






问题1:bin log有全量的数据的日志,为什么不使用binlog做mysql的崩溃恢复?(为什么binlog不是crash-safe ?)
- 我们需要简单了解一下innoDB下,开启binlog事务提交是如何记录两种日志的:
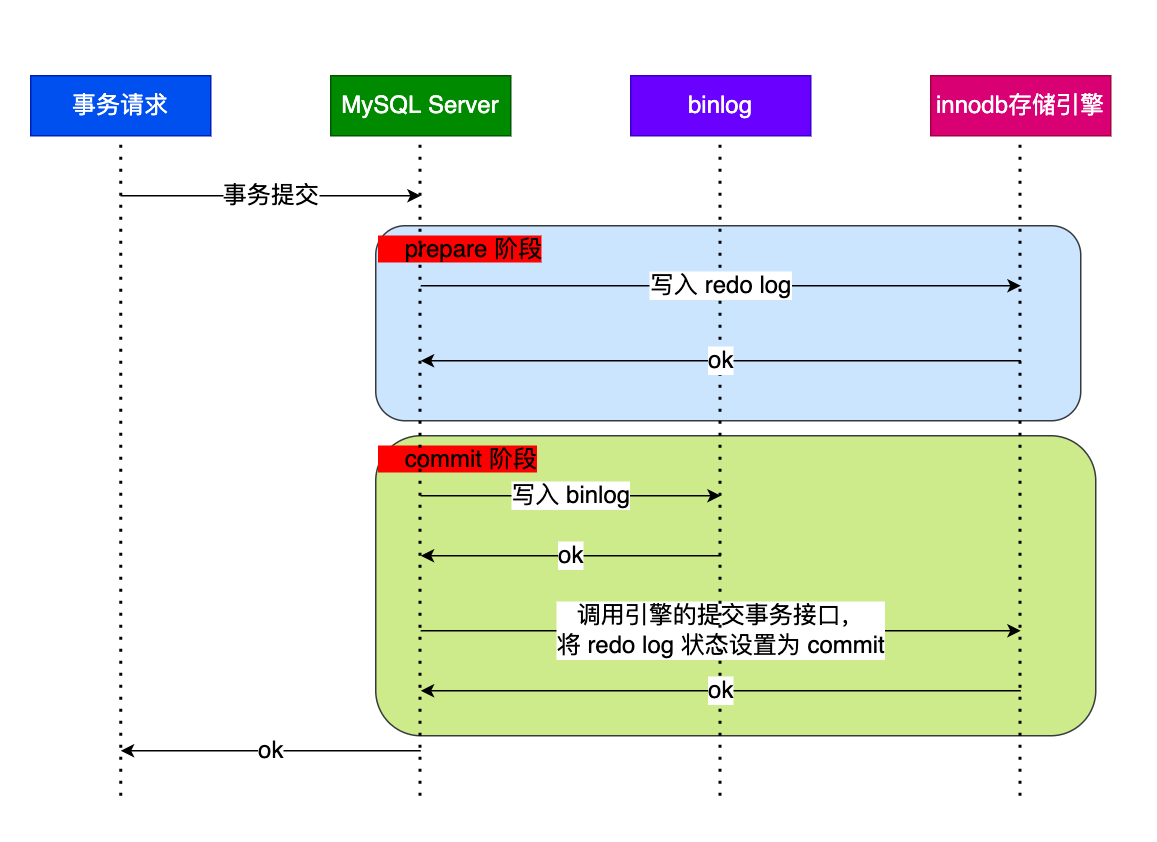
图片来源:小林 coding
简单来讲:两种日志的数据必须是一致的(短期),不然就会出现主从数据库数据不一致的情况.
然后就有一堆问题:
既然两种日志的数据是一致的为什么不直接使用 binlog 做崩溃的恢复?为什么还要定义一个 redolog 去浪费空间?为什么 binlog 不是 crash-safe 的?
这里就要聊到 redolog 与 binlog 的区别
redolog 与 binlog 的区别
- 大小
redo log:固定大小,写满了会不断覆盖之前的记录,只保留最新的一些数据
bin log:无限大小,不断追加
这个说明了他们的定位: redolog 专门用于做崩溃恢复的,只保留了近期的数据; binlog 是做全量数据的备份的
- bin log 无法判断哪些数据已经落盘了,哪些没有落盘;redolog 有这些特性可以进行判断
binlog要恢复就只能全部重新刷一遍非常浪费时间,如果要支持这个功能,就要对 binlog 进行进一步的封装,将其变成一个 redolog 类似的东西,但是 bin log是 server 层的日志mysql 的其他引擎也要使用,所以不好随便动.
而 redolog 是innoDB 特定的日志.
总结
mysql 对于写操作不会立即落盘,而是先储存到缓冲区,在选合适的时机落盘
为什么不使用 binlog 做崩溃的恢复,主要是因为 binlog 无法判断哪些数据已经落盘,哪些数据还没有落盘,这样要恢复只能全部重新加载,消耗太大.
redo主要应对的就是服务崩溃的快速恢复,所以只需要保存近期的数据就可以了,所以 redolog 文件的大小是有限的.


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









