




 本文深入探讨了SparkStreaming的工作原理,包括Driver、Executor、Receiver的角色与功能,以及DStream的生成与操作。通过实例展示了如何构建SparkStreamingContext,处理来自Kafka的数据流,实现数据过滤与聚合。此外,还讨论了SparkStreaming的性能参数与调优策略。
本文深入探讨了SparkStreaming的工作原理,包括Driver、Executor、Receiver的角色与功能,以及DStream的生成与操作。通过实例展示了如何构建SparkStreamingContext,处理来自Kafka的数据流,实现数据过滤与聚合。此外,还讨论了SparkStreaming的性能参数与调优策略。
SparkStreaming原理
- 客户端提交作业后启动Driver,Driver是spark作业的Master。
- 每个作业包含多个Executor,每个Executor以线程的方式运行task,Spark Streaming至少包含一个receiver task。
- Receiver接收数据后生成Block,并把BlockId汇报给Driver,然后备份到另外一个Executor上。
- ReceiverTracker维护Reciver汇报的BlockId。
- Driver定时启动JobGenerator,根据Dstream的关系生成逻辑RDD,然后创建Jobset,交给JobScheduler。
- JobScheduler负责调度Jobset,交给DAGScheduler,DAGScheduler根据逻辑RDD,生成相应的Stages,每个stage包含一到多个task。
- TaskScheduler负责把task调度到Executor上,并维护task的运行状态。
- 当tasks,stages,jobset完成后,单个batch才算完成
SparkStreaming相关的API
典型使用
- 构建一个Spark StreamingContext
time_step = 300##单位为秒。
sc = SparkContext(appName='gdl')
ssc = StreamingContext(sc, time_step)
payload = []
zkQuorum = '10.5.144.164:2181,10.5.144.165:2181,10.5.144.166:2181'
topic1 = 'GDL'
gdlStream = KafkaUtils.createStream(ssc,zkQuorum,"falcon1",{topic1:12})
pos_dict = {}
lines_gdl_ori = gdlStream.map(lambda x: json.loads(x[1]))
lines_gdl = lines_gdl_ori.filter(lambda x: (x.get('adept') in airport_list or x.get('adest') in airport_list) and x.get('type') == 'GDL' and x.get('lon') not in['', None] and x.get('lat') not in ['', None])
lines_adsb_p = lines_adsb.map(lambda x: (x.get('flightno'), find_selected_airport((float(x.get('lon')), float(x.get('lat'))), pos_dict))).filter(lambda x: x[1] is not None).map(lambda x: (x[1], x[0], 1))
datapoint_count_adsb = lines_adsb_p.map(lambda x: (x[0], 1)).reduceByKey(lambda a, b: a + b)
flight_count_adsb = lines_adsb_p.map(lambda x: (x[0], x[1])).groupByKey().mapValues(lambda x: list(set(x))).mapValues(lambda x: len(x))
datapoint_count_adsb.foreachRDD(process_datapoint_to_payload)
flight_count_adsb.foreachRDD(process_flightcount_to_payload)
ssc.start()
DStream
DStream是一组连续的RDD序列,这些RDD中的元素的类型是一样的。DStream是一个时间上连续接收数据但是接受到的数据按照指定的时间(batchInterval)间隔切片,每个batchInterval都会构造一个RDD一个batch产生一个RDD,因此,Spark Streaming实质上是根据batchInterval切分出来的RDD串,想象成糖葫芦,每个山楂就是一个batchInterval形成的RDD。

MAP
源 DStream的每个元素通过函数func返回一个新的DStream。
filter
在源DSTREAM上选择Func函数返回仅为true的元素,最终返回一个新的DSTREAM 。
union
返回一个包含源DStream与其他 DStream的元素合并后的新DSTREAM。
groupByKeyAndWindow
和groupByKey类似,只不过是在一个滑动窗口上完成该操作。
性能参数
在SparkStreaming的监控UI上,我们可以看到下列指标。下面的APP每五分钟处理一个batch,每个batch的处理时间一般52S。是正常的。如果batch的处理时间过高,那么就会导致batch积压,无法正常处理。
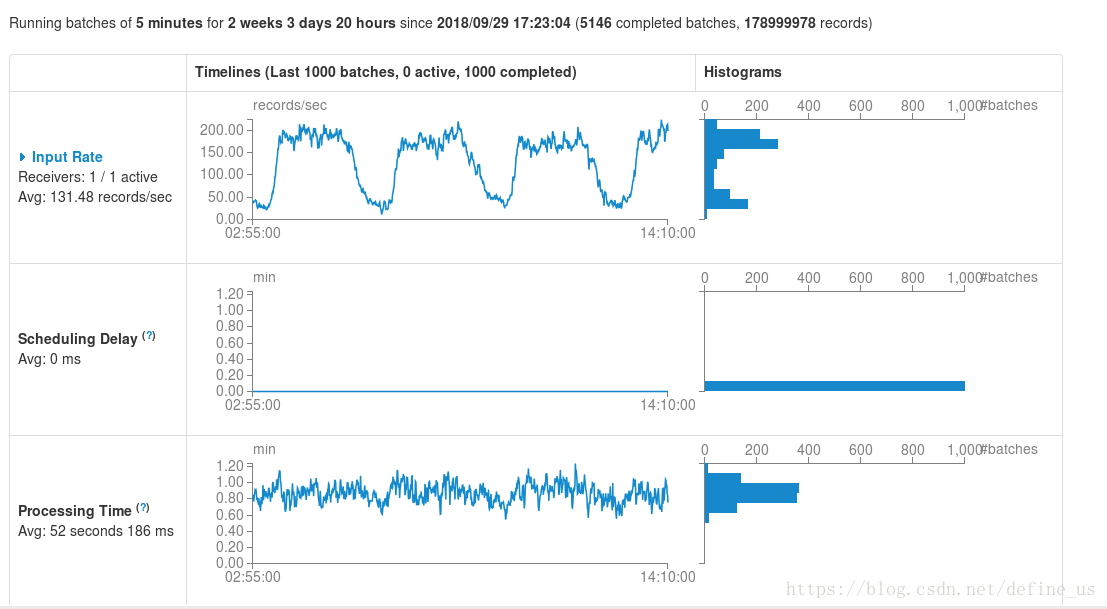
Scheduling Delay :一个batch从入队到出队的延迟。
每个Batch Duration时间去提交一次job,如果job的处理时间超过Batch Duration,会使得job无法按时提交,随着时间推移,越来越多的作业被拖延,最后导致整个Streaming作业被阻塞,无法做到实时处理数据

















 1346
1346

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









