






什么是索引?
- 加快查询的一种数据结构,包含:
- 索引字段
- 数据(一般情况:主键索引就是原本的数据,二级索引就是储存主键)
你可以理解就像一本书的目录一样; 根据索引字段定位到数据的位置,从而快速拿到数据
MySQL 有哪些索引?
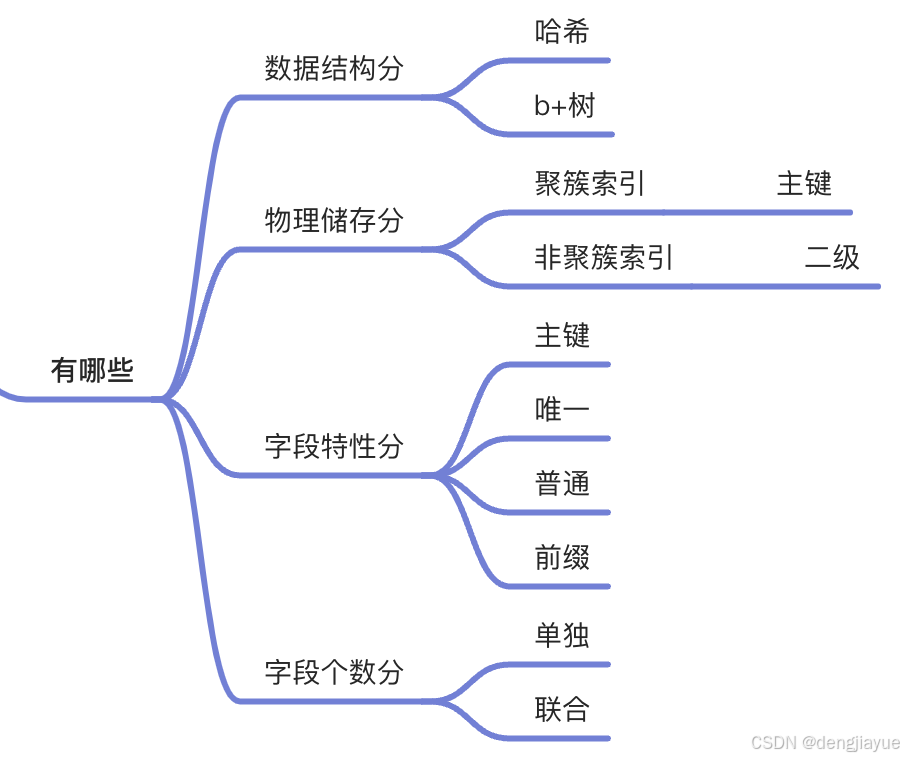
问题 1 MySQL 索引(默认)常用的数据类型是什么,为什么?
- B+树
- 查询时利于磁盘 io(一次 io16K,一个 B+树节点的数据)
- 高效的范围查询
问题 2 :为什么不使用 B 而使用 B+
- B+树分支节点可以容纳更多指向下层节点的指针,树结构层数更少,查询的 io 次数更少(B+树分支节点没有数据,数据全部在叶子节点上面,这样分支节点可以放更多指向下层节点的指针,树结构的)
- b+树有指向相邻节点的指针,更适合做范围查询
问题 3 : 为什么不使用红黑树,为什么不使用哈希,为什么不使用跳跃表?
- 红黑树: 层数太多,io 次数太多,不方便范围查询
- 跳跃表: 层数太多,io 次数太多
- 哈希: 不方便范围查询(无法范围查询)
问题 4 联合索引是如何工作的?
- 我们知道单一索引是根据索引字段进行排序(int 用大小/string 用字典)
- 我们查询的时候基本就是一个二分的逻辑
那么联合索引是如何工作的?如何使用联合索引?
联合索引遵循最左匹配原则
联合索引排序的方式:
-
按照索引的字段从左往右进行排序,先根据最左边的字段,如果相同就根据右边的字段,依次类推,如果所有字段都相同就根据主键大小排序
-
查询的时候必须条件先包含左边的字段,左边字段确定时右边的字段才能走索引
举个例子:
有一个同学的成绩表(学号(主键),语文,数学,英语)
那么如果建立一个语文,数学,英语的联合索引
那么联合索引数据的顺序应该是:
先排语文成绩,
如果语文成绩相同再排数学成绩
如果数学成绩也相同再排英语成绩
如果英语成绩也相同就根据的是学号大小排序
根据这个索引查询数据的时候,
- 必须先确定语文成绩才能使用数学成绩的索引
- 如果直接使用数学成绩是不会走索引的,因为语文成绩不同的情况下,数学成绩不是有序的
- 必须确定数学成绩,才能使用英语成绩的索引(同样的道理)
因为索引查询的底层是一个二叉搜索,如果数据不是有序的那么就不能进行二叉搜索,也就不能走索引
上面的例子哪些会走索引,哪些不会
-
where 语文=?- 会走索引查询语文成绩是多少的记录
-
where 语文=? AND 数学=?(或者 AND 数学>?)- 会走索引查询语文成绩是多少的记录
- 再根据索引再到满足数学成绩的记录
-
where 语文=? AND 数学=? AND 英语=?(或者 AND 英语>?)- 会走索引查询语文成绩是多少的记录
- 再根据索引再到满足数学成绩的记录
- 再根据数学=?的记录找到满足英语成绩的记录
-
where 数学=?- 不会走索引
-
where 英语=?(或者 数学=? AND 英语=?)- 不会走索引
-
where 语文=? OR 数学=?(或者 OR 英语=?)- 不会走索引
提示: 联合索引使用 or 条件查询索引字段是全表扫描
-
where 语文>? AND 数学=? AND 英语=?- 只会走索引查询语文成绩是多少的记录
- 后面的不能走索引,而是将所有匹配的记录进行条件筛选
解释: 因为"语文>?"会匹配到多条语文成绩记录,语文成绩不确定,后面数据记录就不是有序的,只能一个个判断
-
where 语文=? AND 数学>? AND 英语=?- 先会走索引查询语文成绩是多少的记录
- 再走索引找到"数学>?"的记录
- 最后将记录中的英语成绩进行一个个判断(英语不能走索引,因为数学没有确定(唯一),英语的数据不是有序的)
-
where 语文=? AND 英语=?- 只会走索引查询语文成绩是多少的记录
- 后面的不能走索引,而是将所有匹配的记录进行条件筛选
解释: 因为"语文=?“但是数学成绩不唯一确定,后面数据记录就不是有序的,只能一个个判断"英语=?”
问题 5 : 索引下推是什么?
MySQL 5.6 新增的优化手段
- 可以减少数据回表的次数,提升查询性能
原来是怎么做的?
上面的例子
where 语文=? AND 英语=?只能走一部分索引"语文"
5.6 前
- 将查询结果回表拿数据,判断"英语=?"
5.6 后
- 对查询结果直接判断"英语=?" (因为索引字段中包含英语的字段,我们可以判断完再回表,减少回表的次数,减少 io)
条件: 索引字段中包含查询条件(没有使用)会在索引层进行判断后再回表
问题 6 什么是覆盖索引?
- 减少回表减少 io 次数的手段
当我们查询的字段包含在索引中时,我们就不需要回表而直接返回数据
索引中有哪些字段?
- 索引字段
- 主键
当你查询走了索引,并且返回的值刚好是索引字段或者返回字段的时候就可以避免回表而直接返回数据
- 简单点来讲,就是我已经拿到我需要的东西了我干嘛还要回去呢?
还是上面的例子(语文,数学,英语)的索引
会发生覆盖索引的情况
select 语文(,数学,英语,学号(主键)) where 语文>?- 先查询到"语文>?"的数据记录
- 因为我们返回的字段(语文,数学,英语,学号)索引中都包含,返回其中的一个或者多个字段都不会回表,而是直接返回.
问题 7 :哪些情况需要创建索引,哪些情况不需要创建索引呢?
-
索引是越多越好吗?
不是- 数据的插入会涉及到 B+树的平衡问题,B+树的分裂与合并是比较复杂的过程,所以索引会降低数据的插入性能
- 一般情况下一个表的索引不会超过 5 个
-
什么时候需要索引
- 频繁的查询业务(WHERE, GROUP BY 和 ORDER BY 的字段)
-
什么时候不需要索引
- 大量重复数据(如 sex(性别),是否什么什么(0/1)的字段)
- 不(常)参与查询的字段
- 经常更新的字段不用创建索引(比如点赞数,观看数,余额)(更新索引需要重构,影响性能)
问题 8 : 如何索引优化?
- 覆盖索引
- 当我们查询的字段包含在索引中时,我们就不需要回表而直接返回数据
- 前缀索引
- 在 varchar (字符串)类型的时候指定前几个字段作为索引
- 作用,降低索引字段的长度,使得索引树层数更少,io 次数更少.
- 索引自增
- 自增 id 可以降低 B+树平衡操作的复杂度,加快数据写入的速度
- 能走索引尽量走(特别是频繁的业务),避免索引失效
问题 9 哪些情形是全表扫描?(哪些情形索引失效?)
- 查询条件字段没有索引
- 使用 OR 条件中有字段没有使用索引
- 普通的分页查询(
select * from xxx where ... LIMIT m , n;)可以使用覆盖索引/用where id>? LIMIT n代替LIMIT m , n优化 - 条件(索引)字段放在函数中
再次强调: 全表扫描性能超级低,不要全表扫描,不要全表扫描,不要全表扫描(频繁业务)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









