




1. 背景
-
在大规模分布式推理系统中,使用 模型并行(如 Tensor Parallelism、Pipeline Parallelism、MoE expert parallelism)时,KV cache 和中间激活信息需要在多个 GPU/节点之间频繁传输,这些技术依赖于节点间和节点内、低延迟、高吞吐量的通信;
-
Prefill(预填充)阶段和 Decode(解码)阶段的 GPU 运行在不同设备上,它们之间也需要高效传输 KV Cache。
2. NIXL 是什么?
NVIDIA Inference Transfer Library (NIXL) 是 NVIDIA 提供的一个专门为推理优化的通信库,目标是 高吞吐、低延迟,并 屏蔽底层硬件差异
在一个复杂的分布式系统中,设备可能使用不同类型的内存和网络,NIXL 的优势:
-
将所有存储都抽象为 "memory segments"(内存段),不管底层是 HBM、DRAM、SSD、对象存储,它都统一视为“内存的一部分”,实现 透明传输和调用;
-
抽象了底层差异,提供统一的接口,支持不同的网络协议(如 NVLink、InfiniBand、RoCE、Ethernet)
-
可以在 GPU、主存、文件系统、远程存储之间高效移动数据
总结:NIXL 是专为大规模推理系统设计的数据传输库,支持在异构内存和存储之间高效、低延迟、非阻塞的数据移动,具备跨设备、跨协议、跨存储层的抽象能力。
补充:存储技术可以按照数据保存的持久性分为两大类:
存储技术
│
├─ 易失性存储 (断电数据丢失)
│ ├─ SRAM (静态随机存取存储器)
│ └─ DRAM 家族 (动态随机存取存储器)
│ ├─ 传统DRAM
│ ├─ SDRAM (同步动态随机存取存储器)
│ ├─ DDR SDRAM (双倍数据率SDRAM)
│ │ ├─ DDR1/2/3/4/5
│ │ └─ LPDDR (低功耗DDR)
│ └─ HBM (高带宽内存)
│
└─ 非易失性存储 (断电数据保留)
├─ ROM 家族 (只读存储器)
│ ├─ 掩膜ROM
│ ├─ PROM (可编程ROM)
│ ├─ EPROM (可擦除可编程ROM)
│ └─ EEPROM (电可擦除可编程ROM)
│
├─ Flash 家族
│ ├─ NOR Flash
│ └─ NAND Flash
│
└─ 新型非易失存储
├─ eMMC (嵌入式多媒体卡)
├─ SSD (固态硬盘)
└─ UFS (通用闪存存储)3. NIXL 架构
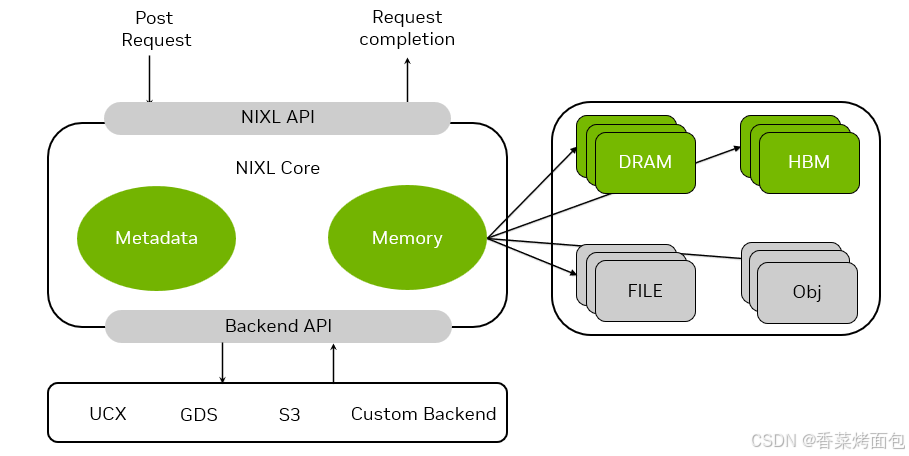
- 用户通过 NIXL API 发起 Post Request,请求处理完后,通过该 API 返回 Request Completion
- NIXL Core 包含 Metadata(元数据) 和 Memory(数据缓冲区)
- Backend API 提供与各种后端的通信接口,支持 UCX、GDS、S3、Custom Backend
- UCX(Unified Communication X),跨节点 GPU/GPU 通信,支持 RDMA、InfiniBand、RoCE
- GDS(GPUDirect Storage),是 NVIDIA 提出的 GPU ↔ 存储设备 之间的 直接数据通路,绕过 CPU 和主存,零拷贝,低延迟
- S3(Simple Storage Service),云对象存储,可访问云/远程对象数据
- 数据从 NIXL Core 中的 Memory 发出给各种异构存储设备:DRAM、HBM、File(本地或远程文件系统)、Obj(Object Storage)对象存储系统
NIXL 特点总结:
-
统一通信 API:跨不同网络协议(如 InfiniBand、RoCE、NVLink)和存储类型,提供统一的接口
-
支持异构内存和存储:无需关心数据当前在哪里(HBM、DRAM、SSD、对象存储等),NIXL 负责调度和高效传输
-
高吞吐、低延迟:支持 非阻塞、非连续(non-contiguous) 的内存传输,实现 KV cache 的快速传输
style="display: none !important;">

















 1149
1149

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









