




 本文介绍了数据库索引的重要性,何时使用索引,以及如何创建和删除索引。详细讲解了索引的分类,如B+树、Hash、全文和R树等,并探讨了索引失效的情况。同时,还深入讨论了索引的存储结构,包括聚集和非聚集索引,以及索引回表和覆盖索引的概念。
本文介绍了数据库索引的重要性,何时使用索引,以及如何创建和删除索引。详细讲解了索引的分类,如B+树、Hash、全文和R树等,并探讨了索引失效的情况。同时,还深入讨论了索引的存储结构,包括聚集和非聚集索引,以及索引回表和覆盖索引的概念。
目录
一、为什么要用索引
索引就好比是一本书的目录,能快速定位数据。为了提高查询效率,减少查询时间
二、什么时候才用索引
2.经常出现在where的后面,以条件的形式存在,也就是说这个字段总是被扫描;
3.该字段很少DML(insert delete update)操作(因为DML之后,索引需要重新排序。索引越多,增删改越慢);
注意:建议不要随意添加索引。索引也是需要维护的,太多的话反而会降低系统的性能。
三、创建删除索引
1)创建索引
创建唯一索引:create unique index 索引名 ON 表名(字段);
创建普通索引:
create index 索引名 on 表名(字段); //索引创建在字段上
alter table 表名 add index 索引名(字段); //修改表时添加
创建组合索引:create index 索引名 on 表名(字段1,字段2);
2)删除索引
四、索引分类
1)按数据结构分类
1.B+树索引
二叉树:完全二叉树 、满二叉树 、二叉搜索树(又叫二叉排序树、二叉查找树) 、平衡二叉树 ( 又叫AVL树)、红黑树、堆、哈夫曼树(又叫最优二叉树)、线索二叉树
多叉树:B树(又叫多路平衡查找(搜索)树)、B+树、B*树)
2.Hash索引
mysql的Memory存储引擎,默认是 Hash索引。
3.全文索引(倒排索引)
使用like '%xxx%'进行模糊查询时,字段的索引就会失效。因此,在数据量大的情况下,通过此种方式查询的效率极低。这个时候,就可通过全文索引(Full-Text Search)来进行优化。
全文索引主要对字符串类型建立基于分词的索引,只有char、varchar,text 列上可以创建全文索引,以便能够更加快速地查询数据量较大的字符串类型的字段。
注意,MySQL 5.6之前,只有MyISAM支持全文索引。MySQL 5.6后MyISAM、InnoDB都支持。
使用语法可以参考:mysql全文索引_明豆的博客-优快云博客_mysql全文索引
4.R树空间索引
对空间数据类型的字段建立的索引。空间索引只能在存储引擎为myisam的表中创建,mysql中的空间数据类型有4种,分别是geometry、point、linestring、polygon。创建空间索引的列,必须将其声明为not null
2)按字段个数分类
1.单列索引
特殊的唯一索引,建立在表的主键字段,不能为null。(如果没有主键,则该表的第一个唯一非空索引作为聚集索引。如果没有主键,也没有合适的唯一索引,InnoDB会生成一个隐藏的主键列作为主键索引)
当某个列添加了Unique约束,会创建唯一索引。每列值必须唯一不能重复,可以为null。
2.组合索引(复合索引、联合索引)
最左前缀匹配原则:
(1)条件
组合索引的第一个字段必须出现在查询组句,组合索引才会被用到;
(3)例子
create index 索引名 on 表名(字段1,字段2,字段3);
联合索引实际建立了(字段1)、(字段1,字段2)、(字段1,字段2,字段3)三个索引。
select * from 表名 where 字段1=1 and 字段2=2; //语句1
select * from 表名 where 字段2=2 and 字段1=1; //查询优化器会优化成语句1
检索时使用索引(字段1,字段2)进行数据匹配。首先会对最左边的字段1的数据排序,然后再对字段2排序。相当于执行了“order by 字段1,字段2”。
索引中所有列通过"=" 或 “IN” 进行精确匹配时,索引都可以被用到
遇到范围查询(>、<、between、like)就会停止匹配
select * from 表名 where 字段1>1 and 字段2=2; //a字段走索引(有序),b全表扫描(无序)
select * from 表名 where 字段1>1 and 字段2>2 and 字段3=3; //a、b字段走索引(有序),c无序全表扫描(无序)
3)按物理存储分类
1.聚簇索引
(1)记录和索引物理顺序一致(即索引的排列顺序和表数据的排列顺序一致),索引和对应行挨着存放;
(2)聚集索引就是主键索引,建立在表的主键上。如果主键是联合主键,则为组合索引;
(5)更新慢。因为要保持表中记录和索引的物理顺序一致,在插入新记录的时候就会对索引重新做一次排序
2.非聚簇索引(二级索引、辅助索引)
(1)记录和索引物理不连续,而是逻辑上连续,索引和对应行不存放在一起;
(5)更新快。因为不需要维护表记录和索引的物理顺序一致,逻辑一致就行了
五、索引失效
1)Like
select * from 表名 where name like '张%' //走索引
2)or
select * from 表名 where name= '张三' or age= 18 //走索引(or左右所有条件字段都有索引,才走索引)
select * from 表名 where name= '张三' or course='历史' //不走索引
补充说明:用or可能不走索引,因此尽量用union联合查询代替or
3)索引列计算,不走索引
4)索引列用函数,不走索引
5)索引列用!=,不走索引
六、索引的存储结构
索引的存储结构部分参考了文章:【MySQL】索引优化中的最左前缀原则和索引下推 - 灰信网(软件开发博客聚合)
1)概述
聚集索引:索引区存储主键值,数据区存储除了主键值外当前行数据
2)聚集索引存储结构的例子
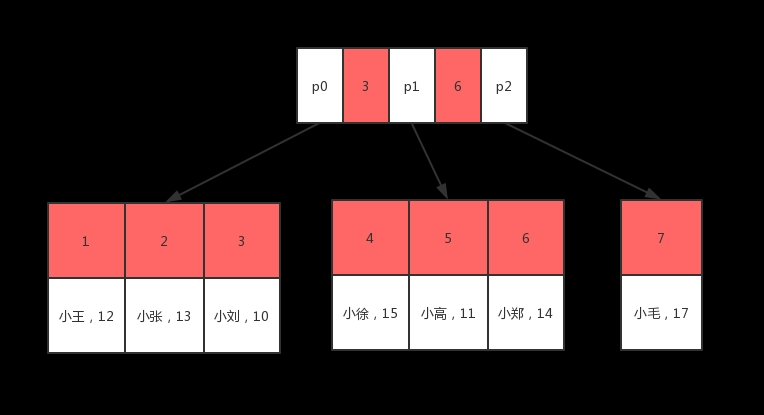
3)聚集索引和非聚集索引存储结构的综合例子
表包含主键列ID(上有聚集索引)、普通列K(上有非聚集索引)。
insert into T values(100,1,'aa'),(200,2,'bb'),(300,3,'cc'),(500,5,'ee'),(600,6,'ff'),(700,7,'gg');
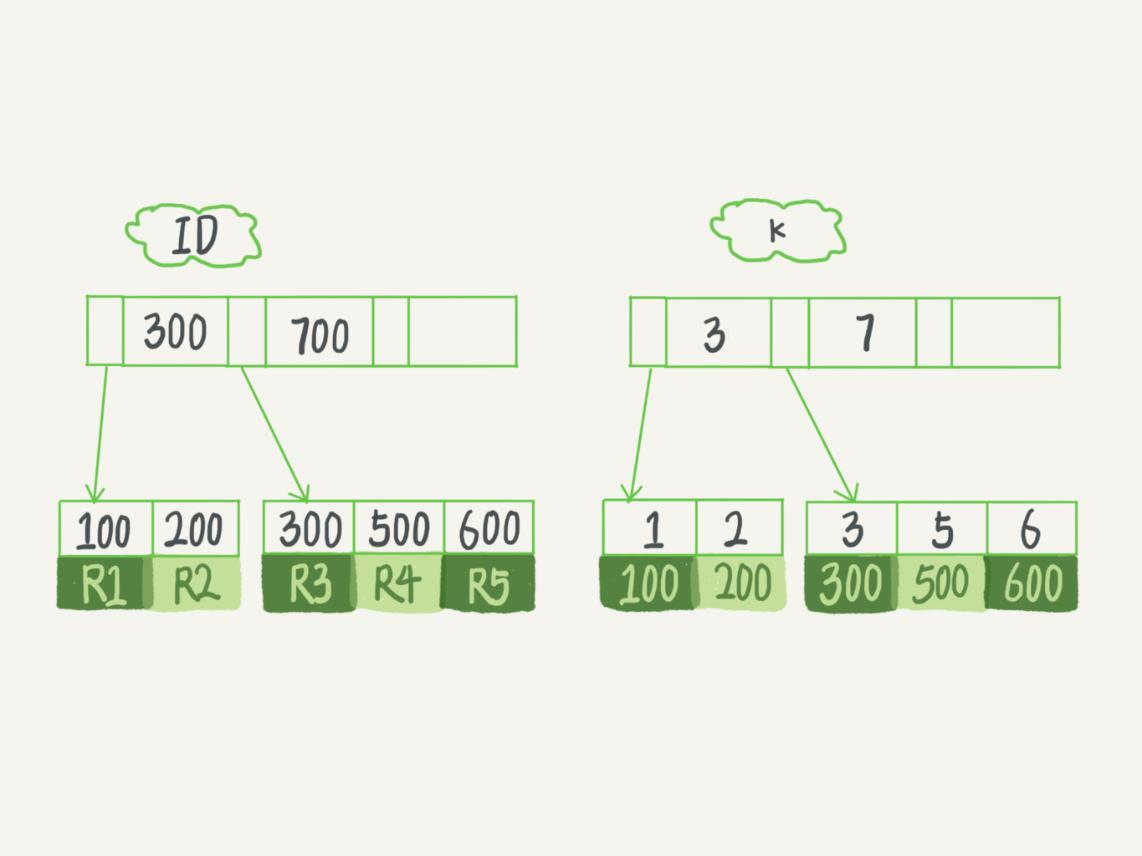
4)索引回表
1.定义
非聚集索引只存储当前列的值、列所在行对应的主键值,不存储所在列对应行其它列的数据。当查询条件是索引对应列,使用到了该索引,但是返回列表包含除了索引对应列的其他列。那么,执行查询,第一次只能通过主键值找到聚集索引 , 第二次再通过聚集索引才能找到需要的其他列数据;
2.例子
select name,age from user where name='张三'; //要回表,因为返回列表包含其他列age
在 k 索引树上找到 k=3 的记录,取得 ID = 300;
再到 ID 索引树查到 ID=300 对应的 R3;(回表1次)
3.解决办法
使用覆盖索引(覆盖索引是select的数据列只用从索引中就能够取得,不必读取数据行,换句话说查询列要被所建的索引包含覆盖)。
刚才的例子,只用把name和age建立联合索引,就实现了覆盖索引。
5)索引覆盖
如果执行的语句是 select ID from T where k between 3 and 5,这时只需要查 ID 的值,而 ID 的值已经在 k 索引树上了(辅助索引树的结点数据区存的是其对应的主键值),因此可以直接提供查询结果,不需要回表。也就是说,在这个查询里面,索引 k 已经“覆盖了”我们的查询需求,我们称为索引覆盖。

















 2662
2662

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









