






 本文介绍了一种基于MRC框架的命名实体识别解决方案,该方案能统一处理flatNER和nestedNER任务,通过将NER问题转化为MRC问题,利用自然语言问题抽取实体,实现在小规模数据集和迁移学习场景下的优异表现。
本文介绍了一种基于MRC框架的命名实体识别解决方案,该方案能统一处理flatNER和nestedNER任务,通过将NER问题转化为MRC问题,利用自然语言问题抽取实体,实现在小规模数据集和迁移学习场景下的优异表现。
- 论文名称:A Unified MRC Framwork for Name Entity Recognition
- 论文链接:https://arxiv.org/abs/1910.11476
- 论文源码:https://github.com/ShannonAI/mrc-for-flat-nested-ner
1. 概述
1.1 命名实体识别的现状
命名实体识别(NER)任务按照实体是否“嵌套(nested)”分为flat NER(非嵌套型)和nested NER(嵌套型)。如下图所示:
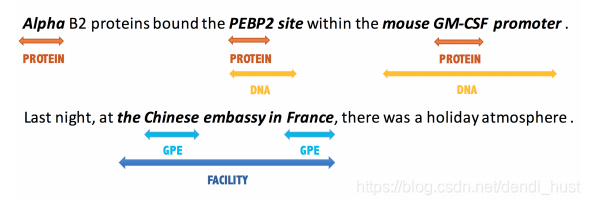
其中,flat NER经常按照序列标注的方式去解决;nested NER则是通过构建pipeline的方式解决(如:先识别出实体,再对识别出的实体进行分类),此外,pipelined systems还有错误传递、运行时间长、需要很多人工特征等缺点。
1.2 论文的贡献
- 提出一种基于MRC(Machine Reading Comprehension)框架的解决方案,可以统一处理
flat NER和nested NER任务; - 基于MRC的解决方案可以让问题编码一些先验知识,在小规模数据集下、迁移学习下的表现更好;
- 在8中数据集下达到了SOTA;
2. 模型设计
2.1 NER任务
给定一个句子X={x1,x2,...,xn}X=\lbrace x_1,x_2,...,x_n \rbraceX={x1,x2,...,xn},其中xnx_nxn是句子中的字符,n是句子的长度。实体识别就是找出句子XXX中的所有实体,并给所有实体赋予一个标签y∈Yy \in Yy∈Y(其中YYY是预先定义好的标签类型,如:PER,LOC等)。
2.2 MRC任务
给定上下文CCC和问题QQQ,其中C={c1,c2,...,cn}C=\lbrace c_1,c_2, ...,c_n \rbraceC={c1,c2,...,cn},MRC(片段抽取型)任务要求模型从CCC中抽取连续的子串a={ci,ci+1,...,ci+k}a=\lbrace c_i,c_{i+1},...,c_{i+k} \rbracea={ci,ci+1,...,ci+k}其中(1≤i≤i+k≤n)(1\leq i \leq i+k \leq n)(1≤i≤i+k≤n)。
2.3 基于MRC框架的NER解决方案
将NER任务转换为MRC任务,如:抽取句子中PER(PERSON)实体的NER任务,可以转换为回答问题which person is mentioned in the text的MRC任务。此种方式天然适配falt NER和nested NER任务。(当需要抽取不同类别的重叠实体时,只需要回答两个独立的问即可)。
2.4 数据构建
将NER dataset转换为(QUESTION, ANSWER, CONTEXT)的形式。
- 为每个tag(标签)y∈Yy \in Yy∈Y分配一个自然语言形式的问题qy=q1,q2,...,qmq_y={q_1,q_2,...,q_m}qy=q1,q2,...,qm,其中mmm是问题(query)的长度;
- 对于实体xstart,end={xstart,xstart+1,...,xend−1,xend}x_{start, end}=\lbrace x_{start}, x_{start + 1}, ..., x_{end-1}, x_{end} \rbracexstart,end={xstart,xstart+1,...,xend−1,xend}是句子XXX的子串,满足start≤endstart \leq endstart≤end,每个实体都有一个label(y∈Yy \in Yy∈Y);
- 三元组(qy,xstart,end,X)(q_y, x_{start,end},X)(qy,xstart,end,X)对应三元组
(QUESTION,ANSWER,CONTENXT);
2.5 question的构建
question的构建方式非常重要,因为question会将label的先验知识编码进去,并对最终的模型效果有显著的影响。论文使用标注指南作为question(标注指南是构造NER数据集时提供给标注者的简短的标注说明,如下图所示),后文会分析不同的question构建方式对模型效果的影响。

2.6 模型细节
2.6.1 Model Backbone
将question qyq_yqy和句子 XXX拼接成 {[CLS],q1,q2,...,qm,[SEP],x1,x2,...,xn}\lbrace [CLS], q_1,q_2,...,q_m,[SEP],x_1,x_2,...,x_n \rbrace{[CLS],q1,q2,...,qm,[SEP],x1,x2,...,xn}的形式,输入BERT进行特征提取,得到特征矩阵E∈Rn×dE \in R^{n \times d}E∈Rn×d,其中nnn为句子长度,ddd为BERT最后一层提取的特征矩阵的向量维度。
2.6.2 Span Selection
MRC抽取答案的方法是预测答案的开始位置和结束位置,有两种方案:
- 设计
2个n-classes分类器(n为句子长度),分别预测答案的开始位置和结束位置。这种方案在给定一个context和一个question时只能得到一个答案,无法处理句子中存有多个实体的问题,更不能解决实体嵌套的问题; - 设计
2个2分类器,其中一个分类器负责预测每个字符是否是实体开始位置,另一个分类器负责预测每个字符是否是实体的结束位置。这种方案在给定一个context和一个question时支持多个实体开始位置和多个实体结束位置,因此有能力根据qyq_yqy抽取出所有相关的实体。模型采用的是本方案。
Start Index Prediction
Pstart=softmaxeach row(E⋅Tstart)∈Rn×2
P_{start}=softmax_{each \space row}(E \cdot T_{start}) \in R^{n \times 2}
Pstart=softmaxeach row(E⋅Tstart)∈Rn×2
其中:
- Tstart∈Rn×2T_{start} \in R^{n\times 2}Tstart∈Rn×2是需要学习的参数;
- PstartP_{start}Pstart每一行构成一个
是或不是实体开始位置的概率分布;
End Index Prediction
Pend=softmaxeach row(E⋅Tend)∈Rn×2
P_{end}=softmax_{each \space row}(E \cdot T_{end}) \in R^{n \times 2}
Pend=softmaxeach row(E⋅Tend)∈Rn×2
其中:
- Tend∈Rn×2T_{end} \in R^{n\times 2}Tend∈Rn×2是需要学习的参数;
- PendP_{end}Pend每一行构成一个
是或不是实体结束位置的概率分布;
Start-End Matching
在句子XXX中,同一个类型下存在多个实体,这就意味着存在多个start-index和多个end-index,因此需要一个二分类器去匹配start-index和end-index。
Pistart,jend=sigmoid(m⋅concat(Eistart,Ejend))
P_{i_{start},j_{end}}=sigmoid(m \cdot concat(E_{i_{start}},E_{j_{end}}))
Pistart,jend=sigmoid(m⋅concat(Eistart,Ejend))
其中:
- m∈R1×2dm \in R^{1 \times 2d}m∈R1×2d是需要学习的参数。
2.7 Train & Test
2.7.1 Train阶段
训练阶段有三个损失函数:
start index model损失函数:ζstart=CE(Pstart,Ystart)\zeta_{start}=CE(P_{start},Y_{start})ζstart=CE(Pstart,Ystart);end index model损失函数:ζend=CE(Pend,yend)\zeta_{end}=CE(P_{end},y_{end})ζend=CE(Pend,yend);match model损失函数:ζspan=CE(Pstart,end,Ystart,end)\zeta_{span}=CE(P_{start,end},Y_{start,end})ζspan=CE(Pstart,end,Ystart,end);
故Train的损失函数为:ζ=αζstart+βζend+γζspan\zeta=\alpha \zeta_{start}+\beta \zeta_{end}+\gamma \zeta_{span}ζ=αζstart+βζend+γζspan,其中α,β,γ∈[0,1]\alpha,\beta,\gamma \in [0,1]α,β,γ∈[0,1],是超参。
2.7.2 Test阶段
- 使用
start index model预测实体的start-index; - 使用
end index model预测实体的end-index; - 使用
match model对start-index和end-index进行匹配,当Pspan(istart,iend)>0.5P_{span}(i_{start},i_{end}) >0.5Pspan(istart,iend)>0.5时,模型判定x(i:j)是实体,否则不是。
3. 效果
3.1 Nested NER效果
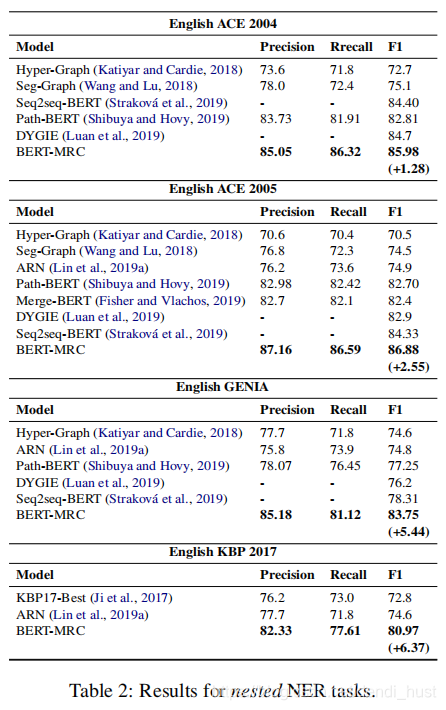
由上表可知,MRC的方法在nested NER所有数据集上的表现更加显著。
3.2 Flat NER效果
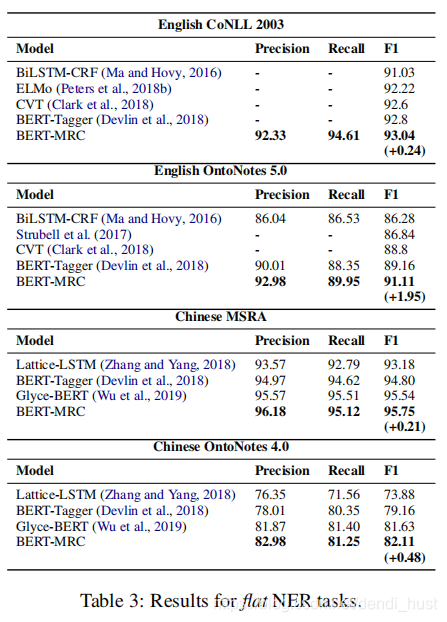
有上表可以看出,MRC方法构建的模型在OntoNotes数据集是的效果提升比较显著,这是因为该数据集有更多的实体类型,其中一些类型的数据非常稀疏。这也表明MRC在query中编码了一些先验知识,能够帮助模型缓解数据稀疏的问题
4. 分析
4.1 MRC or BERT ?
效果的提升是来自Bert还是MRC?对此,论文作者也做了对比实验:
- 对于
非BERT模型,作者比较了LSTM tagger(non-MRC)和BiDAF/QAnet(MRC); - 对于
BERT模型,作者比较了BERT-Tagger和BERT-MRC;
对比数据如下:
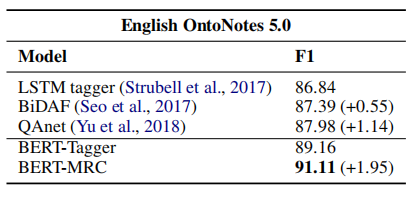
由上表的数据得出结论,无论是non-BERT还是BERT,MRC都比non-MRC效果好。
4.2 如何构建Question ?
Question的构建方式对结果有显著的影响,作者探索了一下几种方式:
- label的下标:直接使用label在标签集中的
下标作为question,如:one、two、tree; - 关键词:使用
关键词作为question,如ORG的question为organization; - 规则模板:用模板生成
question,如ORG的question为which organization is mentioned in the text; - 维基百科:用维基百科里的定义作为
question,如ORG的question为:an organization is an entity comprising multiple people, such as an institution or an association; - 近义词:使用label的近义词作为
question,如ORG的question为:association; - 关键词+近义词:将关键词和近义词连接起来作为
question; - 标注指南:上文提到的方法,如
ORG的question为find organizations including companies, agencies and institutions;
效果如下图所示:
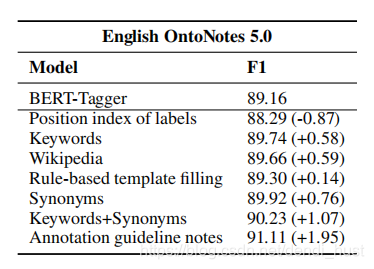
使用标注指南的模型效果最好,分析如下:
- 标签下标没有任何有用的信息,因此效果最差;
- 维基百科包含较多的无用信息,造成了干扰;
- 标注指南描述的最为准确,效果最好;
4.3 Zero-shot
MRC的方式构建模型,可以把一部分先验知识编码到question,因此在识别训练集上未出现的标签时效果会比非MRC的模型好,实验数据如下:
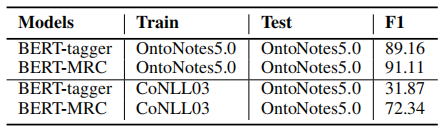
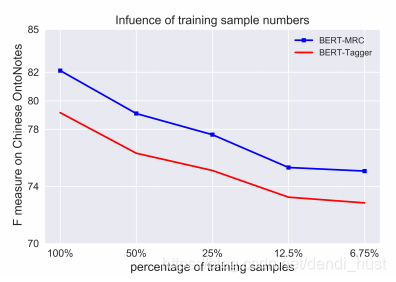
4.4 训练集大小
MRC的方式构建模型,可以把一部分先验知识编码到question,因此在小训练集上的效果更好,实验数据如下:


















 1万+
1万+







 到【灌水乐园】发言
到【灌水乐园】发言







