







 本文介绍了使用Python爬取豆瓣图书信息时如何处理分页问题,从第一页(start=0)到第二页(start=25),并强调了在列表操作中避免空列表错误的方法。同时,讲解了字符串处理技巧,如添加'r'防止转义字符、使用strip()和replace()函数清理字符串,确保数据的准确性和整洁性。
本文介绍了使用Python爬取豆瓣图书信息时如何处理分页问题,从第一页(start=0)到第二页(start=25),并强调了在列表操作中避免空列表错误的方法。同时,讲解了字符串处理技巧,如添加'r'防止转义字符、使用strip()和replace()函数清理字符串,确保数据的准确性和整洁性。
代码如下:
# -*- coding: utf-8 -*
import requests,time
from lxml import etree
c = 0
for n in range(0,2):
url='https://book.douban.com/top250?start={}'.format(n*25)
data=requests.get(url).text
s=etree.HTML(data)
books=s.xpath('//*[@id="content"]/div/div[1]/div/table')
for i in books:
title=i.xpath('./tr/td[2]/div[1]/a/@title')[0]
score=i.xpath('./tr/td[2]/div[2]/span[2]/text()')[0]
simple=i.xpath('./tr/td[2]/p[2]/span/text()')
num=i.xpath('./tr/td[2]/div[2]/span[3]/text()')[0].strip('(').strip().strip(')').replace('\n','').strip()
num2 = i.xpath('./tr/td[2]/div[2]/span[3]/text()')[0]
href=i.xpath('./tr/td[2]/div[1]/a/@href')[0]
time.sleep(2)
c=c+1
if len(simple)>0:
print ('TOP',c,':','书名:',title,'<-->','分数:',score,'<-->','一句话简介:',simple[0],'<-->','评价人数:',num,'<-->','链接:',href)
print ('num2的值是:',num2)
else:
print ('TOP',c,':','书名:',title,'<-->','分数:',score,'<-->','一句话简介:','无','<-->','评价人数:',num,'<-->','链接:',href)
print('num2的值是:', num2)结果如下:
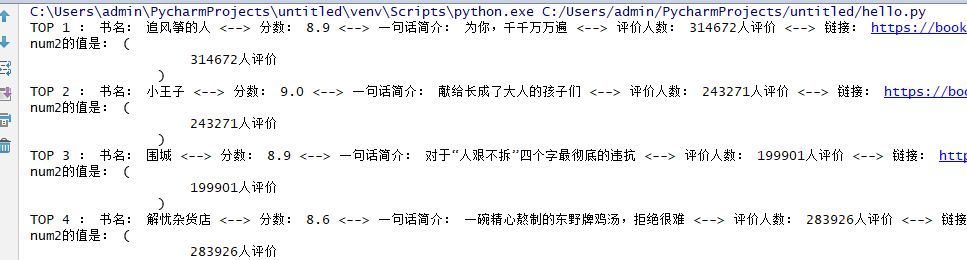
小结:
1、注意:第一页是https://book.douban.com/top250?start=0 ,第二页是https://book.douban.com/top250?start=25 ,所以前两页是range(0,2);
2、列表为空的时候,用索引[0]是会报错的,所以这里用len()判断;
3、路径前面最好加个r,可以防止字符串的转义字符生效;‘\’用在转义字符前面,也可以防止转义字符生效;
4、strip()函数用于移除字符串头部与尾部指定的字符(默认为空格或换行符);replace()函数用于替换,replace('\n','')指将换行符替换成空值;
最后为什么还要加个strip()呢?是为了去除换行符后面的空格,看下num2便知。

















 923
923

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









