



 本文介绍Druid数据库连接池的配置方法及其工作原理。通过Spring配置DruidDataSource,实现数据库连接的管理和优化。文章还深入探讨了Druid的SPI机制及Filter链设计模式,展示如何通过自定义Filter增强其功能。
本文介绍Druid数据库连接池的配置方法及其工作原理。通过Spring配置DruidDataSource,实现数据库连接的管理和优化。文章还深入探讨了Druid的SPI机制及Filter链设计模式,展示如何通过自定义Filter增强其功能。
数据库连接池
如果不使用数据库连接池,调用链路应该如下
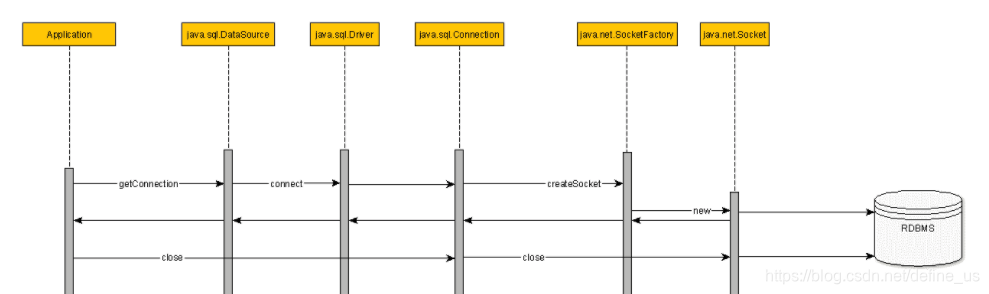
使用后如下
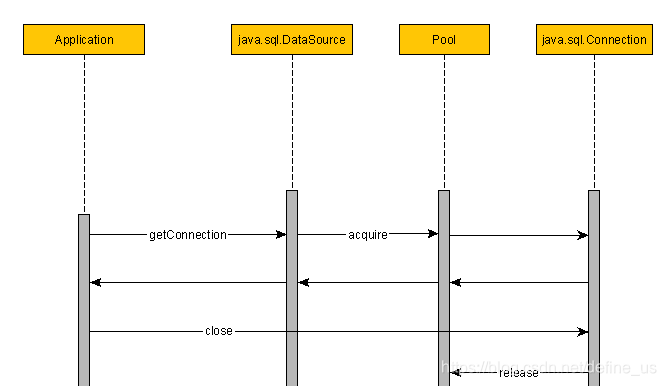
druid
此druid和海量大数据分析的那个druid可完全不是一个东西。
Druid支持所有JDBC兼容的数据库,包括Oracle、MySql、Derby、Postgresql、SQL Server、H2等等。
首先,你要在Spring中配置一个datasorce。
<bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource" init-method="init" destroy-method="close">
<!-- 基本属性 url、user、password -->
<property name="url" value="${jdbc_url}" />
<property name="username" value="${jdbc_user}" />
<property name="password" value="${jdbc_password}" />
<!-- 配置初始化大小、最小、最大 -->
<property name="initialSize" value="1" />
<property name="minIdle" value="1" />
<property name="maxActive" value="20" />
<!-- 配置获取连接等待超时的时间 -->
<property name="maxWait" value="60000" />
<!-- 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒 -->
<property name="timeBetweenEvictionRunsMillis" value="60000" />
<!-- 配置一个连接在池中最小生存的时间,单位是毫秒 -->
<property name="minEvictableIdleTimeMillis" value="300000" />
<property name="validationQuery" value="SELECT 'x'" />
<property name="testWhileIdle" value="true" />
<property name="testOnBorrow" value="false" />
<property name="testOnReturn" value="false" />
<!-- 打开PSCache,并且指定每个连接上PSCache的大小 -->
<property name="poolPreparedStatements" value="true" />
<property name="maxPoolPreparedStatementPerConnectionSize" value="20" />
<!-- 配置监控统计拦截的filters,去掉后监控界面sql无法统计 -->
<property name="filters" value="stat" />
</bean>
代码里,首先你要建设一个DruidDataSource。DruidDataSource实现了java自带的DataSource接口。
然后,自然就是老套路
connection conn = datasource.getconnection();
preparedstatement stmt = conn.preparestatement(ddl.tostring());
for (int i = 0; i < count; ++i) {
stmt.setint(i + 1, i);
}
stmt.execute();
stmt.close();
conn.close();
原理
DRUID也是使用了java的SPI机制,com.alibaba.druid.proxy.DruidDriver类实现了java.sql.Driver接口。
Druid的Filter
filter-chain设计模式给druid所带来的可扩展性。
继承FilterEventAdapter类。这是一个抽象类,虽然不包含必须实现的覆盖的抽象方法。一般被覆盖的抽象方法是
protected void statementCreateAfter(StatementProxy statement) {
}
protected void statementPrepareAfter(PreparedStatementProxy statement) {
}
protected void statementPrepareCallAfter(CallableStatementProxy statement) {
}
protected void resultSetOpenAfter(ResultSetProxy resultSet) {
}
protected void statementExecuteUpdateBefore(StatementProxy statement, String sql) {
}
protected void statementExecuteUpdateAfter(StatementProxy statement, String sql, int updateCount) {
}
protected void statementExecuteQueryBefore(StatementProxy statement, String sql) {
}
protected void statementExecuteQueryAfter(StatementProxy statement, String sql, ResultSetProxy resultSet) {
}
protected void statementExecuteBefore(StatementProxy statement, String sql) {
}
protected void statementExecuteAfter(StatementProxy statement, String sql, boolean result) {
}
protected void statementExecuteBatchBefore(StatementProxy statement) {
}
protected void statementExecuteBatchAfter(StatementProxy statement, int[] result) {
}
protected void statement_executeErrorAfter(StatementProxy statement, String sql, Throwable error) {
}
例如,创建一个filter如下,在sql被执行后就会执行输出haha
public class TestFilter extends FilterEventAdapter{
@Override
protected void statementExecuteAfter(StatementProxy statement, String sql, boolean result) {
System.out.println("haha");
super.statementExecuteAfter(statement, sql, result);
}
}
接下来就是把这个filter配置到druiddatasource里就行了,无论用代码的方式还是用spring的方式。

















 276
276

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









