<think>好的,我需要帮助用户使用YOLOv1和GDAL库进行舰船目标检测。首先,我需要回顾YOLOv1的基本结构和GDAL库的功能。YOLOv1是单阶段检测模型,将图像划分为网格,每个网格预测边界框和类别概率。GDAL主要用于处理地理空间数据,比如遥感影像,这在舰船检测中很常见。
用户的需求可能涉及到处理遥感图像,这些图像通常是高分辨率的,可能包含多个波段。GDAL可以帮助读取这些数据,并进行预处理,比如裁剪、调整大小、波段转换等。但YOLOv1输入通常是RGB图像,所以可能需要将多波段影像转换为三通道。
接下来,我需要考虑数据集的问题。用户可能需要标注舰船的位置,生成对应的标签文件,YOLO格式通常是每个图像对应的txt文件,包含类别和归一化的坐标。GDAL可以辅助读取地理坐标信息,帮助在后续处理中定位目标的位置。
然后是模型搭建部分。YOLOv1的结构包括卷积层、全连接层,输出是一个7x7x(5*B + C)的张量。这里B是边界框数量,C是类别数。对于舰船检测,可能C=1。需要确保代码正确实现这一结构,可能使用PyTorch或Keras。
训练过程中需要注意输入数据的处理,比如尺寸调整到448x448,数据增强(翻转、旋转等),以及损失函数的实现,包括坐标误差、置信度误差和分类误差的组合。
在推理阶段,使用训练好的模型检测新图像,然后利用GDAL将检测结果映射回地理坐标系,可能生成矢量文件(如Shapefile)来保存检测到的舰船位置,便于GIS软件中使用。
可能遇到的问题包括小目标检测,遥感影像中的舰船可能较小,YOLOv1的网格划分可能不够密集,导致漏检。用户可能需要调整网格大小或采用多尺度检测。此外,GDAL处理大尺寸影像时的内存管理也需要注意,可能需要分块处理。
用户可能需要具体的代码示例,比如如何使用GDAL读取影像,预处理,然后输入到YOLOv1模型中,以及后处理部分。同时,需要指导如何安装GDAL库,因为它的安装有时会有依赖问题,建议使用conda或预编译的包。
最后,生成的相关问题需要考虑用户可能的后续需求,比如性能优化、处理不同传感器数据、模型训练技巧等。</think>### 使用YOLOv1和GDAL实现舰船目标检测的步骤指南
#### 一、环境准备
1. **安装GDAL库**(处理遥感影像)
```bash
conda install -c conda-forge gdal # 推荐使用Anaconda环境
```
2. **深度学习框架选择**(以PyTorch实现YOLOv1为例)
```bash
pip install torch torchvision
```
#### 二、数据处理流程
1. **GDAL影像预处理**
```python
from osgeo import gdal
def read_tif(file_path):
dataset = gdal.Open(file_path)
width = dataset.RasterXSize
height = dataset.RasterYSize
data = dataset.ReadAsArray() # 获取多波段数据
return data.transpose(1,2,0) # 转换为HWC格式
```
2. **波段处理与归一化**
```python
# 示例:将16位遥感影像转换为8位RGB
import cv2
def normalize_band(band):
return cv2.normalize(band, None, 0, 255, cv2.NORM_MINMAX).astype('uint8')
```
#### 三、YOLOv1模型实现关键点
1. **网络结构定义(PyTorch版)**
```python
class YOLOv1(nn.Module):
def __init__(self, S=7, B=2, C=1):
super().__init__()
self.conv_layers = nn.Sequential(
nn.Conv2d(3, 64, 7, stride=2),
nn.MaxPool2d(2),
# ... 完整结构参考原论文
nn.Flatten(),
nn.Linear(1024*S*S, 4096),
nn.Linear(4096, S*S*(5*B + C))
)
def forward(self, x):
return self.conv_layers(x).view(-1, S, S, 5*B + C)
```
2. **损失函数实现**
```python
def yolo_loss(pred, target):
coord_mask = target[..., 4] > 0 # 物体存在标记
noobj_mask = ~coord_mask
# 坐标损失
coord_loss = F.mse_loss(pred[..., :2][coord_mask],
target[..., :2][coord_mask])
# 尺寸平方根损失
size_loss = F.mse_loss(torch.sqrt(pred[..., 2:4][coord_mask]),
torch.sqrt(target[..., 2:4][coord_mask]))
# 置信度损失
conf_loss = F.binary_cross_entropy(pred[..., 4][coord_mask],
target[..., 4][coord_mask])
# 无目标区域损失
noobj_loss = F.binary_cross_entropy(pred[..., 4][noobj_mask],
target[..., 4][noobj_mask])
return 5*coord_loss + 5*size_loss + conf_loss + 0.5*noobj_loss
```
#### 四、地理坐标转换关键代码
```python
def pixel2geo(col, row, transform):
"""将预测框坐标转换为地理坐标"""
x = transform[0] + col * transform[1]
y = transform[3] + row * transform[5]
return (x, y)
```
#### 五、实际部署建议
1. **针对小目标优化**
- 将原始448x448输入改为672x672
- 在最后三个卷积层后添加SPP模块
```python
class SPP(nn.Module):
def __init__(self):
super().__init__()
self.pool5 = nn.MaxPool2d(5,1,padding=2)
self.pool9 = nn.MaxPool2d(9,1,padding=4)
def forward(self, x):
return torch.cat([x, self.pool5(x), self.pool9(x)], dim=1)
```
2. **GDAL多线程处理**
```python
from multiprocessing import Pool
def process_tile(args):
"""分块处理大尺寸遥感影像"""
tile, transform = args
detections = model(tile)
return convert_to_geo(detections, transform)
with Pool(4) as p:
results = p.map(process_tile, tiles)
```
#### 六、性能提升技巧
1. **数据增强策略**
```python
from albumentations import (
HorizontalFlip, RandomRotate90,
RandomSizedCrop, Compose
)
train_aug = Compose([
RandomSizedCrop((300, 448), 448, 448),
HorizontalFlip(p=0.5),
RandomRotate90(p=0.5),
])
```
2. **混合精度训练**
```python
scaler = torch.cuda.amp.GradScaler()
with torch.cuda.amp.autocast():
outputs = model(inputs)
loss = criterion(outputs, targets)
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
```








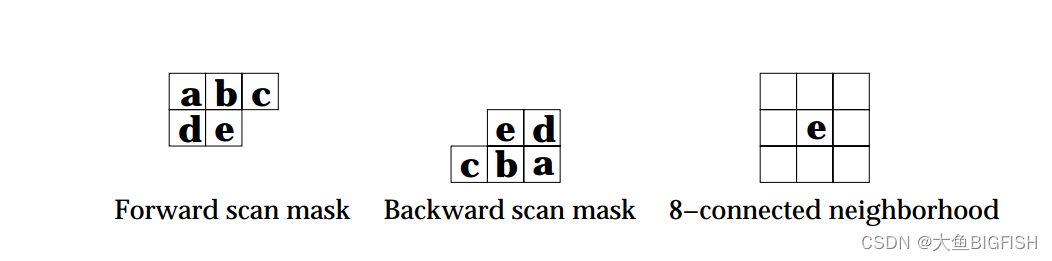
 本文介绍了基于扫描线的Suzuki算法用于标记图像连接区域,并讨论了如何通过决策树优化算法效率。此外,提出了使用数组替代决策树的Union-Find操作以及移除扁平化操作以提升算法性能。文章详细阐述了修改过程,并提供了实现代码和效果展示。
本文介绍了基于扫描线的Suzuki算法用于标记图像连接区域,并讨论了如何通过决策树优化算法效率。此外,提出了使用数组替代决策树的Union-Find操作以及移除扁平化操作以提升算法性能。文章详细阐述了修改过程,并提供了实现代码和效果展示。
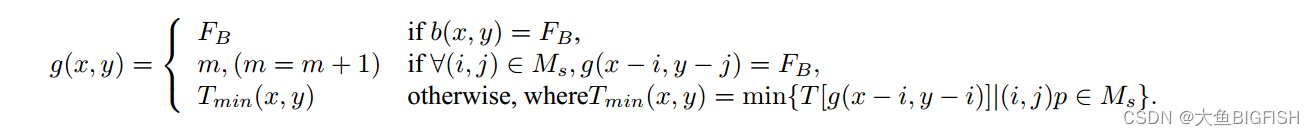

 订阅专栏 解锁全文
订阅专栏 解锁全文


















 229
229

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











