




《Hive面试避坑指南:从SQL优化到调优实战,斩获Offer的硬核技巧》
1. 为什么要使用 HIVE? HIVE 的优缺点?Hive的作用是什么?
在没有hive之前,我们得手写MR相关代码,来分析数据,有了HIVE后改成通用语言SQL分析数据。
a. 优势
- 提供类SQL查询,容易上手,开发方便;
- 封装了很多方法,尽量避免了开发MapReduce程序,减少成本;
b. 劣势
- 适用于处理大规模数据,小数据的处理没有优势;
- 执行延迟较高,适合用于数据分析,不适合对时效性要求较高的场景。
2. HIVE建表
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...)
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
[TBLPROPERTIES (property_name=property_value, ...)]
[AS select_statement | like table_name]
3. HIVE 内部表和外部表的区别
| 分类 | 英文名称 | 建表 | 建表数据指向 | 删除表 |
|---|---|---|---|---|
| 内部表 | Managed Table | CREATE TABLE | hive-site.xml中的 hive.metastore.warehouse.dir 默认: hdfs:///user/hive/warehouse/db/table/ 将数据移动到数据仓库指向的路径 | 会直接删除元数据(metadata)、存储数据(HDFS/S3/OSS等) |
| 外部表 | External Table | CREATE EXTERNAL TABLE | 仅记录数据所在的路径, 不对数据的位置做任何改变 | 仅仅删除元数据 |
基于对比,企业一般使用外部表防止误删数据。
4. HIVE 自定义函数
- 分类
| 分类 | 名称 | 特点 | 实现 | HIVE内置 |
|---|---|---|---|---|
| UDF | 用户自定义函数 user defined function | 一对一的输入输出 | 继承org.apache.hadoop.hive.ql.exec.UDF重写evaluate | 大部分都是 |
| UDTF | 用户自定义表生成函数 user defined table-generate function | 一对多的输入输出 | 继承org.apache.hadoop.hive.ql.udf.generic.GenericUDF类,重写 initlizer、getdisplay、evaluate 方法 | lateral view explode |
| UDAF | 用户自定义聚合函数 user defined aggregate function | 多对一的输入输出 | 继承org.apache.hadoop.hive.ql.exec.UDAF;包含一个或多个嵌套的的实现了 org.apache.hadoop.hive.ql.exec.UDAFEvaluator的静态类的 init、iterate、terminatePartial merge、terminate的方法 | count sum 等聚合函数 |
- 加载自定义函数
a. session会话
-- 1. 比如写了个转大写函数com.XXX.hive.toUpUDF,将编写的udf的jar包上传到服务器上的HDFS文件系统中
-- 2. 进入到hive客户端,执行下面命令:将jar包添加到hive的class path中
add jar hdfs:///hiveudf/udf.jar
-- 3.创建一个临时函数名,要跟上面hive在同一个session里面:
create temporary function toUp as 'com.XXX.hive.toUpUDF';
-- 4.检查函数是否创建成功
show functions;
-- 5. 测试功能
select toUp('ZhangSan');
-- 6. 删除函数
drop temporary function if exists toUp;
b. 长期有效
# 1. 将编写的udf的jar包上传到服务器上的HDFS文件系统中
# 2. 在hive的安装目录的bin目录下创建一个配置文件,文件名:.hiverc
# 3. vi ./bin/.hiverc,输入内容如下:
add jar hdfs:///hiveudf/udf.jar;
create temporary function toUp as 'com.XXX.hive.toUpUDF';
HIVE分析工具的计算引擎
一、主流计算引擎介绍
MapReduce 引擎
- 原理:将 HiveQL 转换为多阶段 MapReduce 任务,基于磁盘进行分布式计算,通过 Shuffle 阶段实现数据交换。
- 特点:
- 高容错性:依赖中间结果的磁盘持久化,适合处理超大规模数据。
- 高延迟:频繁的磁盘 I/O 操作导致性能较低,适用于离线批处理任务(如周/月指标统计)。
Tez 引擎
- 原理:采用 DAG(有向无环图)模型优化任务执行流程,通过减少中间结果的落盘次数提升效率。
- 特点:
- 性能提升:相比 MapReduce,查询延迟降低 30%-50%,适用于交互式查询和实时分析。
- 内存依赖:计算过程依赖内存,存在 OOM(内存溢出)风险。
Spark 引擎
- 原理:基于内存计算和 RDD(弹性分布式数据集)模型,通过 DAG 调度优化任务执行,支持多种数据处理模式(批处理、流处理、机器学习)。
- 特点:
- 高效计算:内存计算显著提升迭代算法和复杂分析任务的性能(如机器学习场景)。
- 灵活性与扩展性:支持 SQL、Scala、Python 等多种接口,适用于每天定时任务和实时数据处理。
二、核心对比
| 维度 | MapReduce | Tez | Spark |
|---|---|---|---|
| 执行模型 | 多阶段MR任务 | DAG 任务图 | 内存计算 + DAG 调度 |
| 性能 | 低(基于磁盘) | 中高(减少落盘) | 高(内存优先) |
| 延迟 | 高(分钟级及以上) | 中(秒到分钟级) | 低(秒级,支持实时) |
| 容错性 | 高(依赖磁盘持久化) | 中(部分依赖内存) | 中(依赖 RDD 血缘机制) |
| 适用场景 | 大规模离线批处理 | 交互式查询、中等延迟任务 | 实时分析、复杂计算任务 |
| 资源管理 | 稳定但资源利用率低 | 较高资源利用率 | 高资源消耗,需精细调优 |
三、引擎选择建议
- MapReduce:适用于对延迟不敏感、数据量极大的离线任务(如历史数据清洗)。
- Tez:适合需快速响应的临时调试或交互式查询场景(如数据分析师临时探索)。
- Spark:推荐用于日常定时任务、机器学习模型训练或需低延迟的实时分析(如用户行为实时统计)
HIVE架构与执行流程
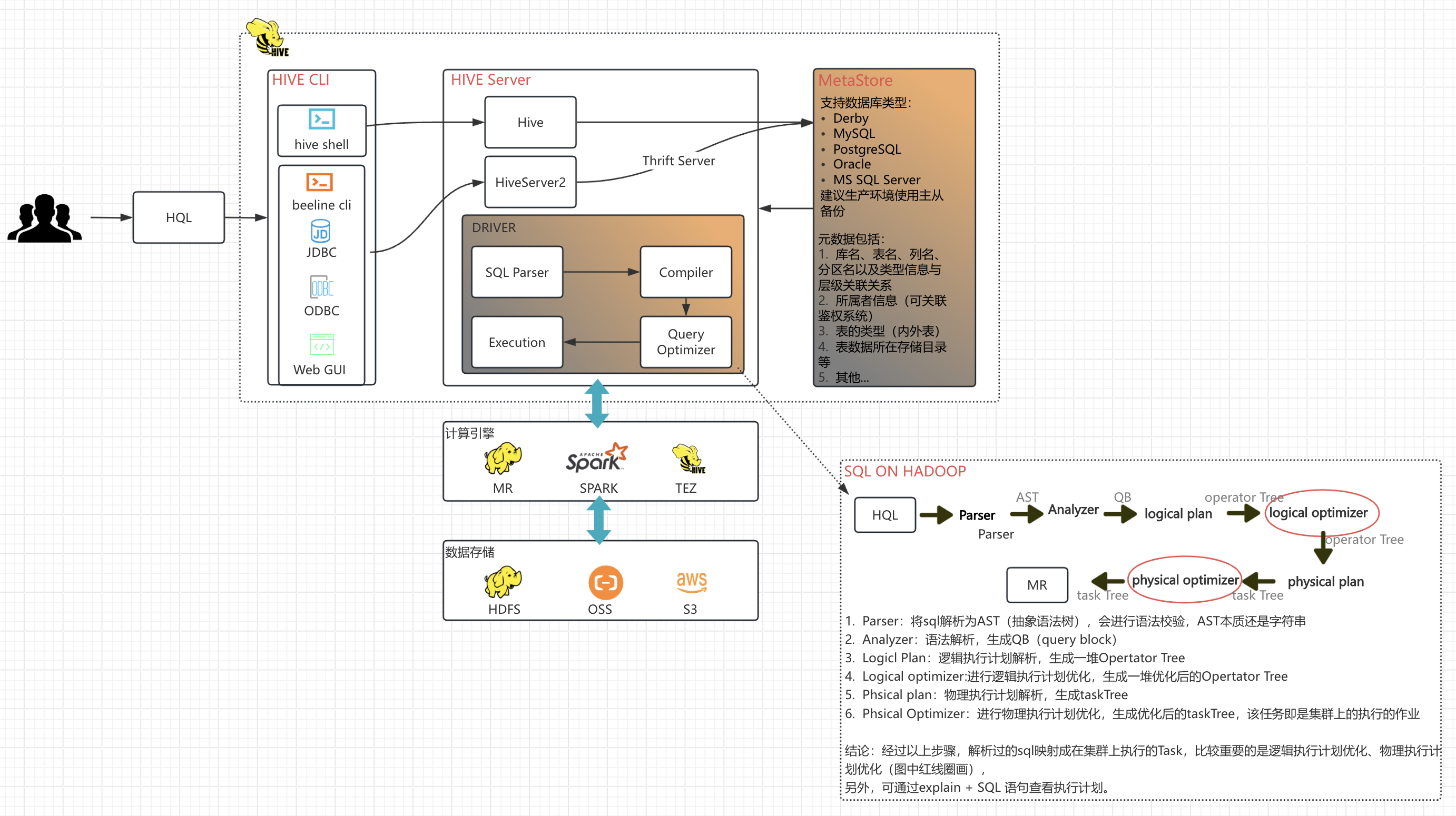
HIVE性能调优
HIVE函数
开窗函数分类与总结
HIVE join分类与总结
union与union all
- union:将多个结果合并为一个,且结果去重且排序
- union all:将多个结果合并为一个,且结果不去重不排序
总结,确认数据没有重复的情况下,可直接使用union all降低任务运行时间
order by、sort by、distribute by、cluster by
| order by | sort by | distribute by | cluster by | |
|---|---|---|---|---|
| 作用 | 对输入进行全局排序,全局有序 | Reduce 内有序 | 控制Map的输出在Reduce中的划分 | 相当于sort by 与 distribute by的结合 |
| 缺点 | 只有一个Reduce,输入较大时,耗时较长 | 不能保证全局有序 | 划分,不排序 | 只做升序,没有desc |
写在最后
该文档会逐步完善,大家可以在评论区写上你感兴趣的方向,博主工作之余会去完善。


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









