







本质
通过重复使⽤简单的基础块来构建深度模型。
VGG块
组成规律是:连续使⽤数个相同的填充为1、窗⼝形状为3 * 3的卷积层后接上⼀个步幅为2、窗⼝形状为2 * 2的最⼤池化层。卷积层保持输⼊的⾼和宽不变,⽽池化层则对其减半。
VGG这种⾼和宽减半以及通道翻倍的设计使得多数卷积层都有相同的模型参数尺⼨和计算复杂度。
VGG网络
由卷积层模块后接全连接层模块构成。变量conv_arch 指定了每个VGG块⾥卷积层个数和输⼊输出通道数。
本文中的网络有5个卷积块,前2块使⽤单卷积层,⽽后3块使⽤双卷积层。第⼀块的输⼊输出通道分别是1(因为下⾯要使⽤的Fashion-MNIST数据的通道数为1)和64,之后每次对输出通道数翻倍,直到变为512。因为这个⽹络使⽤了8个卷积层和3个全连接层,所以经常被称为VGG-11。
获取数据和训练模型
在Fashion-MNIST数据集上进⾏训练。
以下为完整代码。
import time
import torch
from torch import nn, optim
import torch.nn.functional as F
import sys
sys.path.append("..")
import d2lzh_pytorch as d2l
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
def vgg_block(num_convs, in_channels, out_channels):
blk = []
for i in range(num_convs):
if i == 0:
blk.append(nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1))
else:
blk.append(nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1))
blk.append(nn.ReLU())
blk.append(nn.MaxPool2d(kernel_size=2, stride=2))
return nn.Sequential(*blk)
def vgg(conv_arch, fc_features, fc_hidden_units=4096):
net = nn.Sequential()
for i, (num_convs, in_channels, out_channels) in enumerate(conv_arch):
net.add_module("vgg_block_" + str(i + 1), vgg_block(num_convs, in_channels, out_channels))
net.add_module("fc", nn.Sequential(d2l.FlattenLayer(), nn.Linear(fc_features, fc_hidden_units), nn.ReLU(),
nn.Dropout(0.5), nn.Linear(fc_hidden_units, fc_hidden_units), nn.ReLU(),
nn.Dropout(0.5), nn.Linear(fc_hidden_units, 10)))
return net
conv_arch = ((1, 1, 64), (1, 64, 128), (2, 128, 256), (2, 256, 512), (2, 512, 512))
fc_features = 512 * 7 * 7 # c * w * h
fc_hidden_units = 4096 # 任意
ratio = 16
small_conv_arch = [(1, 1, 64 // ratio), (1, 64 // ratio, 128 // ratio),
(2, 128 // ratio, 256 // ratio),
(2, 256 // ratio, 512 // ratio), (2, 512 // ratio,
512 // ratio)]
net = vgg(small_conv_arch, fc_features // ratio, fc_hidden_units //ratio)
# X = torch.rand(1, 1, 224, 224)
# # named_children获取⼀级⼦模块及其名字(named_modules会返回所有⼦模块,包括⼦模块的⼦模块)
# for name, blk in net.named_children():
# X = blk(X)
# print(name, 'output shape: ', X.shape)
batch_size = 64
# 如出现“out of memory”的报错信息,可减⼩batch_size或resize
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size,
resize=224)
lr, num_epochs = 0.001, 5
optimizer = torch.optim.Adam(net.parameters(), lr=lr)
d2l.train_ch5(net, train_iter, test_iter, batch_size, optimizer,
device, num_epochs)
结果
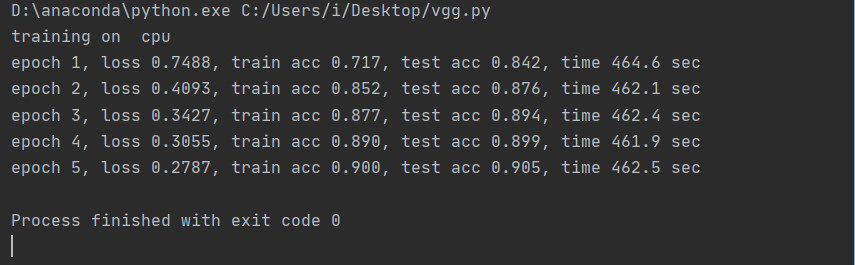
只能在cpu上跑的痛有谁懂/(ㄒoㄒ)/~~
没有gpu太煎熬了,快来个富婆包养我吧(❁´◡`❁)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









