




 本文详细介绍了如何使用Python和NumPy库实现K-means聚类算法,并通过一个具体的数据集进行测试,展示了从数据准备到算法应用及结果展示的全过程。
本文详细介绍了如何使用Python和NumPy库实现K-means聚类算法,并通过一个具体的数据集进行测试,展示了从数据准备到算法应用及结果展示的全过程。
1. 进入命令行
pip3 install numpy
2. 测试k-means
from numpy import *
import operator
def createDataSet():
group = array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]])
labels = ['A','A','B','B']
return group, labels
def classify0(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0]
diffMat = tile(inX, (dataSetSize,1)) - dataSet ##矩阵相减
sqDiffMat = diffMat**2 ##差值平方
sqDistances = sqDiffMat.sum(axis=1)
sortedDistIndicies = sqDistances.argsort() ##对距离进行排序
classCount={} ##新建字典,字典常用于排序
for i in range(k): ##对字典进行排序,字典以labal作为key,数值为kmean的数值
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)
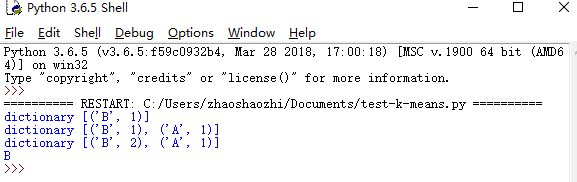
print("dictionary",sortedClassCount)
return sortedClassCount[0][0]
group,labels=createDataSet()
result=classify0([0.5,0.5], group, labels, 3)
print(result) ##显示结果
3. 查看结果

















 10万+
10万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









