







 本文介绍了一个简单的Python爬虫实例,用于抓取豆瓣Top250图书页面的部分信息,包括如何使用XPath解析网页元素并获取指定的数据。
本文介绍了一个简单的Python爬虫实例,用于抓取豆瓣Top250图书页面的部分信息,包括如何使用XPath解析网页元素并获取指定的数据。
代码如下:
# -*- coding: utf-8 -*
import requests,time
from lxml import etree
url='https://book.douban.com/top250'
html=requests.get(url).text
s=etree.HTML(html)
title1=s.xpath('//*[@id="content"]/div/div[1]/div/table[1]/tr/td[2]/div[1]/a/text()')[0]
title2=s.xpath('normalize-space(//*[@id="content"]/div/div[1]/div/table[1]/tr/td[2]/div[1]/a/text())')
title3=s.xpath('//*[@id="content"]/div/div[1]/div/table[1]/tr/td[2]/div[1]/a/@title')
print ('用[0]来表示:',title1)
print ('用normalize-space()来表示:',title2)
print ('用 @+属性名 来表示:',title3)
for i in title3:
print ('用遍历来表示:',i)结果如下:
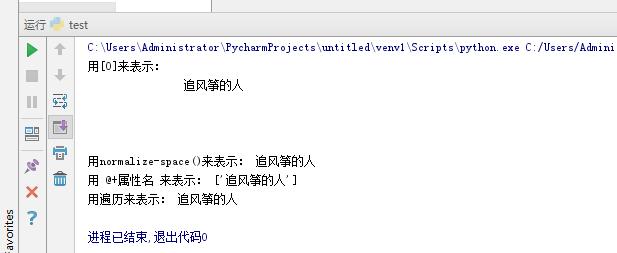
小结:
1、 / 绝对路径 ,// 相对路径 ;
2、‘/@+属性名’,获取属性值 ;‘[@id=""]’,获取特定属性=‘’的路径;
3、 使用xpath到得的都是一个个的节点对象,即列表;
normalize-space()或加[0],两者都是取的第一个值,但normalize-space()会去掉转义字符,注意:[0]如果列表为空则会报错;
因为此url获取的列表只有零个或一个值,故也可用循环遍历列表的方法,来获取值。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









