




原文:消息队列
一、什么是消息的持久化?
简单来说就是将数据存入磁盘,而不是存在内存中随服务器重启断开而消失,使数据能够永久保存。
常见的持久化方式

二、消息队列的分发策略
MQ消息队列有如下几个角色
1:生产者
2:存储消息
3:消费者
那么生产者生成消息以后,MQ进行存储,消费者是如何获取消息的呢?一般获取数据的方式无外乎推(push)或者拉(pull)两种方式,典型的git就有推拉机制,我们发送的http请求就是一种典型的拉取数据库数据返回的过程。而消息队列MQ是一种推送的过程,而这些推机制会适用到很多的业务场景也有很多对应推机制策略。
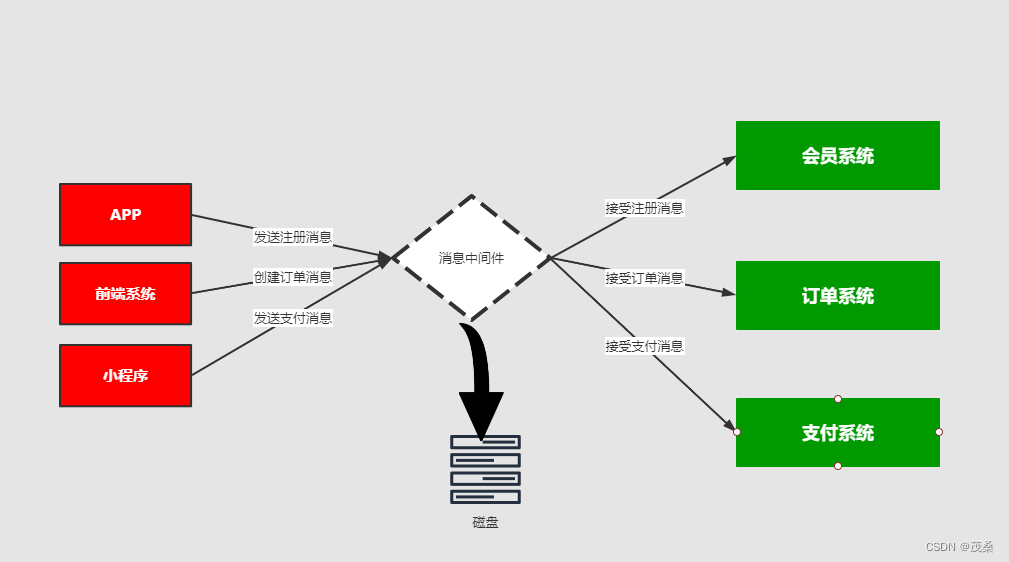
消息分发:
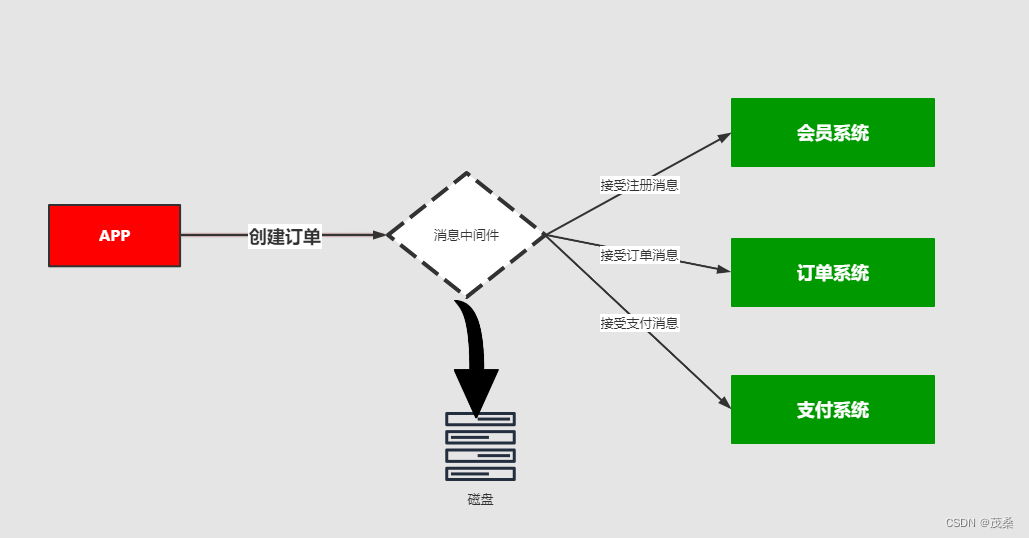
比如我在APP上下了一个订单,我们的系统和服务很多,我们如何得知这个消息被那个系统或者那些服务或者系统进行消费,那这个时候就需要一个分发的策略。
这就需要消费策略。或者称之为消费的方法论。
失败重试:
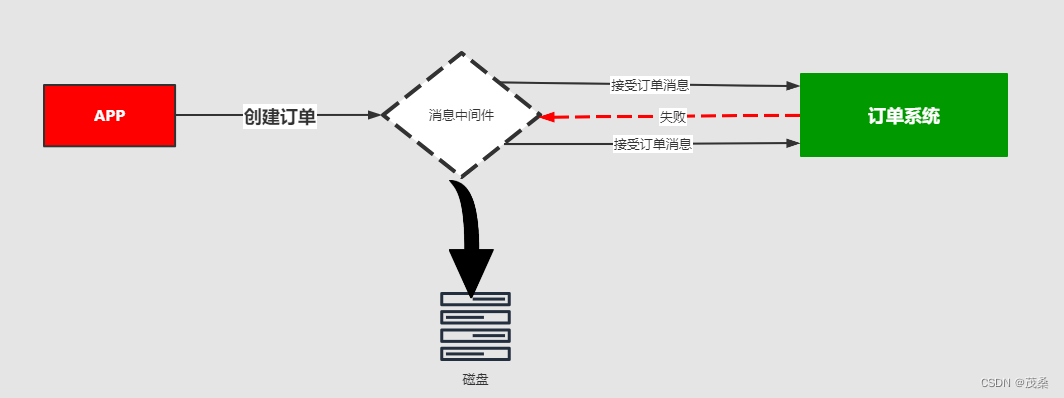
在发送消息的过程中可能会出现异常,或者网络的抖动,故障等等因为造成消息的无法消费,
比如用户在下订单,消费MQ接受,订单系统出现故障,导致用户支付失败,
那么这个时候就需要消息中间件就必须支持消息重试机制策略。
也就是支持:出现问题和故障的情况下,消息不丢失还可以进行重发。
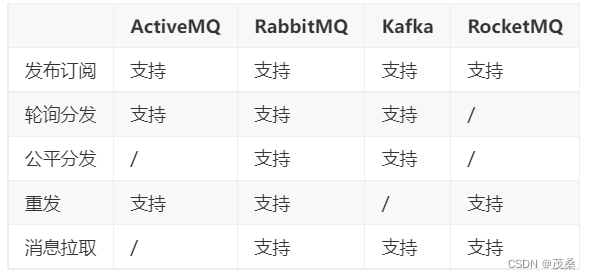
不同消息中间件支持的分发策略:
三、什么是高可用
所谓高可用:是指产品在规定的条件和规定的时刻或时间内处于可执行规定功能状态的能力。(就是承载能力,承载力越高,可用性越高)
当业务量增加时,请求也过大,一台消息中间件服务器的会触及硬件(CPU,内存,磁盘)的极限,一台消息服务器你已经无法满足业务的需求,所以消息中间件必须支持集群部署。来达到高可用的目的。
消息高可用各种集群的底层逻辑:
1:要么消息共享,
2:要么消息同步
3:要么元数据共享
3.1 Master-slave主从共享数据的部署方式
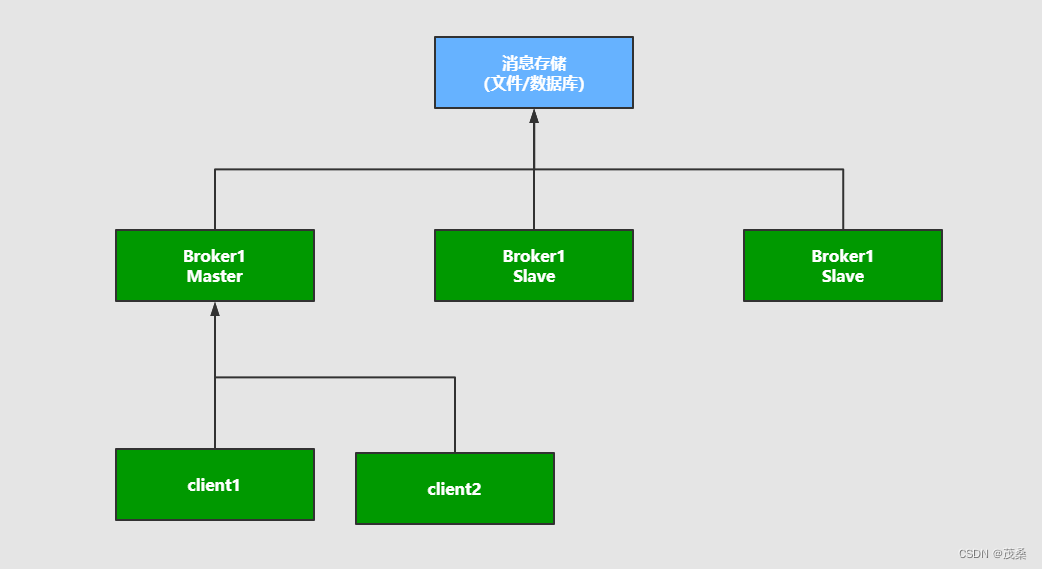
解说:生产者将消息发送到Master节点,Master节点负责写入,所有的从节点都连接这个消息队列共享这块数据区域,所有的消息在一块。
Master挂掉,slave节点也可以继续服务。从而形成高可用
缺点:一旦Master节点挂掉,那么生产者就无法写入消息了,这种模式常在小项目中用到
3.2 Master- slave主从同步部署方式
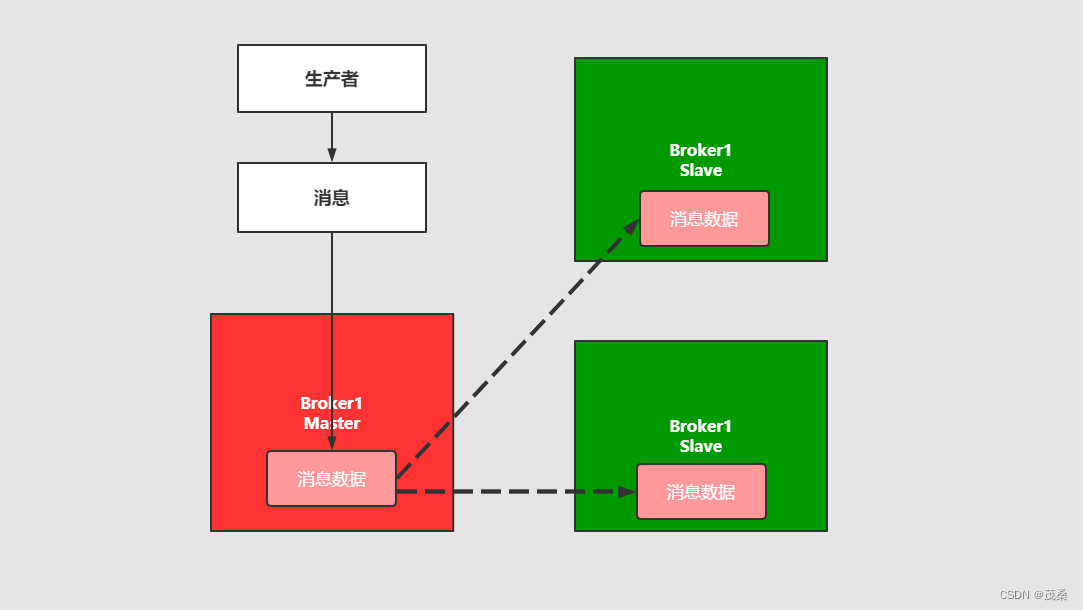
解释:这种模式写入消息同样在Master主节点上,但是主节点会同步数据到slave节点形成副本,和zookeeper或者redis主从机制很类同。消息被保存在不同节点里。
这样可以达到负载均衡的效果,如果消费者有多个,消费者就可以去不同的节点就行消费。在后续的rabbtmq中会有使用。
缺点:1、消息的拷贝和同步会占用很大的带宽和网络资源,最好是主从节点都部署在同一个机房(局域网)内,加快网速与保证带宽
2、同样的master节点挂了,无法写入
3.3 多主集群同步部署模式
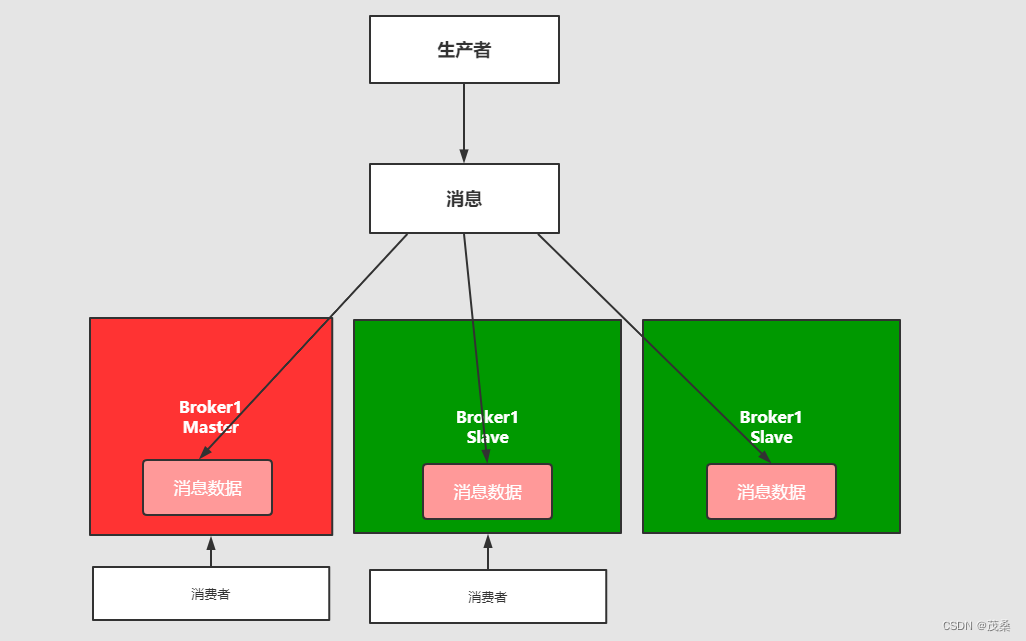
解释:多写多读,和上面的区别不是特别的大,但是它的写入可以往任意节点去写入。
3.4 多主集群转发部署模式
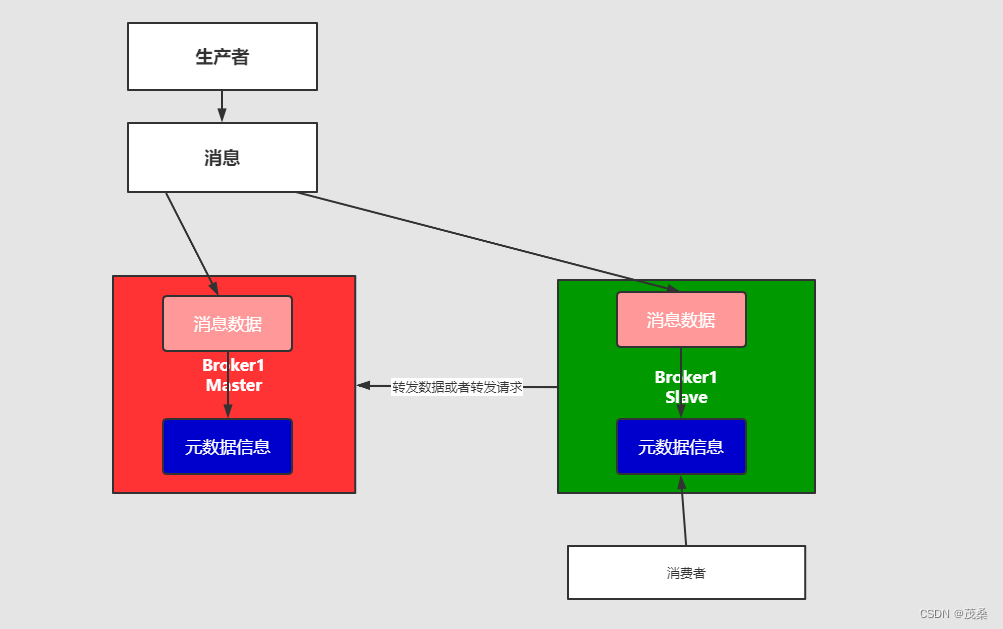
解释:如果你插入的数据是broker-1中,元数据信息会存储数据的相关描述和记录存放的位置(队列)。
它会对描述信息也就是元数据信息就行同步,如果消费者在broker-2中进行消费,
发现自己节点没有对应的消息,可以从对应的元数据信息中去查询,然后返回对应的消息信息,
场景:比如买火车票或者黄牛买演唱会门票,比如第一个黄牛有顾客说要买的演唱会门票,但是没有但是他会去联系其他的黄牛询问,如果有就返回。
优点:占用资源较少,比较可靠
3.5 Master-slave与Breoker-cluster组合的方案
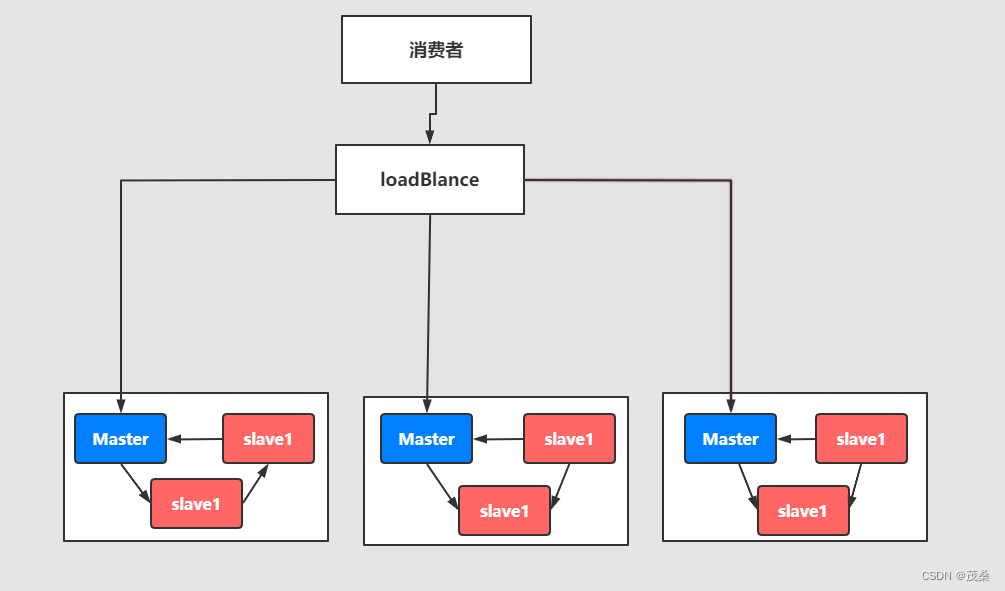
解释:实现多主多从的热备机制来完成消息的高可用以及数据的热备机制,在生产规模达到一定的阶段的时候,这种使用的频率比较高。
四、什么是高可靠机制
所谓高可靠是指:是指系统可以无故障低持续运行,比如一个系统突然崩溃,报错,异常等等并不影响线上业务的正常运行,出错的几率极低,就称之为:高可靠。就是一种“容错性”
在高并发的业务场景中,如果不能保证系统的高可靠,那造成的隐患和损失是非常严重的。
如何保证中间件消息的可靠性呢?可以从两个方面考虑:
1:消息的传输:通过协议来保证系统间数据解析的正确性。
2:消息的存储可靠:通过持久化来保证消息的可靠性。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









