



 本文介绍了TF-IDF算法的基本概念,包括詞頻(TF)和逆向文件頻率(IDF)的計算方法,以及如何利用這些度量來确定文件中詞語的重要性。TF-IDF算法能夠有效过滤掉常见詞語,突出文件中真正關鍵的内容。
本文介绍了TF-IDF算法的基本概念,包括詞頻(TF)和逆向文件頻率(IDF)的計算方法,以及如何利用這些度量來确定文件中詞語的重要性。TF-IDF算法能夠有效过滤掉常见詞語,突出文件中真正關鍵的内容。
在一份給定的文件裡,詞頻(term frequency,TF)指的是某一個給定的詞語在該文件中出現的次數。這個數字通常會被正規化,以防止它偏向長的文件。(同一個詞語在長文件裡可能會比短文件有更高的詞頻,而不管該詞語重要與否。)對於在某一特定文件裡的詞語 ti 來說,它的重要性可表示為:
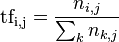
以上式子中 ni,j 是該詞在文件dj中的出現次數,而分母則是在文件dj中所有字詞的出現次數之和。
逆向文件頻率(inverse document frequency,IDF)是一個詞語普遍重要性的度量。某一特定詞語的IDF,可以由總文件數目除以包含該詞語之文件的數目,再將得到的商取對數得到:

其中
- |D|:語料庫中的文件總數
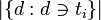 :包含詞語ti的文件數目(即
:包含詞語ti的文件數目(即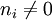 的文件數目)
的文件數目)
然後

某一特定文件內的高詞語頻率,以及該詞語在整個文件集合中的低文件頻率,可以產生出高權重的TF-IDF。因此,TF-IDF傾向於過濾掉常見的詞語,保留重要的詞語。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









