







目录
一、数据库和数据仓库
1、数据库:OLTP(on-line transcation processing),注重:响应实时,可靠性(事务)。遵循3范式。主要有mysql,oracle等
2、数据仓库:OLAP(online analyze procss)。注重:分析和整合分析决策。通常反范式设计,以空间换时间。主要有hive。
数据仓库的目标是实现集成、稳定、反映历史变化有组织有结构的面向主题的存储数据的集合。
汇总所以的数据,为各个部门提供统一的规范的数据出口
特征:
- 面向主题:汇总所以的数据,针对某个主题
- 集成性:数据口径一致性(数据字典解释一致,比如男女、M/F)
- 稳定的:不会删除和更新,只会增加
- 变化的:历史版本也会保存
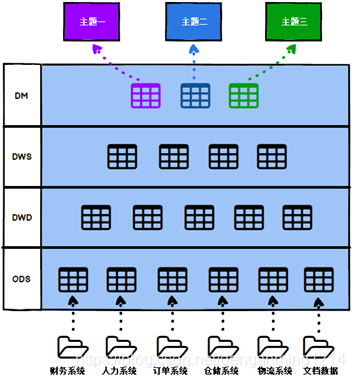
二、数仓的分层
大致可以分为4层,企业可根据实际情况调整层次。
- ODS(Operational Data Store)操作数据存储层。保存的是原始业务数据库/行为数据,数据结构和数据库保持一致,通常遵循第三范式,采用ER建模
- DWD(Data Warehouse Detail)数据明细层。对ODS层数据进行数据清洗、脱敏、规范化、整合,把脏数据、垃圾数据、规范不一致的、状态定义不一致的、命名不规范的数据处理掉。大多数是维度建模,可分为事实表和维度表,事实表通常会简单的宽化(维度退化)
- DWS(Data Warehouse service)服务数据层/公共汇总层。对DWD的数据进行轻度汇总,周期粒度包括日、周、历史等。采用维度建模,这边事实表会建更大的宽表减少join的使用。能够满足80%的指标需求。
- DM(Data market)数据集市层。面向特定的主题(通常通过部门或者业务切分),做汇总报表和指标的统计信息;使用维度建模
三、数据仓库技术架构
总体架构:
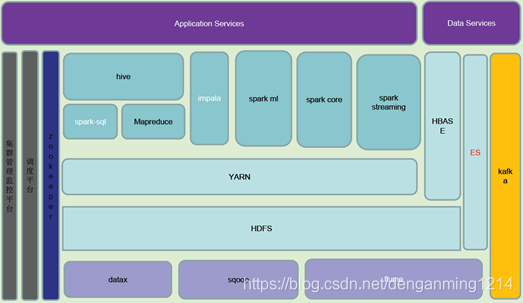
3.1.数据采集
数据源主要包括:
- 业务数据:如订单数据,用户数据。
- 行为数据:如用户访问记录,停留页面时间等。
- 其他文件数据:第三方的文件数据等。
3.1.1 业务数据
业务数据通常在RDB中,通过RDB–>同步工具–>数据仓库的方式。
同步工具有:datax,sqoop,kettle。
- datax:有reader writer的json配置
优点:支持的数据源广泛,流量控制
缺点:单节点运作,无页面操作 - Sqoop:采用Sqoop1的方式
优点:基于map的分布式同步
缺点:RDBMS->HDFS、HDFS->RDBMS 类型支持的少,但是够用了 - kettle
优点:可视化界面,易操作
缺点:分布式的吗(待确认)
3.1.1 行为数据
行为数据通常在log中或需要埋点。通过客服端/服务端埋点–>log日志–>采集工具–>数据通道–>数据仓库
采集日志工具有:flume、logstash 都很占资源。
行为埋点:
使用CID和UID做匹配,只有在重新登录、重新注册的时候才会切换cid;通过uid打通不同设备
有app埋点和服务端埋点;属性分为共有属性和私有属性
3.1.1 其他文件数据
通过scp,ftp或者文件上传、kettle同步解析离线同步到数据仓库。
3.2.数据通道
使用kafka,能够起到解耦、消峰的作用。单节点吞吐量很高。且数据不会丢失。
3.3.数据存储
- hive 高延迟。适合离线。有行数存储和列式存储。列式存储能够有更高的压缩比,针对少量列查询有更好的新能,通常采用parquet列出存储,配合使用Snappy压缩
- hbase 低延迟 列式存储 通常用于实时计算
3.4.计算引擎
MR < sparkCore < sparksql
我们采用的hive on spark,sparkcore
3.5.系统调度
- Oozie:重量级,功能全面,基于xml配置,通常封装封装web页面;监控hive等 依赖hive等的版本
- Azkaban:轻量级
四、数据仓库建模理论
建模的理论:数据仓库建模的目标是通过建模的方法更好的组织、存储数据,以便在性能、成本、效率和数据质量之间找到最佳平衡点。
4.1.数据库3范式
为了减少数据冗余,尽量让每个数据只出现一次,保证数据一致性;获取数据时通过 join 拼接出最后的数据
4.1.1 函数依赖概念
- 函数依赖:若x确定则y也确定,则称y函数依赖于x
- 完全函数依赖:若y函数依赖于x,且y不函数依赖于x的真子集,则y完全函数依赖于x
- 部分函数依赖:若y函数依赖于x,但y不完全函数依赖于x,则y部分函数依赖于x
- 传递函数依赖:若z函数依赖于y,且y函数依赖于x,则z传递函数依赖于x
4.1.2 3范式
- 1NF:数据表中的字段不能再切割了,是原子的;若不符合,则把表示多个含义的一个字段拆分成多个字段
- 2NF:在1NF基础上,字段都完全函数依赖于主键,没有部分函数依赖的关系;若不符合,则把部分函数依赖的关系拆分出来,单独一张表
- 3NF:在2NF的基础上,字段都完全依赖于主键,不能有传递依赖的关系;若不符合,则把传递依赖关系拆分出来,单独一张表
4.2.ER建模
ER:entity-relation 实体-关系-属性,主要面对OLTP
- 实体:客观存在的主体 使用矩形表示
- 属性:对主体的描述、修饰 使用椭圆形表示
- 关系:实体或实体的物理事件 使用菱形表示
对照关系:实体和实体或者实体和关系之间的对账关系,1对1,m对n。
举例:学生选课;实体:学生,课程;关系:选课
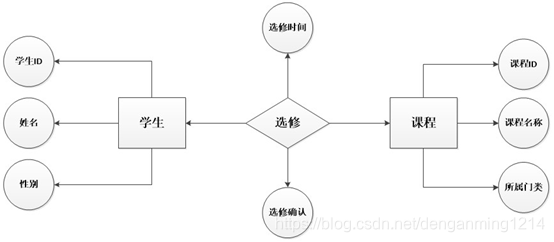
此建模不适合数据仓库建模,实体太多,需要分析所以的实体和之间的关系,大系统比较复杂,难以分析。
4.3.维度建模
分为维度表和事实表,主要面向分析OLAP 。
4.3.1 事实表
在现实世界中,每一个操作型事件,基本都是发生在实体之间的,伴随着这种操作事件的发生,会产生可度量的值,而这个过程就产生了一个事实表,存储了每一个可度量的事件。
用来存储事实的度量(measure)及指向各个维的外键值;维度表主键、度量数据、事件描述信息
举例:下单
订单表:(维度表主键)时间外建,用户外建,商品外键,(度量数据)下单数量、价格、(事件描述信息)状态、付款时间
4.3.2 维度表
每个维度表都包含单一的主键列。维度表的主键可以作为与之关联的任何事实表的外键,当然,维度表行的描述环境应与事实表行完全对应。通常为实体
用来保存该维的元数据,即维的描述信息,包括维的层次及成员类别等;
举例:下单
用户表,商品表,时间区域信息
4.3.3 举例
具体实例:
1.背景
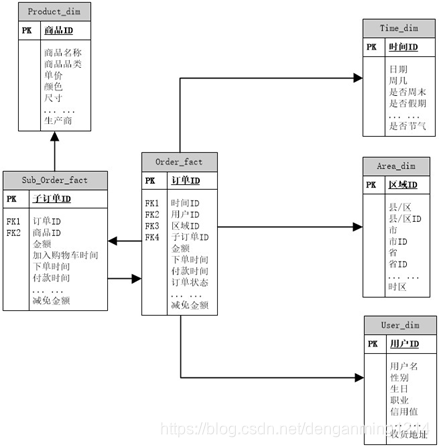
某电商平台,经常需要对订单进行分析,以某宝的购物订单为例,以维度建模的方式设计该模型。
2.事实表与维度表的划分
事实表为订单表、子订单表,维度包括商品维度、用户维度、商家维度、区域维度、时间维度。
3.事实表分析
订单中包含的度量:商品件数、总金额、总减免金额; 描述性属性:下单时间、付款时间、订单状态等;
子订单包含度量:商品ID、单价、减免金额;描述性属性:加入购物车时间、下单时间、付款时间、状态;
4.维度表分析
商品维度:商品 ID、商品名称、商品品类、单价、颜色、尺寸、生产商等;
用户维度:用户 ID、姓名、性别、生日、职业、信用值、收货地址等;
时间维度:日期 ID、日期、周几、是否周末、是否假期等;
区域维度:区域 ID,县/区、县/区 ID、市、市 ID、省、省 ID;
我们往往会避免事实表之间产生关系;子订单中会冗余主订单的用户id,区域id,时间id
4.3.4 星型模型和雪花模型
- 星型模型:一个事实表关联多个维度表,一个维度表扁平的设计,反范式 减少join,减少MR
- 雪花模型:一个事实表关联多个维度表,维度表也会关联其他维度表,符合3范式设计
- 星座模型:多个事实表共用了维度表,组成了大的星座模型
模型的选择:尽量选择星型模型,用空间换时间,通常我们的系统里面都是星座模型
建模的方式:
1、完全按照维度标准建模
2、将常用字段做事实表,不常用作为维度表
3、维度退化(降维):上面2个相结合,将维度表中经常使用的字段放到事实表中
五、维度建模方法
5.1.同步数据策略
全量同步:
适合数据量小的,如果关注状态变更(行的属性值有变动,如果订单状态),一天一个分区;
增量同步:
针对表数据量比较大的,以ID/CreateTime或者updateTime为标记同步
- 无状态:每天同步增量数据,已ID/CreateTime作为每天同步的切割标志。
- 有状态:需要关注状态变化的。抽取昨天有更新的表记录,和前天的全量数据,做拉链表,通过starttime和endTime做分割
5.1.维度表设计
1、代理键:代理键是由数据仓库处理过程中产生的、与业务本身无关的、唯一标识维度表中一条记录并充当维度表主键的列,也是描述维度表与事实表关系的纽带。可以是业务主键,也可以是专门的代理键;在合并多种维度出现相同业务id或拉链表时使用
2、稳定维度:属性不会变化的维表;时间维度、区域维度;全量同步/增量
3、缓慢渐变维:维度属性会随着时间发生变化,变化速度比较缓慢,这种维度数据通常称作缓慢渐变维;比如用户维度:修改用户收件地址、用户昵称等
- 每天全量快照:适合数据量小的
- 增加历史值的字段,一般不使用
- 采用拉链表:一个原始记录再拉链表中有多条记录,通过startTIme和endtime来区分,这样原始业务id会重复,需要增加额外的代理主键;事实表中存代理键,在事实表新增数据时,需要通过原来的主键,通过time取到代理主键
5.2.事实表设计
增量同步
- 无状态:增量
- 有状态且需要记录:拉链表
全量快照
5.2.1 明细事实表
来自dwd层,优化说明
1、数据降维:将维度表中的常用字段放到事实表中
2、独立维度的选择:维度之间可以合并,把不是重点关注的维度合并到其他维度:滴滴下单。用户信息、司机信息、汽车信息。汽车维度可以合并到司机信息里面
3、事实表中不一定有度量信息,比如信息审核表,没有度量信息
设计方案
1、单事件事实表:每个事件一个表
2、流程事件表:一个流程一个表,可能包括多个事件
举例:滴滴打车:单事件:下单 接单 跑单 支付 评价
单事件:
优点:接近于无状态事实表,流程清晰,更方便跟踪业务流程细节数据,针对特殊的业务分析场景比较方便和灵活,数据处理上也更加灵活;
缺点:想要分析整个行为不够直观,join太多
流程事实表:
优点:很直观看到结果,适合大多数应用场景,比较少的join
缺点: 缺失细节,特殊场景的分析不够灵活
可结合2中设计,一般都有。
5.2.2 聚合事实表
来自dws,做初步聚合,以下聚合方式
- 日粒度:一天中的统计信息:一天的下单数
- 周期性累积(周,月,年):周期统计
- 历史累积(累计订单量、累计金额):用户表:累计支付多少 累计下单
- 公共聚合:需满足80%的指标;比如订单维度所有订单统计信息;用户维度:用户的下单笔数 评价笔数
聚合的数据分为可累加事实和不可累加事实
可累加:订单数 金额
不可累加:率;拆分存储,分为分子和分母
六、规范设计
6.1 表命名规范
层次_数据域_修饰/描述_范围/周期
| 数仓层次 | 数据域 | 数据域周期/数据范围 | |||
|---|---|---|---|---|---|
| 共用维度 | dim | 订单 | ord | 日快照 | d |
| 集市 | dm | 用户 | user | 增量 | i |
| ODS | o | 财务 | finc | 周 | w |
| DWD | s | 账单 | bill | 拉链表 | l |
| DWS | s | 库存 | sto | 非分区全量表 | a |

















 644
644

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









