






TCTS: A Task-Consistent Two-stage Framework for Person Search
CVPR 2020
Problem
1.现有的two-stage方法并没有注意到检测和重识别之间的consistency(一致性?连续性?)要求。
2.往常检测器生成的gallery规模太大,不利于reid的任务
4.reid中的输入是检测框,往往存在着遮挡、错位、部位消失等。

Motivation
从两个模型的连续性(一致性)出发,在检测中,query的信息往往被忽略掉(是query中的背景信息造成的漏检,错检?),文章考虑query和proposal的相似度,还有query的前景信息,减少相似度小的proposal,生成和query相似的框,从而帮助reid模块。
同样,以往训练的时候用的是GT,在测试的时候用的是检测的结果,之间会有差异,为了提高模型的适应性,可以在训练的时候混合了检测的bbox,提高精度。
Contribution
1.提出IDGQ检测器和DRA重识别模型
2.在IDGQ中,学习一个辅助识别身份的分支,计算query和proposal的相似度。并根据分数为reid生成类似query的bbox。
2.在DRA中,构建一个混合的训练集,提高模型鲁棒性。
Method
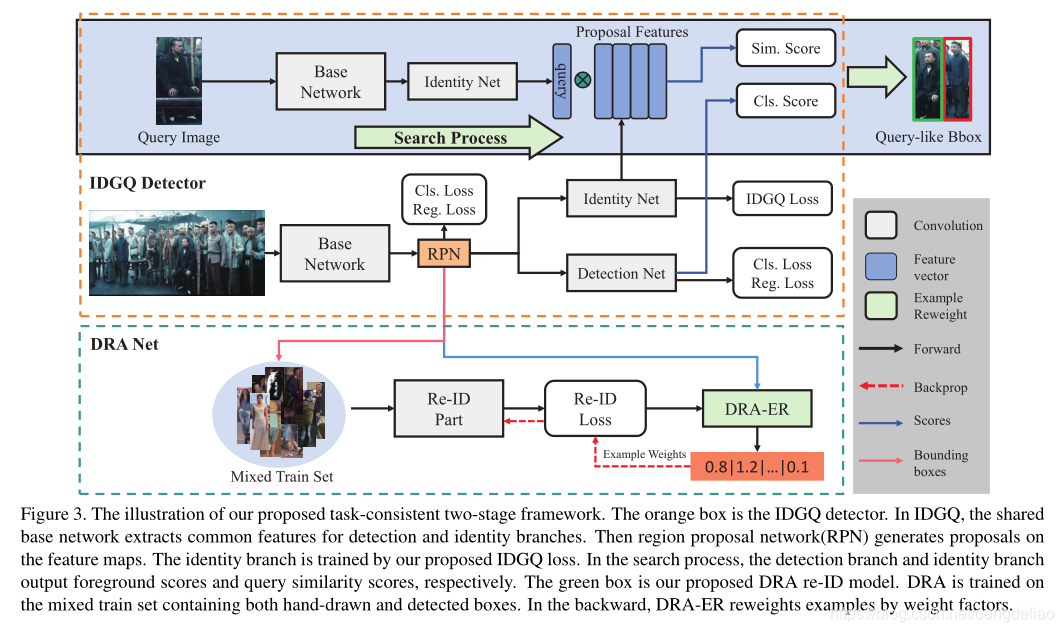
检测
在IDGQ检测器中增加一个识别身份的分支,用文章的IDGQ的loss训练,输出与query与相似度,检测分支输出前景分数,保留两分数高的proposal。
替换传统loss的原因:未标签的例子没有被充分利用,如果是OIM的话,人工设置循环队列的长度会变得局限。
re-id
将未有标签的框去除,同时训练集该包括了一些困难样本,比如错位的bbox和有干扰的bbox。因为这些不同的框所带来的的影响不一样,文章为训练图片设计了一种权重算法。
给一些易检测的bbox:

给一些干扰的bbox:
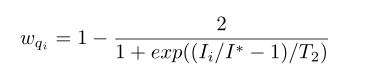
最后赋值以保持稳定的学习率:
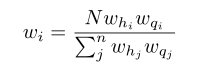
疑问:
在检测分支中加入识别网络,那不就和search的工作相似了,这样做不会冲突吗?


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









