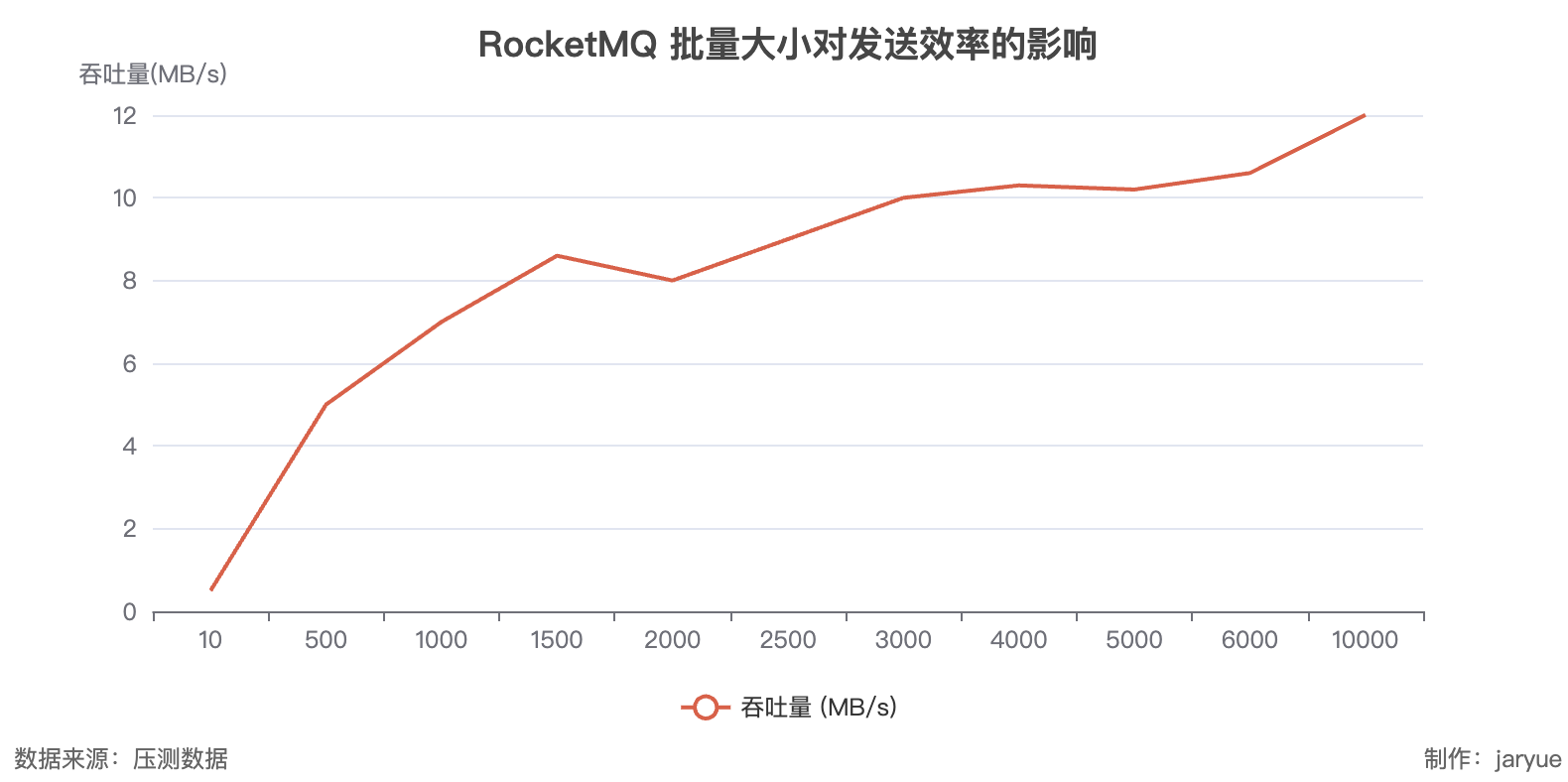
读
根据测试结果来看
kafka : 发送 25MB/s; 接收400MB/s(最高情况)
RocketMQ: 发送:12MB/s;接收 20MB/s
总结:
- kafka 可以达到 100w QPS
- RocketMQ 大概是 20w QPS
选择
- 首先考虑 kafka(普通消息传输:case IM): 成本低,性能好等诸多优势
- 如果kafka无法满足使用的功能需求(比如需要事务,或者延时发布等功能: case: 支付/订单等功能):再考虑使用 RocketMQ.
有哪些常用的配置?
生产
kafka&RocketMQ
- 最常用的就是批量(batch-size;batch-time 等)的配置: 批量大小,发送时间间隔是提升传输性能与消息延时的关键参数.
除此之外
-
RocketMQ 还提供了丰富的消息类型,可以在消息中进行配置指定类型
-
RocketMQ 提供了两种发送的还是: 一种是单向的 send;另一种是双向的 request(生产者可以收到消费者的返回)
消费
kafka&RocketMQ
MaxBytes(最大接收),MinBytes(最小接收),MaxWait(最大等待时间)等
topic
- topic 最常见的配置是分区数量(RocketMQ 中是 message queue): 它影响的是文件 IO 的效率; 一个分区相当于一个文件,IO 效率等于所有文件的 IO 效率总和
其他详情可以查看
RocketMQ 的官方文档: https://rocketmq.apache.org/zh/docs/
kafka 官方文档: https://kafka1x.apachecn.org/
坑
- 在压力测试中 RocketMQ 的读取性能并没有随着消费者数量增加而增加
具体是 RocketMQ 的内部结构的问题:
-
rocketMQ 的 message 是混合储存的,也就是所有消息都是混合储存在一个 file 中,那么读取就是一个文件的 IO 效率,在多线程消费其实并不能增加他的 IO 效率
-
而 kafka 是 message分区储存的;优势就是性能会更高(批量更好做)
其他问题
如何实现"仅一次" 的消息语义
● 生产者的"仅一次"语义实现:
a. 生产者"最少一次"语义实现:
- 发送会接收 Brocker 的 ACK 消息,如果超时或者失败就会进行重试,确保消息发送到Brocker 节点
b. 去重: 每条消息会有唯一序列号,对于重复消息进行去重(服务器内部做的)
● 消费者的"仅一次"语义的实现"
a. 消费者"最少一次"语义的实现: 获取消息->消费逻辑->提交偏移量; 如果中途失败,由其他消费者接替就会再次进行消费, 实现"最少一次"消费
b. 去重: 每条消息都使用唯一 id 记录进行去重处理,完成"仅一次"消费
参考
https://kafka.apache.org/documentation/#introduction
https://rocketmq.apache.org/zh/docs/featureBehavior/01normalmessage
https://blog.youkuaiyun.com/m0_71513446/article/details/143386962
https://rocketmq-learning.com/faq/ons-user-question-history16752/


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









