




- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
目标
- 了解1X1卷积运算原理
- 实现Inception v1
- 利用Inception v1模型进行猴痘病识别
具体实现
(一)环境
语言环境:Python 3.10
编 译 器: PyCharm
框 架: Pytorch
(二)具体步骤
1. 1X1 卷积运算原理
1×1卷积的基本原理
1×1卷积实际上是一个特殊的卷积操作,其核心特点是卷积核的空间维度为1×1,但它仍然在通道维度上进行全连接操作。
如何降低通道数
1×1卷积降低通道数的原理可以从数学角度来理解:
假设我们有一个输入特征图,其尺寸为 H×W×C_in(高度×宽度×输入通道数)。
当我们应用 N 个1×1卷积核(其中 N < C_in)时,每个卷积核都会与输入的 C_in 个通道进行计算,然后输出一个通道。这 N 个卷积核总共会产生 N 个输出通道,从而将通道数从 C_in 减少到 N。
简单理解:
1. 不管原来有多少通道数,与N个1X1卷积核运算,最终就是N个通道数。
2. N个1X1卷积核是指整个卷积核,而不是指一个1X1卷积核的通道数。
具体计算过程
对于输入特征图的每个空间位置 (i,j):
- 每个1×1卷积核包含 C_in 个权重参数(对应输入的每个通道一个权重)和一个偏置参数
- 对于第 k 个卷积核,输出特征图在位置 (i,j) 上的值计算为:
- 输出(i,j,k) = 偏置_k + ∑(输入(i,j,c) × 权重_k,c),其中c从1到C_in
- 这一计算过程相当于对每个空间位置独立地进行一次全连接操作,将C_in个输入通道映射到N个输出通道
矩阵表示
从矩阵角度看,1×1卷积可以表示为:
- 输入特征图重塑为矩阵 X,形状为 (H×W, C_in)
- 卷积权重矩阵 W,形状为 (C_in, N)
- 输出特征图 Y = X·W + b,形状为 (H×W, N)
- 然后将Y重塑回 (H, W, N) 的形状
实际应用示例
以一个具体例子说明:
- 输入特征图:32×32×256(256个通道)
- 应用64个1×1卷积核
- 输出特征图:32×32×64(通道数从256降至64)
在这个过程中,模型参数数量为:64×(256+1) = 16,448个(每个卷积核256个权重加1个偏置)。
为什么这样做有用
1×1卷积降低通道数的主要用途包括:
- 降维:减少后续层的计算量
- 特征重组:学习通道间的线性组合,提取更有效的特征表示
- 模型压缩:减少模型参数和计算复杂度
与全连接层的区别
1×1卷积与全连接层的主要区别在于:
- 1×1卷积在每个空间位置独立应用相同的线性变换
- 全连接层会将所有空间位置的信息混合在一起
这使得1×1卷积能保持空间维度不变,只改变通道维度,而全连接层会丢失空间信息。
通过这种方式,1×1卷积提供了一种计算效率高且参数高效的方法来控制网络中的通道数量。
2. 模型代码实现
import torch
import torch.nn as nn
import torch.nn.functional as F
class inception_block(nn.Module):
def __init__(self,in_channels,ch1x1,ch3x3red, ch3x3, ch5x5red, ch5x5, pool_proj):
super(inception_block, self).__init__()
# 1x1 conv branch
self.branch1 =nn.Sequential(
nn.Conv2d(in_channels,ch1x1,kernel_size=1),
nn.BatchNorm2d(ch1x1),
nn.ReLU(inplace=True)
)
# 1x1 conv ->3x3 conv branch
self.branch2 = nn.Sequential(
nn.Conv2d(in_channels,ch3x3red,kernel_size=1),
nn.BatchNorm2d(ch3x3red),
nn.ReLU(inplace=True),
nn.Conv2d(ch3x3red,ch3x3,kernel_size=3,padding=1),
nn.BatchNorm2d(ch3x3),
nn.ReLU(inplace=True)
)
# 1x1 conv ->5x5 convbranch
self.branch3 =nn.Sequential(
nn.Conv2d(in_channels,ch5x5red,kernel_size=1),
nn.BatchNorm2d(ch5x5red),
nn.ReLU(inplace=True),
nn.Conv2d(ch5x5red,ch5x5,kernel_size=5,padding=2),
nn.BatchNorm2d(ch5x5),
nn.ReLU(inplace=True)
)
# 3x3 max pooling->1x1 conv branch
self.branch4 =nn.Sequential(
nn.MaxPool2d(kernel_size=3,stride=1,padding=1),
nn.Conv2d(in_channels,pool_proj,kernel_size=1),
nn.BatchNorm2d(pool_proj),
nn.ReLU(inplace=True)
)
def forward(self,x):
# Compute forward pass through all branches and concatenate the output feature maps
branch1_output = self.branch1(x)
branch2_output = self.branch2(x)
branch3_output = self.branch3(x)
branch4_output = self.branch4(x)
outputs = [branch1_output, branch2_output, branch3_output, branch4_output]
return torch.cat(outputs,1)
class InceptionV1(nn.Module):
def __init__(self,num_classes=1000):
super(InceptionV1,self).__init__()
self.conv1 =nn.Conv2d(3,64,kernel_size=7,stride=2,padding=3)
self.maxpool1 = nn.MaxPool2d(kernel_size=3,stride=2,padding=1)
self.conv2 =nn.Conv2d(64,64,kernel_size=1,stride=1, padding=0)
self.conv3 =nn.Conv2d(64,192,kernel_size=3,stride=1, padding=1)
self.maxpool2 = nn.MaxPool2d(kernel_size=3,stride=2, padding=1)
self.inception3a = inception_block(192, 64, 96, 128, 16, 32, 32)
self.inception3b = inception_block(256, 128, 128, 192, 32, 96, 64)
self.maxpool3 = nn.MaxPool2d(kernel_size=3,stride=2,padding=1)
self.inception4a = inception_block(480, 192, 96, 208, 16, 48, 64)
self.inception4b = inception_block(512, 160, 112, 224, 24, 64, 64)
self.inception4c = inception_block(512, 128, 128, 256, 24, 64, 64)
self.inception4d = inception_block(512, 112, 144, 288, 32, 64, 64)
self.inception4e = inception_block(528, 256, 160, 320, 32, 128, 128)
self.maxpool4 = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.inception5a = inception_block(832, 256, 160, 320, 32, 128, 128)
self.inception5b = nn.Sequential(
inception_block(832,384,192,384,48,128,128),
nn.AvgPool2d(kernel_size=7,stride=1,padding=0),
nn.Dropout(0.4)
)
#全连接网络层,用于分类
self.classifier =nn.Sequential(
nn.Linear(in_features=1024, out_features=1024),
nn.ReLU(),
nn.Linear(in_features=1024,out_features=num_classes),
nn.Softmax(dim=1)
)
def forward(self,x):
x= self.conv1(x)
x= F.relu(x)
x= self.maxpool1(x)
x= self.conv2(x)
x = F.relu(x)
x= self.conv3(x)
x = F.relu(x)
x= self.maxpool2(x)
x= self.inception3a(x)
x= self.inception3b(x)
x= self.maxpool3(x)
x= self.inception4a(x)
x= self.inception4b(x)
x= self.inception4c(x)
x= self.inception4d(x)
x= self.inception4e(x)
x= self.maxpool4(x)
x= self.inception5a(x)
x= self.inception5b(x)
x= torch.flatten(x,start_dim=1)
x= self.classifier(x)
return x
if __name__ == "__main__":
import torchsummary
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = InceptionV1().to(device)
summary = torchsummary.summary(model,(3,224,224))
print(summary)
print(model)
输出:
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 64, 112, 112] 9,472
MaxPool2d-2 [-1, 64, 56, 56] 0
Conv2d-3 [-1, 64, 56, 56] 4,160
Conv2d-4 [-1, 192, 56, 56] 110,784
MaxPool2d-5 [-1, 192, 28, 28] 0
Conv2d-6 [-1, 64, 28, 28] 12,352
BatchNorm2d-7 [-1, 64, 28, 28] 128
ReLU-8 [-1, 64, 28, 28] 0
Conv2d-9 [-1, 96, 28, 28] 18,528
BatchNorm2d-10 [-1, 96, 28, 28] 192
ReLU-11 [-1, 96, 28, 28] 0
Conv2d-12 [-1, 128, 28, 28] 110,720
BatchNorm2d-13 [-1, 128, 28, 28] 256
ReLU-14 [-1, 128, 28, 28] 0
Conv2d-15 [-1, 16, 28, 28] 3,088
BatchNorm2d-16 [-1, 16, 28, 28] 32
ReLU-17 [-1, 16, 28, 28] 0
Conv2d-18 [-1, 32, 28, 28] 12,832
BatchNorm2d-19 [-1, 32, 28, 28] 64
ReLU-20 [-1, 32, 28, 28] 0
MaxPool2d-21 [-1, 192, 28, 28] 0
Conv2d-22 [-1, 32, 28, 28] 6,176
BatchNorm2d-23 [-1, 32, 28, 28] 64
ReLU-24 [-1, 32, 28, 28] 0
inception_block-25 [-1, 256, 28, 28] 0
Conv2d-26 [-1, 128, 28, 28] 32,896
BatchNorm2d-27 [-1, 128, 28, 28] 256
ReLU-28 [-1, 128, 28, 28] 0
Conv2d-29 [-1, 128, 28, 28] 32,896
BatchNorm2d-30 [-1, 128, 28, 28] 256
ReLU-31 [-1, 128, 28, 28] 0
Conv2d-32 [-1, 192, 28, 28] 221,376
BatchNorm2d-33 [-1, 192, 28, 28] 384
ReLU-34 [-1, 192, 28, 28] 0
Conv2d-35 [-1, 32, 28, 28] 8,224
BatchNorm2d-36 [-1, 32, 28, 28] 64
ReLU-37 [-1, 32, 28, 28] 0
Conv2d-38 [-1, 96, 28, 28] 76,896
BatchNorm2d-39 [-1, 96, 28, 28] 192
ReLU-40 [-1, 96, 28, 28] 0
MaxPool2d-41 [-1, 256, 28, 28] 0
Conv2d-42 [-1, 64, 28, 28] 16,448
BatchNorm2d-43 [-1, 64, 28, 28] 128
ReLU-44 [-1, 64, 28, 28] 0
inception_block-45 [-1, 480, 28, 28] 0
MaxPool2d-46 [-1, 480, 14, 14] 0
Conv2d-47 [-1, 192, 14, 14] 92,352
BatchNorm2d-48 [-1, 192, 14, 14] 384
ReLU-49 [-1, 192, 14, 14] 0
Conv2d-50 [-1, 96, 14, 14] 46,176
BatchNorm2d-51 [-1, 96, 14, 14] 192
ReLU-52 [-1, 96, 14, 14] 0
Conv2d-53 [-1, 208, 14, 14] 179,920
BatchNorm2d-54 [-1, 208, 14, 14] 416
ReLU-55 [-1, 208, 14, 14] 0
Conv2d-56 [-1, 16, 14, 14] 7,696
BatchNorm2d-57 [-1, 16, 14, 14] 32
ReLU-58 [-1, 16, 14, 14] 0
Conv2d-59 [-1, 48, 14, 14] 19,248
BatchNorm2d-60 [-1, 48, 14, 14] 96
ReLU-61 [-1, 48, 14, 14] 0
MaxPool2d-62 [-1, 480, 14, 14] 0
Conv2d-63 [-1, 64, 14, 14] 30,784
BatchNorm2d-64 [-1, 64, 14, 14] 128
ReLU-65 [-1, 64, 14, 14] 0
inception_block-66 [-1, 512, 14, 14] 0
Conv2d-67 [-1, 160, 14, 14] 82,080
BatchNorm2d-68 [-1, 160, 14, 14] 320
ReLU-69 [-1, 160, 14, 14] 0
Conv2d-70 [-1, 112, 14, 14] 57,456
BatchNorm2d-71 [-1, 112, 14, 14] 224
ReLU-72 [-1, 112, 14, 14] 0
Conv2d-73 [-1, 224, 14, 14] 226,016
BatchNorm2d-74 [-1, 224, 14, 14] 448
ReLU-75 [-1, 224, 14, 14] 0
Conv2d-76 [-1, 24, 14, 14] 12,312
BatchNorm2d-77 [-1, 24, 14, 14] 48
ReLU-78 [-1, 24, 14, 14] 0
Conv2d-79 [-1, 64, 14, 14] 38,464
BatchNorm2d-80 [-1, 64, 14, 14] 128
ReLU-81 [-1, 64, 14, 14] 0
MaxPool2d-82 [-1, 512, 14, 14] 0
Conv2d-83 [-1, 64, 14, 14] 32,832
BatchNorm2d-84 [-1, 64, 14, 14] 128
ReLU-85 [-1, 64, 14, 14] 0
inception_block-86 [-1, 512, 14, 14] 0
Conv2d-87 [-1, 128, 14, 14] 65,664
BatchNorm2d-88 [-1, 128, 14, 14] 256
ReLU-89 [-1, 128, 14, 14] 0
Conv2d-90 [-1, 128, 14, 14] 65,664
BatchNorm2d-91 [-1, 128, 14, 14] 256
ReLU-92 [-1, 128, 14, 14] 0
Conv2d-93 [-1, 256, 14, 14] 295,168
BatchNorm2d-94 [-1, 256, 14, 14] 512
ReLU-95 [-1, 256, 14, 14] 0
Conv2d-96 [-1, 24, 14, 14] 12,312
BatchNorm2d-97 [-1, 24, 14, 14] 48
ReLU-98 [-1, 24, 14, 14] 0
Conv2d-99 [-1, 64, 14, 14] 38,464
BatchNorm2d-100 [-1, 64, 14, 14] 128
ReLU-101 [-1, 64, 14, 14] 0
MaxPool2d-102 [-1, 512, 14, 14] 0
Conv2d-103 [-1, 64, 14, 14] 32,832
BatchNorm2d-104 [-1, 64, 14, 14] 128
ReLU-105 [-1, 64, 14, 14] 0
inception_block-106 [-1, 512, 14, 14] 0
Conv2d-107 [-1, 112, 14, 14] 57,456
BatchNorm2d-108 [-1, 112, 14, 14] 224
ReLU-109 [-1, 112, 14, 14] 0
Conv2d-110 [-1, 144, 14, 14] 73,872
BatchNorm2d-111 [-1, 144, 14, 14] 288
ReLU-112 [-1, 144, 14, 14] 0
Conv2d-113 [-1, 288, 14, 14] 373,536
BatchNorm2d-114 [-1, 288, 14, 14] 576
ReLU-115 [-1, 288, 14, 14] 0
Conv2d-116 [-1, 32, 14, 14] 16,416
BatchNorm2d-117 [-1, 32, 14, 14] 64
ReLU-118 [-1, 32, 14, 14] 0
Conv2d-119 [-1, 64, 14, 14] 51,264
BatchNorm2d-120 [-1, 64, 14, 14] 128
ReLU-121 [-1, 64, 14, 14] 0
MaxPool2d-122 [-1, 512, 14, 14] 0
Conv2d-123 [-1, 64, 14, 14] 32,832
BatchNorm2d-124 [-1, 64, 14, 14] 128
ReLU-125 [-1, 64, 14, 14] 0
inception_block-126 [-1, 528, 14, 14] 0
Conv2d-127 [-1, 256, 14, 14] 135,424
BatchNorm2d-128 [-1, 256, 14, 14] 512
ReLU-129 [-1, 256, 14, 14] 0
Conv2d-130 [-1, 160, 14, 14] 84,640
BatchNorm2d-131 [-1, 160, 14, 14] 320
ReLU-132 [-1, 160, 14, 14] 0
Conv2d-133 [-1, 320, 14, 14] 461,120
BatchNorm2d-134 [-1, 320, 14, 14] 640
ReLU-135 [-1, 320, 14, 14] 0
Conv2d-136 [-1, 32, 14, 14] 16,928
BatchNorm2d-137 [-1, 32, 14, 14] 64
ReLU-138 [-1, 32, 14, 14] 0
Conv2d-139 [-1, 128, 14, 14] 102,528
BatchNorm2d-140 [-1, 128, 14, 14] 256
ReLU-141 [-1, 128, 14, 14] 0
MaxPool2d-142 [-1, 528, 14, 14] 0
Conv2d-143 [-1, 128, 14, 14] 67,712
BatchNorm2d-144 [-1, 128, 14, 14] 256
ReLU-145 [-1, 128, 14, 14] 0
inception_block-146 [-1, 832, 14, 14] 0
MaxPool2d-147 [-1, 832, 7, 7] 0
Conv2d-148 [-1, 256, 7, 7] 213,248
BatchNorm2d-149 [-1, 256, 7, 7] 512
ReLU-150 [-1, 256, 7, 7] 0
Conv2d-151 [-1, 160, 7, 7] 133,280
BatchNorm2d-152 [-1, 160, 7, 7] 320
ReLU-153 [-1, 160, 7, 7] 0
Conv2d-154 [-1, 320, 7, 7] 461,120
BatchNorm2d-155 [-1, 320, 7, 7] 640
ReLU-156 [-1, 320, 7, 7] 0
Conv2d-157 [-1, 32, 7, 7] 26,656
BatchNorm2d-158 [-1, 32, 7, 7] 64
ReLU-159 [-1, 32, 7, 7] 0
Conv2d-160 [-1, 128, 7, 7] 102,528
BatchNorm2d-161 [-1, 128, 7, 7] 256
ReLU-162 [-1, 128, 7, 7] 0
MaxPool2d-163 [-1, 832, 7, 7] 0
Conv2d-164 [-1, 128, 7, 7] 106,624
BatchNorm2d-165 [-1, 128, 7, 7] 256
ReLU-166 [-1, 128, 7, 7] 0
inception_block-167 [-1, 832, 7, 7] 0
Conv2d-168 [-1, 384, 7, 7] 319,872
BatchNorm2d-169 [-1, 384, 7, 7] 768
ReLU-170 [-1, 384, 7, 7] 0
Conv2d-171 [-1, 192, 7, 7] 159,936
BatchNorm2d-172 [-1, 192, 7, 7] 384
ReLU-173 [-1, 192, 7, 7] 0
Conv2d-174 [-1, 384, 7, 7] 663,936
BatchNorm2d-175 [-1, 384, 7, 7] 768
ReLU-176 [-1, 384, 7, 7] 0
Conv2d-177 [-1, 48, 7, 7] 39,984
BatchNorm2d-178 [-1, 48, 7, 7] 96
ReLU-179 [-1, 48, 7, 7] 0
Conv2d-180 [-1, 128, 7, 7] 153,728
BatchNorm2d-181 [-1, 128, 7, 7] 256
ReLU-182 [-1, 128, 7, 7] 0
MaxPool2d-183 [-1, 832, 7, 7] 0
Conv2d-184 [-1, 128, 7, 7] 106,624
BatchNorm2d-185 [-1, 128, 7, 7] 256
ReLU-186 [-1, 128, 7, 7] 0
inception_block-187 [-1, 1024, 7, 7] 0
AvgPool2d-188 [-1, 1024, 1, 1] 0
Dropout-189 [-1, 1024, 1, 1] 0
Linear-190 [-1, 1024] 1,049,600
ReLU-191 [-1, 1024] 0
Linear-192 [-1, 1000] 1,025,000
Softmax-193 [-1, 1000] 0
================================================================
Total params: 8,062,072
Trainable params: 8,062,072
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 69.63
Params size (MB): 30.75
Estimated Total Size (MB): 100.96
----------------------------------------------------------------
3. 进行猴痘病识别
3.1 数据预处理脚本(preprocess_dataset.py)
# preprocess_dataset.py
import os
import shutil
import random
from PIL import Image
import argparse
from tqdm import tqdm
def preprocess_dataset(input_dir, output_dir, split_ratio=0.8):
"""
预处理猴痘病数据集。
参数:
- input_dir: 输入数据目录
- output_dir: 输出数据目录
- split_ratio: 训练/验证数据分割比例
"""
# 检查输入目录
if not os.path.exists(input_dir):
raise ValueError(f"Input directory {input_dir} does not exist")
# 创建输出目录结构
train_dir = os.path.join(output_dir, 'train')
val_dir = os.path.join(output_dir, 'val')
# 确保输出目录存在
os.makedirs(train_dir, exist_ok=True)
os.makedirs(val_dir, exist_ok=True)
# 获取所有类别
classes = [d for d in os.listdir(input_dir) if os.path.isdir(os.path.join(input_dir, d))]
if not classes:
# 如果输入目录没有子目录,尝试按文件扩展名组织
print("No class directories found. Trying to organize by file extensions...")
try:
# 假设正常图像是 .jpg,猴痘图像是 .png (或其他区分方式)
normal_images = [f for f in os.listdir(input_dir) if f.lower().endswith('.jpg')]
monkeypox_images = [f for f in os.listdir(input_dir) if f.lower().endswith('.png')]
# 创建类别目录
os.makedirs(os.path.join(train_dir, "normal"), exist_ok=True)
os.makedirs(os.path.join(train_dir, "monkeypox"), exist_ok=True)
os.makedirs(os.path.join(val_dir, "normal"), exist_ok=True)
os.makedirs(os.path.join(val_dir, "monkeypox"), exist_ok=True)
# 处理正常图像
random.shuffle(normal_images)
split_idx = int(len(normal_images) * split_ratio)
print("Processing normal images...")
for i, img in enumerate(tqdm(normal_images)):
src = os.path.join(input_dir, img)
if i < split_idx:
dst = os.path.join(train_dir, "normal", img)
else:
dst = os.path.join(val_dir, "normal", img)
shutil.copy2(src, dst)
# 处理猴痘图像
random.shuffle(monkeypox_images)
split_idx = int(len(monkeypox_images) * split_ratio)
print("Processing monkeypox images...")
for i, img in enumerate(tqdm(monkeypox_images)):
src = os.path.join(input_dir, img)
if i < split_idx:
dst = os.path.join(train_dir, "monkeypox", img)
else:
dst = os.path.join(val_dir, "monkeypox", img)
shutil.copy2(src, dst)
print(f"Processed {len(normal_images)} normal images and {len(monkeypox_images)} monkeypox images")
return
except Exception as e:
print(f"Error organizing by extensions: {e}")
raise ValueError("Could not process dataset. Please ensure the data is organized in class folders.")
# 处理每个类别
for class_name in classes:
print(f"Processing class: {class_name}")
# 创建类别目录
train_class_dir = os.path.join(train_dir, class_name)
val_class_dir = os.path.join(val_dir, class_name)
os.makedirs(train_class_dir, exist_ok=True)
os.makedirs(val_class_dir, exist_ok=True)
# 获取该类别的所有图像
class_dir = os.path.join(input_dir, class_name)
images = [img for img in os.listdir(class_dir) if img.lower().endswith(('.png', '.jpg', '.jpeg'))]
# 随机打乱图像
random.shuffle(images)
# 分割为训练集和验证集
split_idx = int(len(images) * split_ratio)
train_images = images[:split_idx]
val_images = images[split_idx:]
# 复制图像到相应目录
for img in tqdm(train_images, desc=f"Training {class_name}"):
src = os.path.join(class_dir, img)
dst = os.path.join(train_class_dir, img)
try:
# 检查图像是否有效
with Image.open(src) as img_obj:
# 复制文件
shutil.copy2(src, dst)
except Exception as e:
print(f"Error processing {src}: {e}")
for img in tqdm(val_images, desc=f"Validation {class_name}"):
src = os.path.join(class_dir, img)
dst = os.path.join(val_class_dir, img)
try:
# 检查图像是否有效
with Image.open(src) as img_obj:
# 复制文件
shutil.copy2(src, dst)
except Exception as e:
print(f"Error processing {src}: {e}")
print(f"Processed {class_name}: {len(train_images)} training images, {len(val_images)} validation images")
def verify_dataset(data_dir):
"""
验证数据集是否有效。
参数:
- data_dir: 数据目录
"""
train_dir = os.path.join(data_dir, 'train')
val_dir = os.path.join(data_dir, 'val')
if not os.path.exists(train_dir) or not os.path.exists(val_dir):
return False
train_classes = [d for d in os.listdir(train_dir) if os.path.isdir(os.path.join(train_dir, d))]
val_classes = [d for d in os.listdir(val_dir) if os.path.isdir(os.path.join(val_dir, d))]
if not train_classes or not val_classes:
return False
# 确保每个类别都有图像
for class_name in train_classes:
class_dir = os.path.join(train_dir, class_name)
images = [img for img in os.listdir(class_dir) if img.lower().endswith(('.png', '.jpg', '.jpeg'))]
if not images:
print(f"Warning: No images found in {class_dir}")
return False
for class_name in val_classes:
class_dir = os.path.join(val_dir, class_name)
images = [img for img in os.listdir(class_dir) if img.lower().endswith(('.png', '.jpg', '.jpeg'))]
if not images:
print(f"Warning: No images found in {class_dir}")
return False
return True
if __name__ == "__main__":
parser = argparse.ArgumentParser(description='Preprocess monkey disease dataset')
parser.add_argument('--input_dir', type=str, required=True, help='Input data directory')
parser.add_argument('--output_dir', type=str, default='./data/monkeypox', help='Output data directory')
parser.add_argument('--split_ratio', type=float, default=0.8, help='Train/validation split ratio')
parser.add_argument('--verify', action='store_true', help='Only verify the dataset')
args = parser.parse_args()
if args.verify:
if verify_dataset(args.output_dir):
print("Dataset is valid!")
else:
print("Dataset is invalid or incomplete!")
else:
preprocess_dataset(args.input_dir, args.output_dir, args.split_ratio)
print("Dataset preprocessing completed!")
# 验证数据集
if verify_dataset(args.output_dir):
print("Dataset is valid and ready for training!")
else:
print("Warning: Dataset may be incomplete or invalid. Please check the data.")
处理结果:
python preprocess_dataset.py --input_dir ./data/monkeypox/raw --output_dir ./data/monkeypox
Processing class: Monkeypox
Training Monkeypox: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 784/784 [00:00<00:00, 1546.05it/s]
Validation Monkeypox: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 196/196 [00:00<00:00, 1598.22it/s]
Processed Monkeypox: 784 training images, 196 validation images
Processing class: Normal
Training Normal: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 929/929 [00:00<00:00, 1638.56it/s]
Validation Normal: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 233/233 [00:00<00:00, 1676.05it/s]
Processed Normal: 929 training images, 233 validation images
Dataset preprocessing completed!
Dataset is valid and ready for training!
3.2 模型训练(train_monkeypox_model.py)
# train_monkeypox_model.py
import os
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import transforms, datasets
import matplotlib.pyplot as plt
import numpy as np
from sklearn.metrics import confusion_matrix, classification_report
from tqdm import tqdm
import time
import copy
import argparse
# 导入我们已有的InceptionV1模型
from Inceptionv1 import InceptionV1
def get_transforms():
# 训练数据变换
train_transform = transforms.Compose([
transforms.Resize((224, 224)), # InceptionV1 输入大小为224x224
transforms.RandomHorizontalFlip(),
transforms.RandomRotation(10),
transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
# 验证/测试数据变换
val_transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
return train_transform, val_transform
def load_data(data_dir, batch_size=32):
train_transform, val_transform = get_transforms()
# 假设数据集结构是data_dir下有train和val两个文件夹
train_dir = os.path.join(data_dir, 'train')
val_dir = os.path.join(data_dir, 'val')
# 如果没有val目录,则使用train目录并拆分
if not os.path.exists(val_dir):
print("Validation directory not found. Using a split of training data.")
dataset = datasets.ImageFolder(train_dir, transform=train_transform)
train_size = int(0.8 * len(dataset))
val_size = len(dataset) - train_size
train_dataset, val_dataset = torch.utils.data.random_split(dataset, [train_size, val_size])
# 为验证集应用正确的变换
val_dataset.dataset.transform = val_transform
else:
train_dataset = datasets.ImageFolder(train_dir, transform=train_transform)
val_dataset = datasets.ImageFolder(val_dir, transform=val_transform)
# 创建数据加载器
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=4)
val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False, num_workers=4)
# 获取类别
class_names = None
if isinstance(train_dataset, datasets.ImageFolder):
class_names = train_dataset.classes
else:
class_names = dataset.classes
print(f"Class names: {class_names}")
print(f"Training images: {len(train_dataset)}")
print(f"Validation images: {len(val_dataset)}")
return train_loader, val_loader, class_names
def train_model(model, criterion, optimizer, train_loader, val_loader, num_epochs=25, scheduler=None):
since = time.time()
best_model_wts = copy.deepcopy(model.state_dict())
best_acc = 0.0
# 记录训练过程
history = {
'train_loss': [],
'train_acc': [],
'val_loss': [],
'val_acc': []
}
for epoch in range(num_epochs):
print(f'Epoch {epoch+1}/{num_epochs}')
print('-' * 10)
# 每个epoch都有训练和验证阶段
for phase in ['train', 'val']:
if phase == 'train':
model.train() # 设置模型为训练模式
dataloader = train_loader
else:
model.eval() # 设置模型为评估模式
dataloader = val_loader
running_loss = 0.0
running_corrects = 0
# 遍历数据
for inputs, labels in tqdm(dataloader, desc=phase):
inputs = inputs.to(device)
labels = labels.to(device)
# 梯度清零
optimizer.zero_grad()
# 前向传播
# 只有在训练阶段才跟踪梯度
with torch.set_grad_enabled(phase == 'train'):
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
# 如果是训练阶段,则反向传播+优化
if phase == 'train':
loss.backward()
optimizer.step()
# 统计
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
if scheduler is not None and phase == 'train':
scheduler.step()
epoch_loss = running_loss / len(dataloader.dataset)
epoch_acc = running_corrects.double() / len(dataloader.dataset)
print(f'{phase} Loss: {epoch_loss:.4f} Acc: {epoch_acc:.4f}')
# 记录训练和验证的损失和准确率
if phase == 'train':
history['train_loss'].append(epoch_loss)
history['train_acc'].append(epoch_acc.item())
else:
history['val_loss'].append(epoch_loss)
history['val_acc'].append(epoch_acc.item())
# 如果是最好的模型,保存模型
if phase == 'val' and epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = copy.deepcopy(model.state_dict())
# 保存最佳模型
torch.save(model.state_dict(), 'best_monkeypox_model.pth')
print(f'New best model saved with accuracy: {best_acc:.4f}')
print()
time_elapsed = time.time() - since
print(f'Training complete in {time_elapsed // 60:.0f}m {time_elapsed % 60:.0f}s')
print(f'Best val Acc: {best_acc:.4f}')
# 加载最佳模型权重
model.load_state_dict(best_model_wts)
return model, history
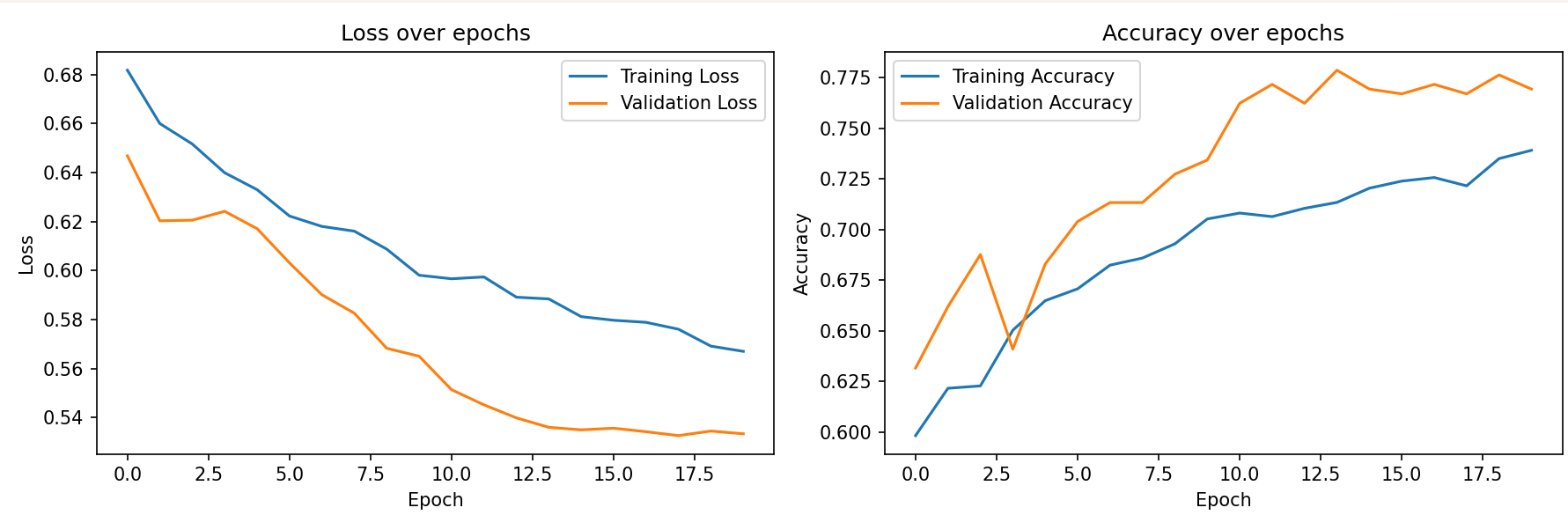
def plot_training(history):
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(history['train_loss'], label='Training Loss')
plt.plot(history['val_loss'], label='Validation Loss')
plt.title('Loss over epochs')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(history['train_acc'], label='Training Accuracy')
plt.plot(history['val_acc'], label='Validation Accuracy')
plt.title('Accuracy over epochs')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend()
plt.tight_layout()
plt.savefig('training_history.png')
plt.show()
def main():
parser = argparse.ArgumentParser(description='Train Monkeypox Detection Model')
parser.add_argument('--data_dir', type=str, default='./data/monkeypox', help='Data directory')
parser.add_argument('--batch_size', type=int, default=32, help='Batch size')
parser.add_argument('--num_epochs', type=int, default=20, help='Number of epochs')
parser.add_argument('--learning_rate', type=float, default=0.001, help='Learning rate')
parser.add_argument('--save_path', type=str, default='monkeypox_detection_model.pth', help='Model save path')
args = parser.parse_args()
# 加载数据
train_loader, val_loader, class_names = load_data(args.data_dir, args.batch_size)
# 初始化模型
model = InceptionV1(num_classes=len(class_names))
model = model.to(device)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=args.learning_rate)
# 学习率调度器
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=7, gamma=0.1)
# 训练模型
model, history = train_model(
model, criterion, optimizer,
train_loader, val_loader,
num_epochs=args.num_epochs,
scheduler=scheduler
)
# 绘制训练过程
plot_training(history)
# 保存最终模型
torch.save({
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'class_names': class_names
}, args.save_path)
print(f"Final model saved as '{args.save_path}'")
if __name__ == "__main__":
# 设备配置
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {device}")
main()
训练结果:
> python train_monkeypox_model.py --data_dir ./data/monkeypox --num_epochs 20
Using device: cuda
Class names: ['Monkeypox', 'Normal']
Training images: 1713
Validation images: 429
Epoch 12/20
----------
train: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 54/54 [00:17<00:00, 3.05it/s]
train Loss: 0.5974 Acc: 0.7064
val: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 14/14 [00:13<00:00, 1.02it/s]
val Loss: 0.5452 Acc: 0.7716
New best model saved with accuracy: 0.7716


















 163
163

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









