




 文章详细介绍了Flink的计算模型、内存管理,包括JobManager和TaskManager的内存配置,以及如何处理数据倾斜。此外,还讨论了Flink与Spark的对比,以及如何使用水印处理延迟数据。文章还涵盖了Flink的分布式缓存机制、状态管理和一致性保证,以及如何应对反压和数据延迟。
文章详细介绍了Flink的计算模型、内存管理,包括JobManager和TaskManager的内存配置,以及如何处理数据倾斜。此外,还讨论了Flink与Spark的对比,以及如何使用水印处理延迟数据。文章还涵盖了Flink的分布式缓存机制、状态管理和一致性保证,以及如何应对反压和数据延迟。
文章目录
- 模型分层
- 计算模型
- 分布式缓存
- 管理内存
- `window`出现的数据倾斜
- 使用聚合函数处理热点数据
- `Flink` `vs` `Spark`
- 泛型擦除
- 集群角色
- 部署模式
- `Yarn` 运行模式
- `Flink on K8s`
- 执行图有哪几种
- 分区
- 任务槽`Task slot`
- 并行度
- 窗口理解
- `Flink SQL` 是如何实现的
- 海量数据的高效去重
- `Flink`中`Task`如何做到数据交换
- `Flink`设置并行度的方式
- 水印`watermark`
- 分布式快照
- 状态管理
- 状态机制
- 状态后端的选择
- 状态的过期机制
- 状态的区别
- 状态的TTL
- 状态过期数据处理
- `Flink/Spark/Hive SQL`的执行原理
- 反压(背压)
- 一致性的保持
- 延迟数据的处理
- 双流`join`
- 数据倾斜
- `Flink`任务延时高,如何入手
- 算子链
- `Flink CEP`编程中当状态没有到达的时候会将数据保存在哪里
- aggregate 和 process 计算区别
- 序列化
- 任务的并行度的评估
- 合理评估任务最大并行度
- 保障实时指标的质量
- CDC
- 保存点
模型分层
-
RuntimeFlink程序的最底层入口。提供了基础的核心接口完成流、状态、事件、时间等复杂操作,功能灵活。 -
DataStream API面向开发者,基于
Runtime层的抽象。 -
Table API统一
DataStream/DataSet,抽象成带有Schema信息的表结构. 通过表操作和注册表完成数据计算。 -
SQL面向数据分析和开发人员,抽象为
SQL操作。
计算模型
source支持多数据源输入transformation数据的转换过程sink数据的输出

分布式缓存
目的是在本地读取文件,并把他放在TaskManager节点中,防止task重复拉取
object Distribute_cache {
def main(args: Array[String]): Unit = {
val env = ExecutionEnvironment.getExecutionEnvironment
//1"开启分布式缓存
val path = "hdfs://hadoop01:9000/score"
env.registerCachedFile(path , "Distribute_cache")
//3:开始进行关联操作
DS<String>.map(new MyJoinmap()).print()
}
}
class MyJoinmap() extends RichMapFunction[Clazz , ArrayBuffer[INFO]]{
private var myLine = new ListBuffer[String]
override def open(parameters: Configuration): Unit = {
val file = getRuntimeContext.getDistributedCache.getFile("Distribute_cache")
}
//在map函数下进行关联操作
override def map(value: Clazz): ArrayBuffer[INFO] = {
}
}
管理内存
Flink是将对象都序列化到一个预分配的内存块上,并且大量使用了堆外内存。如果处理数据超过了内存大小,会使部分数据存储到硬盘上。同时Flink为了直接操作二进制数据而实现了自己的序列换框架。
-
堆内内存
Flink程序在创建对象后,JVM会在堆内内存中分配一定大小的空间,创建Class对象并返回对象引用,Flink保存对象引用,同时记录占用的内存信息。 -
堆外内存
堆外内存其底层调用
基于C的JDK Unsafe类方法,通过指针直接进行内存的操作,包括内存空间的申请、使用、删除释放等
JobManager 内存管理
# JobManager总进程内存
jobmanager.memory.process.size:
# 作业管理器的 JVM 堆内存大小
jobmanager.memory.heap.size:
#作业管理器的堆外内存大小。此选项涵盖所有堆外内存使用。
jobmanager.memory.off-heap.size:
在这里插入图片描述
TaskManager 内存
TaskManager内存包含JVM堆内内存、JVM堆外内存以及JVM MetaData内存三大块。
JVM堆内内存又包含Framework Heap(框架堆内存)和Task Heap(任务堆内存)。JVM堆外内存包含Memory memory托管内存,用于保存排序、结果缓存、状态后端数据等。Direct Memory直接内存Framework Off-Heap Memory:Flink框架的堆外内存。Task Off-Heap:Task的堆外内存Network Memory:网络内存
/ tm的框架堆内内存
taskmanager.memory.framework.heap.size=
// tm的任务堆内内存
taskmanager.memory.task.heap.size
// Flink管理的原生托管内存
taskmanager.memory.managed.size=
taskmanager.memory.managed.fraction=
// Flink 框架堆外内存
taskmanager.memory.framework.off-heap.size=
// Task 堆外内存
taskmanager.memory.task.off-heap.size=
// 网络数据交换所使用的堆外内存大小
taskmanager.memory.network.min: 64mb
taskmanager.memory.network.max: 1gb
taskmanager.memory.network.fraction: 0.1
window出现的数据倾斜
window数据倾斜是指:数据在不同的窗口内堆积的数据量相差过多,本质上还是不同的Task的数据相差太大。
- 在数据进入窗口之前对数据进行预聚合,减少进入窗口的数据量;
- 重新设计窗口聚合的
key,使不同的窗口的数据量尽量相同; - 使用再平衡的算子,如
rebalance,将数据再次打散,均匀发送到下游。
使用聚合函数处理热点数据
- 对热点数据单独处理,可以使热点数据不会影响正常的服务;
- 对热点数据拆分聚合,也是单独对热点数据单独处理;
- 上游的
slot将数据汇聚成一个批次发送到下一个slot中,可以将该批次值设置大点。
Flink vs Spark
Spark |
Flink |
|---|---|
| RDD模型 | 基于数据流,基于事件驱动 |
| 微批处理(一个批完成后才能处理下一个) | 无界实时流处理(事件在一个节点处理完后发往下一个节点) |
| 处理时间 | 事件时间,插入时间,处理时间,水印 |
| 窗口必须是批的整数倍 | 窗口类型多 |
| 没有状态 | 有状态 |
| 没有流式SQL | 有流式SQL |
| 提供统一的批处理和流处理API,支持高级编程语言和SQL | 均提供统一的批处理和流处理API,支持高级编程语言和SQL |
| 都基于内存计算,速度快 | 都基于内存计算,速度快 |
| 都支持Exactly-once一致性 | 都支持Exactly-once一致性 |
| 都有完善的故障恢复机制 | 都有完善的故障恢复机制 |
泛型擦除
Flink具有一个类型提取系统,可以分析函数的输入和返回类型,自动获取类型信息,从而获得对应的序列化器和反序列化器。由于泛型擦除的存在,在某些情况下,自动提取的信息不够精细,需要采取显式提供类型信息,才能使应用程序正常工作。
集群角色
-
**客户端
Client:**代码由客户端获取并装换,然后提交给JobManager; -
JobManager:对作业进行调度管理,对作业转换为任务,并将任务发送给TaskManager, 对失败任务做出反应,协调checkpoint -
**
TaskManager:**处理数据任务,缓存和交换数据流(数据从一个tm传到另一个tm)- **
task slot:**资源调度的最小单位,并发/并行处理 task 的数量,一个task slot中可以执行多个算子。
- **
-
**
RecourceManager:**负责集群中的资源提供、回收、分配、管理Task slots -
Dispatcher:提交Flink应用程序执行,为每个提交的作业启动一个新的JobMaster -
**
JobMaster:**管理单个JobGraph的执行,每个作业都有自己的JobMaster
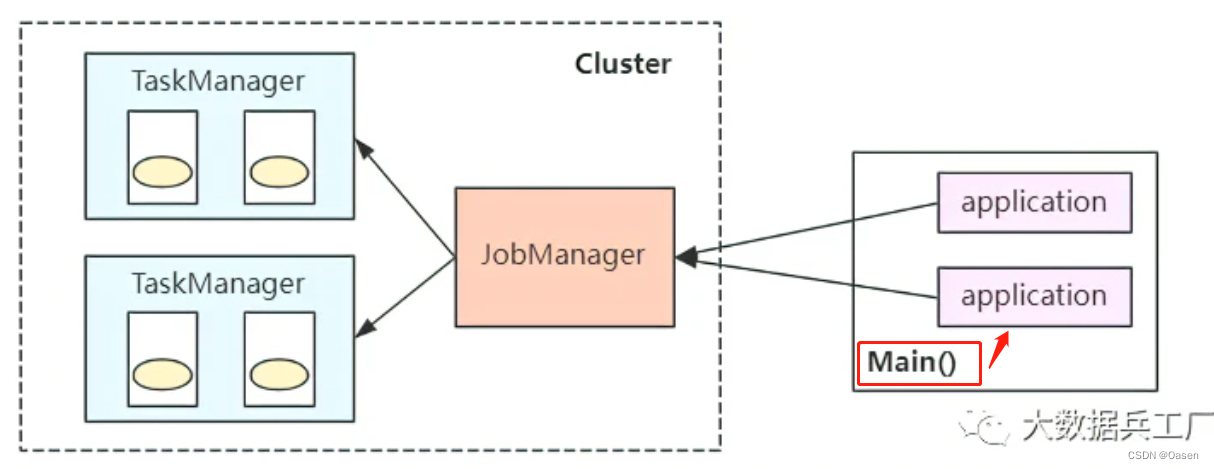
部署模式
-
会话模式
所有任务都共享集群中
JobManager,所有任务都会竞争集群的资源-
适用于短周期、小容量的任务
-
减少资源和线程的切换
-
共享一个
jobManager,jobmanager压力大
bin/flink run -c com.wc.SocketStreamWordCount FlinkTutorial-1.0.jar -
-
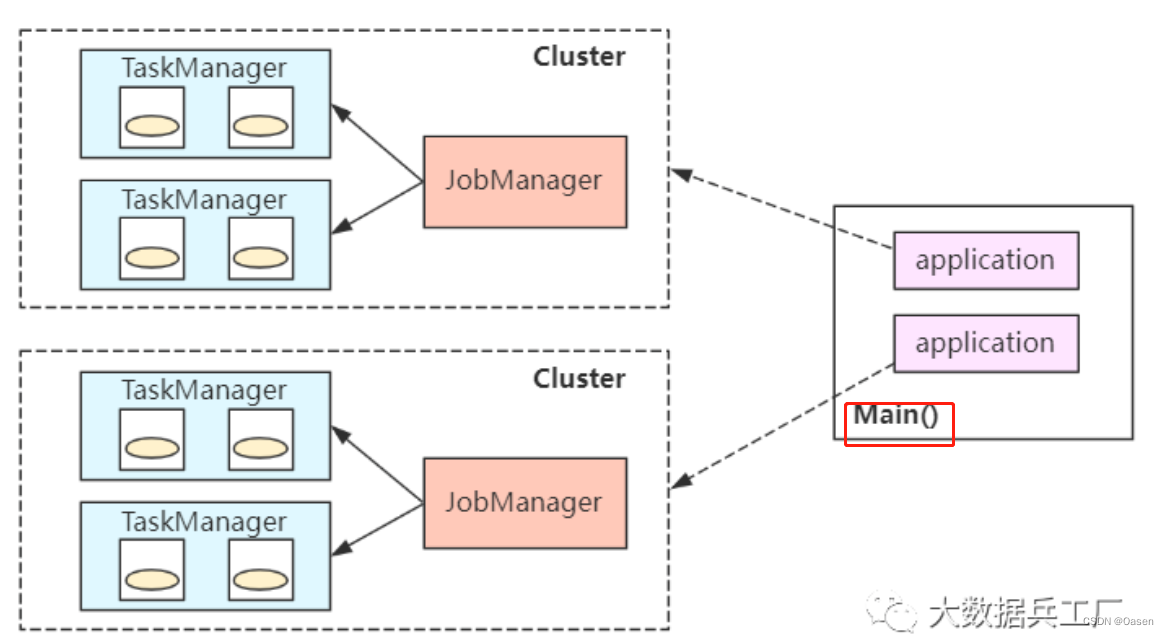
单作业模式
每个任务都会启动一个单独的集群,集群之间相互独立。
- 每个任务完成后销毁,最大限度保障资源隔离
- 每个
Job均衡分发自身的JobManager,单独进行job的调度和执行 - 每个
job均维护一个集群,启动、销毁以及资源请求消耗时间长,因此比较适用于长时间的任务执行
bin/flink run -d -t yarn-per-job -c com.wc.SocketStreamWordCount FlinkTutorial-1.0.jar
-
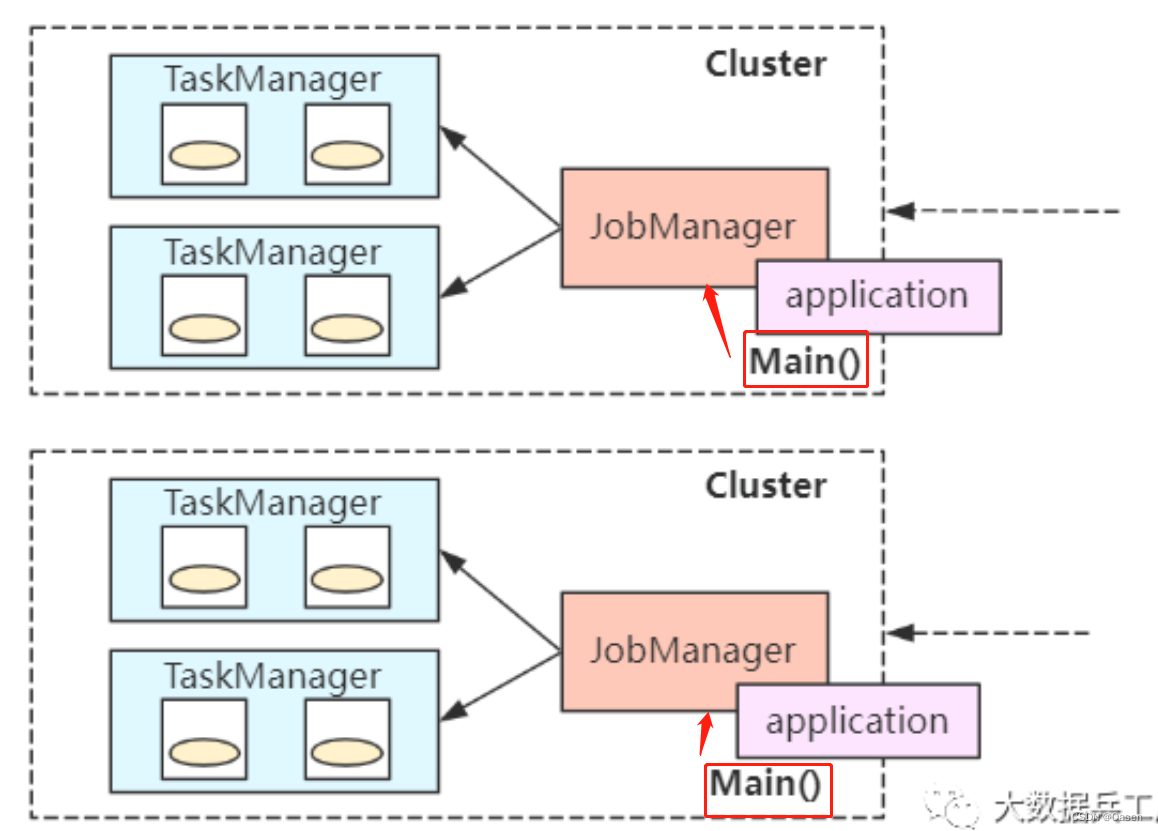
应用模式
每个任务都会启动一个
jobManager,只是**Application与JobManager合二为一。Main方法此时在JobManager中执行**。bin/flink run-application -t yarn-application -c com.wc.SocketStreamWordCount FlinkTutorial-1.0.jar
Yarn 运行模式
YARN上运行过程是:客户端Client把Flink应用程序提交给YARN的ResourceManager, YARN的ResourceManager会向NM申请容器,启动JobManager和TaskManager的实例,从而启动集群。Flink会根据运行在JobManager上的作业所需要的Slot数量动态分配TaskManager资源。
- 通过脚本启动执行。客户端
Client基于用户代码,生成流图(StreamGraph),再在JobManager中生成工作图(JobGraph), 同时将任务提交给ResourceManager; ResourceManager选择一个启动NM,启动ApplicaitonMaster;ApplicationMaster启动JobManager, 并将工作图(JobGraph)生成执行图(ExecutionGraph);JobManager向ResourceManager申请资源,资源被封装在slot槽;ResourceManager启动一定数量的TaskManager,分配一定的slotTaskManager向JobManager注册;JobManager将要执行的任务分发到TaskManager,执行任务。
Flink on K8s
k8s是一个强大的,可移植的高性能的容器编排工具。这里的容器指的是docker容器化技术,它通过将执行环境和配置打包成镜像服务,在任务环境下快速部署docker容器,提供基础的环境服务。解决之前部署服务速度慢,迁移难,高成本的问题。
k8s提供了一套完整地容器化编排解决方案,实现容器发现和调度,负载均衡,弹性扩容,数据卷挂载等服务。
Flink on k8s与Flink on yarn提交比较类似,TaskManager和JobManager等组件变成了k8s pod角色
K8s集群根据提交的配置文件启动K8sMaster和TaskManager(K8s Pod对象)- 依次启动
Flink的JobManager、JobMaster、Deploy和K8sRM进程(K8s Pod对象);过程中完成slots请求和ExecutionGraph的
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2555
2555

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









