







kafka
1.kafka的简单介绍
1.1 三种能力
- 它让你发布和订阅数据流. 在这方面他与消息队列或企业级消息系统很像.
- 它让你具有很强容灾性的存储数据流.
- 它让你及时的处理数据流.
1.2 两大类应用
- 搭建可以使数据在系统或应用之间流动的实时数据流管道(pipelines)
- 搭建可以针对流数据实行实时转换或作出相应反应的数据流应用
1.3 前提概念
- Kafka是作为集群,运行在一台或多台服务器上的.
- Kafka集群用主题(topics)来分类别储存数据流(records).
- 每个记录(record)由一个键(key),一个值(value)和一个时间戳(timestamp)组成
1.4 4个核心API
- Producer API负责生产数据流,允许应用程序将记录流发布到一个或多个Kafka主题(topics).
- Consumer API负责使用数据流,允许应用程序订阅一个或多个主题并处理为其生成的数据流.
- Streams API负责处理或转化数据流,允许应用程序充当数据流处理器的角色, 处理来自一个或多个主题的输入数据流,并产生输出数据流到一个或多个输出主题,一次来有效地将输入流转换成输出流.
- Connector API负责将数据流与其他应用或系统结合,允许搭建建和运行可重复使用的生产者或消费者,将Kafka数据主题与现有应用程序或数据系统相连接的。 例如,关系数据库的连接器可能会将表的每个更改的事件,都捕获为一个数据流.

1.5 高可用的保证
在高可用的Kafka集群中:
- 生产者发送到特定主题分区的消息将按照发送的顺序进行追加。 也就是说,如果记录M1由与记录M2相同的制造者发送,并且首先发送M1,则M1将具有比M2更低的偏移并且在日志中较早出现。
- 消费者实例观察到数据的顺序,与它们存储在日志中的顺序一致。
- 对于具有复制因子N的主题,我们将容忍最多N-1个服务器故障,而不会丢失提交到日志的任何记录。
2.核心概念的分析
2.1 主题(Topics)与日志(Logs)
作为Kafka对数据提供的核心抽象,我们先来深度探究一下主题(topic)这个概念 主题是发布的数据流的类别或名称。主题在Kafka中,总是支持多订阅者的; 也就是说,主题可以有零个,一个或多个消费者订阅写到相应主题的数据. 对应每一个主题,Kafka集群会维护像一个如下这样的分区的日志:

每个分区都是是一个有序的,不可变的,并且不断被附加的记录序列,—也就是一个结构化提交日志(commit log).为了保证唯一标性识分区中的每个数据记录,分区中的记录每个都会被分配一个一个叫做*偏移(offset)*顺序的ID号. 通过一个可配置的保留期,Kafka集群会保留所有被发布的数据,不管它们是不是已经被消费者处理. 例如,如果保留期设置为两天,则在发布记录后的两天内,数据都可以被消费,之后它将被丢弃以释放空间。 kafka的性能是不为因为数据量大小而受影响的,因此长时间存储数据并不成问题。[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-555hJOCD-1595948492044)(http://kafka.apache.org/0102/images/log_consumer.png)]事实上,在每个消费者上保留的唯一元数据是消费者在日志中的偏移位置。这个偏移由消费者控制:通常消费者会在读取记录时线性地提高其偏移值(offset++),但实际上,由于偏移位置由消费者控制,它可以以任何顺序来处理数据记录。 例如,消费者可以重置为较旧的偏移量以重新处理来自过去的数据,或者跳过之前的记录,并从“现在”开始消费。 这种特征的组合意味着kafka消费者非常轻量级 — 随意的开启和关闭并不会对其他的消费者有大的影响。例如,您可以使用我们的命令行工具tail来查看任何主题的内容,而无需更改任何现有消费者所消耗的内容。 日志中的分区有几个目的。 首先,它保证日志的扩展性,主题的大小不受单个服务器大小的限制。每个单独的分区大小必须小于托管它的服务器磁盘大小,但主题可能有很多分区,因此它可以处理任意数量的海量数据。第二,它可以作为并行处理的单位 — 这个我们等下再多谈.
2.2 数据的分配(Distribution)
在Kafka集群中,不同分区日志的分布在相应的不同的服务器节点上,每个服务器节点处理自己分区对应的数据和请求。每个分区都会被复制备份到几个(可配置)服务器节点,以实现容错容灾。 分布在不同节点的同一个分区都会有一个服务器节点作为领导者(”leader”)和0个或者多个跟随者(”followers”). 分区的领导者会处理所有的读和写请求,而跟随者只会被动的复制领导者.如果leader挂了, 一个follower会自动变成leader。每个服务器都会作为其一些分区的领导者,但同时也可能作为其他分分区的跟随者,Kafka以此来实现在集群内的负载平衡。
2.3生产者
生产者将数据发布到他们选择的主题。 生产者负责选择要吧数据分配给主题中哪个分区。这可以通过循环方式(round-robin)简单地平衡负载,或者可以根据某些语义分区(例如基于数据中的某些关键字)来完成。我们等一下就来讨论分区的使用!
Load balancing
The producer sends data directly to the broker that is the leader for the partition without any intervening routing tier. To help the producer do this all Kafka nodes can answer a request for metadata about which servers are alive and where the leaders for the partitions of a topic are at any given time to allow the producer to appropriate direct its requests.
The client controls which partition it publishes messages to. This can be done at random, implementing a kind of random load balancing, or it can be done by some semantic partitioning function. We expose the interface for semantic partitioning by allowing the user to specify a key to partition by and using this to hash to a partition (there is also an option to override the partition function if need be). For example if the key chosen was a user id then all data for a given user would be sent to the same partition. This in turn will allow consumers to make locality assumptions about their consumption. This style of partitioning is explicitly designed to allow locality-sensitive processing in consumers.
Asynchronous send
Batching is one of the big drivers of efficiency, and to enable batching the Kafka producer has an asynchronous mode that accumulates data in memory and sends out larger batches in a single request. The batching can be configured to accumulate no more than a fixed number of messages and to wait no longer than some fixed latency bound (say 100 messages or 5 seconds). This allows the accumulation of more bytes to send, and few larger I/O operations on the servers. Since this buffering happens in the client it obviously reduces the durability as any data buffered in memory and not yet sent will be lost in the event of a producer crash.
2.4 消费者
消费者们使用消费群组名称来标注自己,几个消费者共享一个组群名,每一个发布到主题的数据会被传递到每个消费者群组中的一个消费者实例。 消费者实例可以在不同的进程中或不同的机器上。 如果所有的消费者实例具有相同的消费者组,则记录将在所有的消费者实例上有效地负载平衡,每个数据只发到了一个消费者 如果所有的消费者实例都有不同的消费者群体,那么每个记录将被广播给所有的消费者进程,每个数据都发到了所有的消费者。
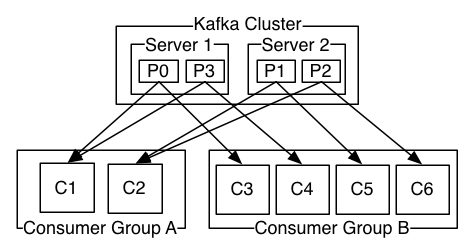
如上图,一个两个服务器节点的Kafka集群, 托管着4个分区(P0-P3),分为两个消费者群. 消费者群A有2个消费者实例,消费者群B有4个. 然而,更常见的是,我们发现主题具有少量的消费者群,每个消费者群代表一个“逻辑订户”。每个组由许多消费者实例组成,保证可扩展性和容错能力。这可以说是“发布-订阅”语义,但用户是一组消费者而不是单个进程。 在Kafka中实现消费的方式,是通过将日志中的分区均分到消费者实例上,以便每个实例在任何时间都是“相应大小的一块”分区的唯一消费者。维护消费者组成员资格的过程,由kafka协议动态处理。 如果新的实例加入组,他们将从组中的其他成员接管一些分区; 如果一个实例消失,其分区将被分发到剩余的实例。 Kafka仅提供单个分区内的记录的顺序,而不是主题中的不同分区之间的总顺序。 每个分区排序结合按键分区,足以满足大多数应用程序的需求。 但是,如果您需要使用总顺序,则可以通过仅具有一个分区的主题来实现,尽管这仅意味着每个消费者组只有一个消费者进程。
Push vs. pull
An initial question we considered is whether consumers should pull data from brokers or brokers should push data to the consumer. In this respect Kafka follows a more traditional design, shared by most messaging systems, where data is pushed to the broker from the producer and pulled from the broker by the consumer.
3. kafka主要业务模块
3.1 Kafka作为消息系统
Kafka的数据流概念与传统的企业消息系统相比如何? 消息系统传统上有两种模式: 队列和发布-订阅. 在队列中,消费者池可以从服务器读取,每条记录都转到其中一个; 在发布订阅中,记录将广播给所有消费者。 这两个模型中的每一个都有优点和缺点。 排队的优点是它允许您在多个消费者实例上分配数据处理,从而可以扩展您的处理。 不幸的是,队列支持多用户,一旦一个进程读取数据就没有了。 发布订阅允许您将数据广播到多个进程,但无法缩放和扩容,因为每个消息都发送给每个订阅用户。kafka消费群体概念概括了这两个概念。 与队列一样,消费者组允许您通过一系列进程(消费者组的成员)来划分处理。 与发布订阅一样,Kafka允许您将消息广播到多个消费者组。 Kafka模型的优点是,每个主题都具有这两个属性,它可以进行缩放处理,也是多用户的,没有必要选择一个而放弃另一个。 kafka也比传统的消息系统有更强大的消息次序保证。 传统队列在服务器上保存顺序的记录,如果多个消费者从队列中消费,则服务器按照存储顺序输出记录。 然而,虽然服务器按顺序输出记录,但是记录被异步传递给消费者,所以它们可能会在不同的消费者处按不确定的顺序到达。 这意味着在并行消耗的情况下,记录的排序丢失。 消息传递系统通常通过使“唯一消费者”的概念只能让一个进程从队列中消费,但这当然意味着处理中没有并行性。 kafka做得更好。通过分区,在一个主题之内的并行处理,Kafka能够在消费者流程池中,即提供排序保证,也负载平衡。这是通过将主题中的分区分配给消费者组中的消费者来实现的,以便每一个分区由组中的一个消费者使用。 通过这样做,我们确保消费者是该分区的唯一读者,并按顺序消耗数据。 由于有许多分区,这仍然平衡了许多消费者实例的负载。 但是请注意,消费者组中的消费者实例个数不能超过分区的个数。
3.2 Kafka作为存储系统
任何允许发布消息,解耦使用消息的消息队列,都在本质上充当传输中途消息的存储系统。 kafka的不同之处在于它是一个很好的存储系统。 写入Kafka的数据写入磁盘并进行复制以进行容错。 Kafka允许生产者等待写入完成的确认,这样在数据完全复制之前,写入是未完成的,并且即使写入服务器失败,也保证持久写入。 Kafka的磁盘结构使用可以很好的扩容,无论您在服务器上是否有50KB或50TB的持久数据,Kafka都能保持稳定的性能。 由于对存储花费了很多精力,并允许客户端控制其读取位置,您可以将Kafka视为,专用于高性能,低延迟的日志存储复制和传播的专用分布式文件系统。
3.3 Kafka用于流数据处理
仅读取,写入和存储数据流是不够的,Kafka的目的是实现流的实时处理。 在Kafka中,流处理器的定义是:任何从输入主题接收数据流,对此输入执行一些处理,并生成持续的数据流道输出主题的组件。 例如,零售应用程序可能会收到销售和出货的输入流,并输出根据该数据计算的重新排序和价格调整的输出流。 当然我们也可以直接用producer and consumer APIs在做简单的出列. 然而对于更复杂的转换,Kafka提供了一个完全集成的Streams API。这允许我们构建应用程序进行更复杂的运算,或者聚合,或将流连接在一起。 该设施有助于解决这种类型的应用程序面临的困难问题:处理无序数据,重新处理输入作为代码更改,执行有状态计算等。 Stream API基于Kafka提供的核心原语构建:它使用生产者和消费者API进行输入,使用Kafka进行有状态存储,并在流处理器实例之间使用相同的组机制来实现容错。
4.kafka的安装
4.1 安装所需环境
- jdk1.8
- zookeeper集群
- zookeeper在kafka集群中的对位和作用
4.2 安装配置
下载—>解压—>配置
简单配置:
- broker.id node在集群中的唯一标示
- log.dirs 数据存放目录,注意目录需存在
- zookeeper.connect zookeeper地址 zk01:2181,zk02:2181,zk03:2181
-------->配置文件分发到其他节点,并修改broker.id
启动集群的命令:
/export/servers/kafka/bin/kafka-server-start.sh /export/servers/kafka/config/server.properties 1>/dev/null 2>&1 &
5.kafka的操作
5.1 客户端操作
1)创建一个订单order的topic
./kafka-topics.sh --create --zookeeper zk01:2181 --replication-factor 2 --partitions 2 --topic order
2)启动生产者生产数据
./kafka-console-producer.sh --broker-list kafka01:9092 --topic order
3)启动消费者消费数据
./kafka-console-consumer.sh --zookeeper zk01:2181 --from-beginning --topic order
./kafka-console-consumer.sh --bootstrap-server hadoop01:9092 --from-beginning --topic order
--from-beginning #上面个命令是早期版本,消费者的消费信息存到zookeeper上,现在推荐下面这种方式,消费者信息存储到本地。同时注意 --from-beginning 的使用
4)查看有哪些topic
./kafka-topics.sh --list --zookeeper hadoop01:2181
5)查看topic的详细信息
./kafka-topics.sh --describe --topic order --zookeeper hadoop1:2181
6)删除topic
./kafka-topics.sh --delete --topic order --zookeeper hadoop1:2181
5.2 Java API操作
5.2.1 引入jar
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>0.11.0.1</version>
</dependency>
5.2.2 生产者
public class OrderProducer {
public static void main(String[] args) throws InterruptedException {
/* 1、连接集群,通过配置文件的方式
* 2、发送数据-topic:order,value
*/
Properties props = new Properties();
props.put("bootstrap.servers", "node01:9092");
props.put("acks", "all");
props.put("retries", 0);
props.put("batch.size", 16384);
props.put("linger.ms", 1);
props.put("buffer.memory", 33554432);
props.put("producer.type", "async")//开启异步模式
props.put("key.serializer",
"org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer",
"org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<String, String>(props);
for (int i = 0; i < 1000; i++) {
// 发送数据 ,需要一个producerRecord对象,最少参数 String topic, V value
kafkaProducer.send(new ProducerRecord<String, String>("order", "订单信息!"+i));
Thread.sleep(100);
}
kafkaProducer.close();
}
}
同步异步和ACK
- 同步异步
在官方文档Producer Configs中有如下:
Property Default Description producer.type sync This parameter specifies whether the messages are sent asynchronously in a background thread. Valid values are (1) async for asynchronous send and (2) sync for synchronous send. By setting the producer to async we allow batching together of requests (which is great for throughput) but open the possibility of a failure of the client machine dropping unsent data. 翻译过来就是:
producer.type的默认值是sync,即同步的方式。这个参数指定了在后台线程中消息的发送方式是同步的还是异步的。如果设置成异步的模式,可以运行生产者以batch的形式push数据,这样会极大的提高broker的性能,但是这样会增加丢失数据的风险。对于异步模式,还有4个配套的参数,如下:
Property Default Description queue.buffering.max.ms 5000 启用异步模式时,producer缓存消息的时间。比如我们设置成1000时,它会缓存1s的数据再一次发送出去,这样可以极大的增加broker吞吐量,但也会造成时效性的降低。 queue.buffering.max.messages 10000 启用异步模式时,producer缓存队列里最大缓存的消息数量,如果超过这个值,producer就会阻塞或者丢掉消息。 queue.enqueue.timeout.ms -1 当达到上面参数时producer会阻塞等待的时间。如果设置为0,buffer队列满时producer不会阻塞,消息直接被丢掉;若设置为-1,producer会被阻塞,不会丢消息。 batch.num.messages 200 启用异步模式时,一个batch缓存的消息数量。达到这个数值时,producer才会发送消息。(每次批量发送的数量) 以batch的方式推送数据可以极大的提高处理效率,kafka producer可以将消息在内存中累计到一定数量后作为一个batch发送请求。batch的数量大小可以通过producer的参数(batch.num.messages)控制。通过增加batch的大小,可以减少网络请求和磁盘IO的次数,当然具体参数设置需要在效率和时效性方面做一个权衡。在比较新的版本中还有batch.size这个参数。
- ACK
producers可以一步的并行向kafka发送消息,但是通常producer在发送完消息之后会得到一个响应,返回的是offset值或者发送过程中遇到的错误。这其中有个非常重要的参数“request.required.acks”,这个参数决定了producer要求leader partition收到确认的副本个数,如果acks设置为0,表示producer不会等待broker的相应,所以,producer无法知道消息是否发生成功,这样有可能导致数据丢失,但同时,acks值为0会得到最大的系统吞吐量。若acks设置为1,表示producer会在leader partition收到消息时得到broker的一个确认,这样会有更好的可靠性,因为客户端会等待知道broker确认收到消息。若设置为-1,producer会在所有备份的partition收到消息时得到broker的确认,这个设置可以得到最高的可靠性保证。
- oneway
oneway是只顾消息发出去而不管死活,消息可靠性最低,但是低延迟、高吞吐,这种对于某些完全对可靠性没有要求的场景还是适用的,即request.required.acks设置为0。一般配置
对于sync的发送方式:
producer.type=sync
request.required.acks=1对于async的发送方式:
producer.type=async
request.required.acks=1
queue.buffering.max.ms=5000
queue.buffering.max.messages=10000
queue.enqueue.timeout.ms = -1
batch.num.messages=200对于oneway的发送发送:
producer.type=async
request.required.acks=0
5.2.3 消费者
public class OrderConsumer {
public static void main(String[] args) {
// 1/连接集群
Properties props = new Properties();
props.put("bootstrap.servers", "node01:9092");
props.put("group.id", "test");
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("key.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<String, String>(props);
//2、发送数据 发送数据需要,订阅下要消费的topic。 order
kafkaConsumer.subscribe(Arrays.asList("order"));
while (true) {
ConsumerRecords<String, String> consumerRecords = kafkaConsumer.poll(100);
// jdk queue offer插入、poll获取元素。 blockingqueue put插入原生,take获取元素
for (ConsumerRecord<String, String> record : consumerRecords) {
System.out.println("消费的数据为:" + record.value());
}
}
}
}
5.2.4 kafka与spring的整合
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
<version>1.3.5.RELEASE</version>
</dependency>
(1)生产者
kafka.servers=hadoop1:9092
kafka.topic=day_ue-test
<!-- 加载属性文件 -->
<context:property-placeholder location="classpath:init.properties" />
<!-- 定义producer的参数信息 -->
<bean id="producerProperties" class="java.util.HashMap">
<constructor-arg>
<map>
<entry key="bootstrap.servers" value="${kafka.servers}"/>
<entry key="group.id" value="0"/>
<entry key="retries" value="10"/>
<entry key="batch.size" value="16384"/>
<entry key="linger.ms" value="1"/>
<entry key="buffer.memory" value="33554432"/>
<entry key="key.serializer" value="org.apache.kafka.common.serialization.IntegerSerializer"/>
<entry key="value.serializer" value="org.apache.kafka.common.serialization.StringSerializer"/>
</map>
</constructor-arg>
</bean>
<!-- 创建kafkatemplate需要使用的producerfactory bean -->
<bean id="producerFactory" class="org.springframework.kafka.core.DefaultKafkaProducerFactory">
<constructor-arg>
<ref bean="producerProperties"/>
</constructor-arg>
</bean>
<!-- 创建kafkatemplate bean,使用的时候,只需要注入这个bean,即可使用template的send消息方法 -->
<bean id="KafkaTemplate" class="org.springframework.kafka.core.KafkaTemplate">
<constructor-arg ref="producerFactory"/>
<constructor-arg name="autoFlush" value="true"/>
<property name="defaultTopic" value="${kafka.topic}"/>
</bean>
@Component
public class day_ueKafkaProducer {
@Autowired
private KafkaTemplate<Integer, String> kafkaTemplate;
/**
* 发送消息到day_ue-test这个topic
* @param data<br/>
* ============History===========<br/>
* 2018年8月24日 Administrator 新建
*/
public void sendday_ue(String data) {
kafkaTemplate.send("day_ue-test", data);
}
}
(2)消费者
<!-- 定义consumer的参数 -->
<bean id="consumerProperties" class="java.util.HashMap">
<constructor-arg>
<map>
<entry key="bootstrap.servers" value="${kafka.servers}"/>
<entry key="group.id" value="0"/>
<entry key="enable.auto.commit" value="true"/>
<entry key="auto.commit.interval.ms" value="1000"/>
<entry key="session.timeout.ms" value="15000"/>
<entry key="key.deserializer" value="org.apache.kafka.common.serialization.IntegerDeserializer"/>
<entry key="value.deserializer" value="org.apache.kafka.common.serialization.StringDeserializer"/>
</map>
</constructor-arg>
</bean>
<!-- 创建consumerFactory bean -->
<bean id="consumerFactory" class="org.springframework.kafka.core.DefaultKafkaConsumerFactory">
<constructor-arg>
<ref bean="consumerProperties"/>
</constructor-arg>
</bean>
<!-- 消费者容器配置信息 -->
<bean id="containerProperties" class="org.springframework.kafka.listener.config.ContainerProperties">
<constructor-arg value="${kafka.topic}"/>
<!-- 真正执行消费数据逻辑的消息监听者 -->
<property name="messageListener" ref="day_ueKafkaConsumer"/>
</bean>
<bean id="messageListenerContainer" class="org.springframework.kafka.listener.KafkaMessageListenerContainer" init-method="doStart">
<constructor-arg ref="consumerFactory"/>
<constructor-arg ref="containerProperties"/>
</bean>
@Component
public class day_ueKafkaConsumer implements MessageListener<Integer, String>{
@Override
public void onMessage(ConsumerRecord<Integer, String> recoders) {
String value = recoder.value();
System.out.println("获取topic中的数据进行消费,内容:" + value);
}
}
6.kafka的原理分析总结
6.1 分片和副本机制
./kafka-topics.sh --create --zookeeper zk01:2181 --replication-factor 2 --partitions 2 --topic order
分片: 当数据量非常大的时候,一个服务器存放不了,就将数据分成两个或者多个部分,存放在多台服务器上。每个服务器上的数据,叫做一个分片。
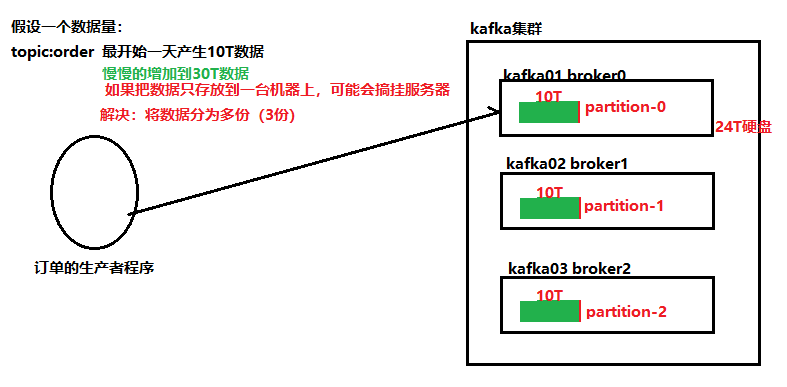
- 分片机制解决了单机存储容量有限的问题.
**副本:**当数据只保存一份的时候,有丢失的风险。为了更好的容错和容灾,将数据拷贝几份,保存到不同的机器上。
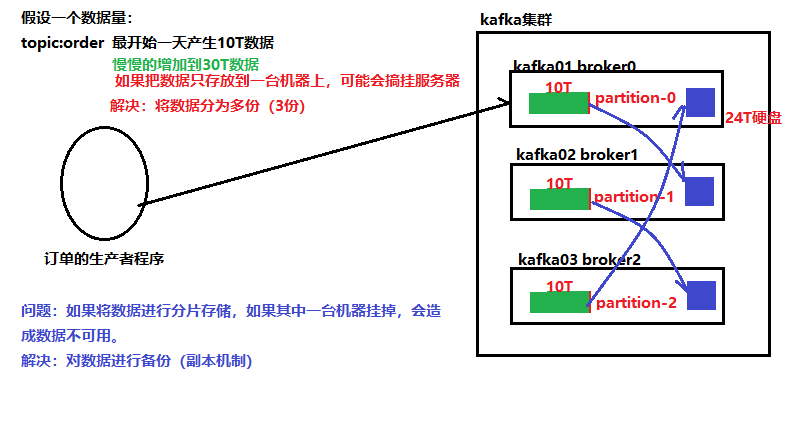
- 副本备份机制解决了数据存储的高可用问题.
6.2 消息不丢失机制
6.2.1 生产者消息不丢失
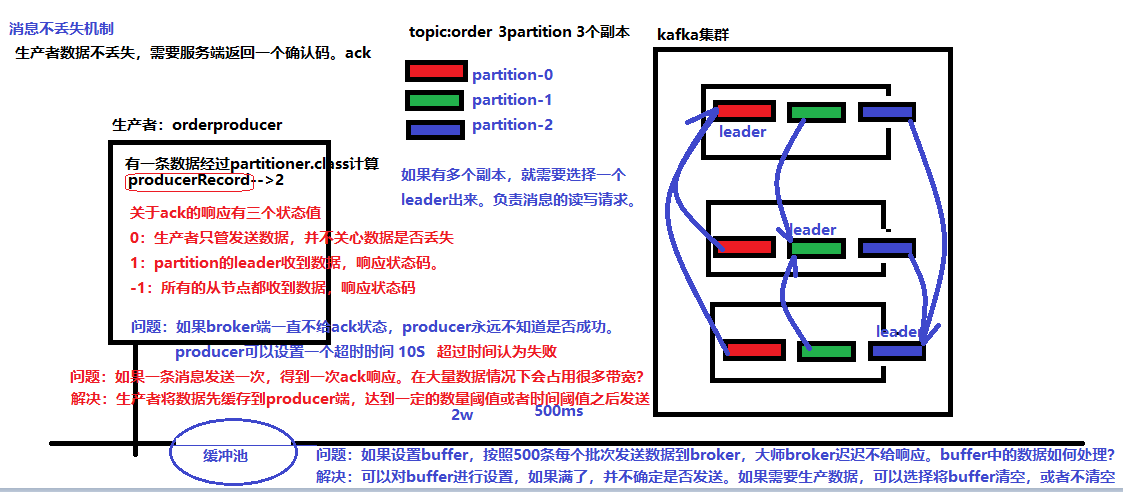
1) 消息生产分为同步模式和异步模式
2) 消息确认分为三个状态
- 0:生产者只负责发送数据
- 1:某个partition的leader收到数据给出响应
- -1:某个partition的所有副本都收到数据后给出响应
3) 在同步模式下
- 生产者等待10S,如果broker没有给出ack响应,就认为失败。
- 生产者重试3次,如果还没有响应,就报错。
4) 在异步模式
- 先将数据保存在生产者端的buffer中。Buffer大小是2万条。
- 满足数据阈值或者数量阈值其中的一个条件就可以发送数据。
- 发送一批数据的大小是500条。
如果broker迟迟不给ack,而buffer又满了。开发者可以设置是否直接清空buffer中的数据。
6.2.2 borker端消息不丢失
broker端的消息不丢失,其实就是用partition副本机制来保证。
Producer ack -1. 能够保证所有的副本都同步好了数据。其中一台机器挂了,并不影像数据的完整性。
6.2.3 消费者端消息不丢失
只要记录offset值,消费者端不会存在消息不丢失的可能,只会重复消费。

6.3 消息存储和查询机制
6.3.1 文件存储机制
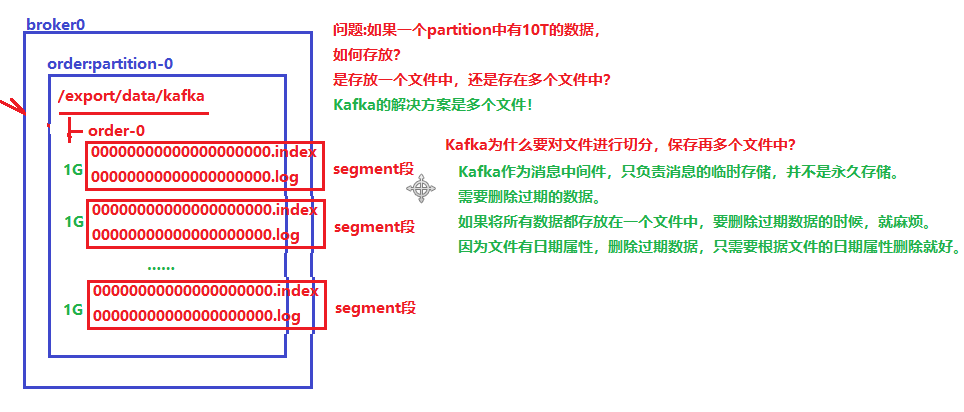
segment段中有两个核心的文件一个是log,一个是index。 当log文件等于1G时,新的会写入到下一个segment中。
通过下图中的数据,可以看到一个segment段差不多会存储70万条数据
6.3.2 文件查询机制

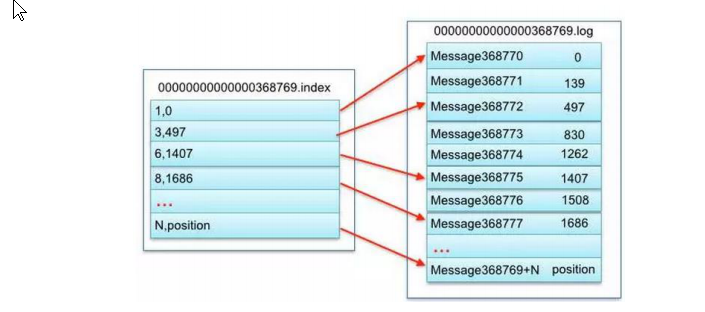
总结:
- 一个topic的一个partition分区数据使用多个segment段进行存储.
- 每个segment段包含一个log日志数据文件和index索引文件.
- Log日志文件存储message数据,index索引文件存储message数据在log日志文件中的偏移地址信息,极大的提高删除数据和查找数据的效率.
6.4 生产者数据分发策略
kafka在数据生产的时候,有一个数据分发策略。默认的情况使用DefaultPartitioner.class类。
这个类中就定义数据分发的策略。
- 如果是用户指定了partition,生产就不会调用DefaultPartitioner.partition()方法
- 当用户指定key,使用hash算法。如果key一直不变,同一个key算出来的hash值是个固定值。如果是固定值,这种hash取模就没有意义。
Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions
- 当用户既没有指定partition也没有指定key,使用轮询的方式发送数据。
6.5 消费者的负载均衡机制
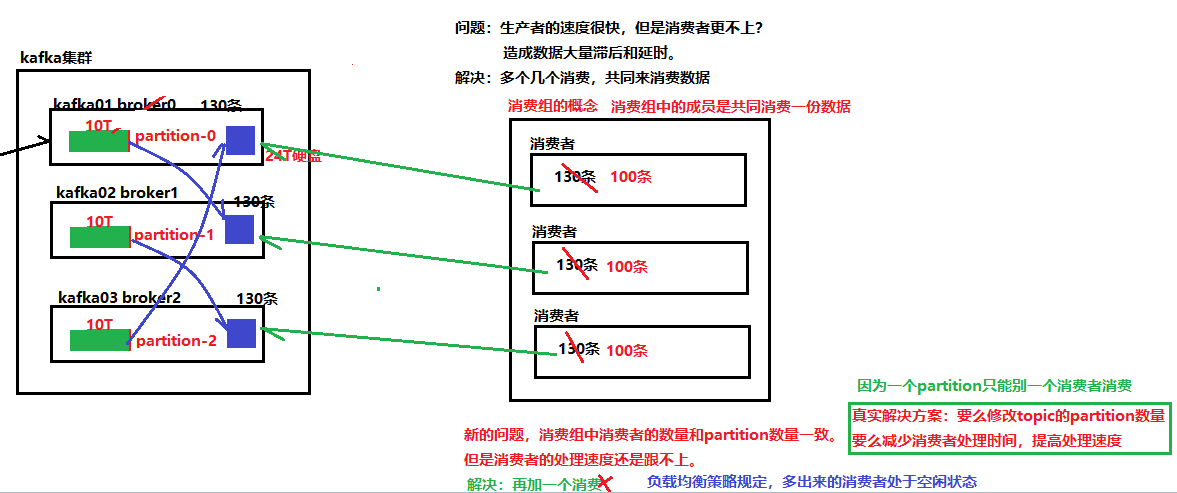
一个partition只能被一个组中的成员消费。所以如果消费组中有多于partition数量的消费者,那么一定会有消费者无法消费数据。
7.补充内容
有什么用?(消息队列有什么用?)
1) 作为缓冲,来异构、解耦系统。
- 用户注册需要完成多个步骤,每个步骤执行都需要很长时间。代表用户等待时间是所有步骤的累计时间。
- 为了减少用户等待的时间,使用并行执行执行,有多少个步骤,就开启多少个线程来执行。代表用户等待时间是所有步骤中耗时最长的那个步骤时间。
- 有了新得问题:开启多线程执行每个步骤,如果以一个步骤执行异常,或者严重超时,用户等待的时间就不可控了。
- 通过消息队列来保证。
- 注册时,立即返回成功。
- 发送注册成功的消息到消息平台。
- 对注册信息感兴趣的程序,可以消息消息。
kafka为何高吞吐?
-
消费者组概念,提高了消费并行度
-
消费偏移量的索引,并且这里有分桶的机制,因此能迅速定位到消费位置
-
"message set"机制,消息不是一条条发送的,而是批量发送的,这样就降低了频繁网络io操作
-
The other inefficiency is in byte copying. At low message rates this is not an issue, but under load the impact is significant. To avoid this we employ a standardized binary message format that is shared by the producer, the broker, and the consumer (so data chunks can be transferred without modification between them).
-
消息发送零拷贝的问题:
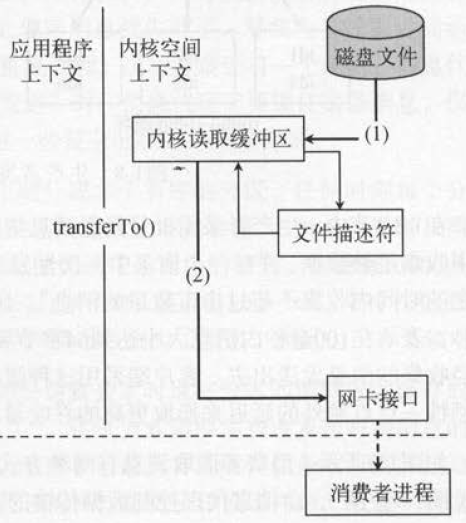
原始消息处理方式:存在4次copy
(1)操作系统将数据从磁盘文件中读取到内核空间的页面缓存;
(2)应用程序将数据从内核空间读入用户空间缓冲区;
(3)应用程序将读到数据写回内核空间并放入socket缓冲区;
(4)操作系统将数据从socket缓冲区复制到网卡接口,此时数据才能通过网络发送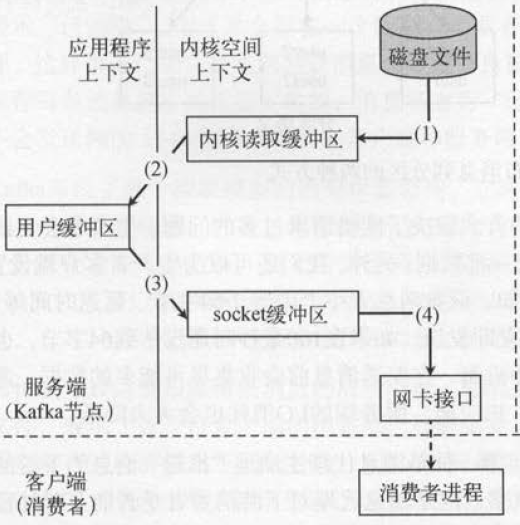
“零拷贝技术”只用将磁盘文件的数据复制到页面缓存中一次,然后将数据从页面缓存直接发送到网络中(发送给不同的订阅者时,都可以使用同一个页面缓存),避免了重复复制操作。
如果有10个消费者,传统方式下,数据复制次数为4*10=40次,而使用“零拷贝技术”只需要1+10=11次,一次为从磁盘复制到页面缓存,10次表示10个消费者各自读取一次页面缓存。
-
当问题不是CPU或者磁盘io时,受到网络宽带影响,kafka支持消息端到端的压缩
讲述kafka的ack机制
kafka节点之间如何复制备份的?
ISR集合:ISR(In-Sync Replica)集合代表的是follow副本和leader副本消息相差不多的副本的集合。消息相差不到是一个比较模糊的概念。其实follow副本需要满足以下两个条件:
1:follow副本必须和zookeeper保持连接。
2:follow副本的最后的offset和leader中最新的数据之间的大小不能超过阈值。(也就是每个follow不能和leader副本消息相差太多)。
kafka采取同步和异步的共同优点,所以使用ISR的方法。把Follow中同步慢的数据进行T除,从而保证了复制数据的速度。一句话总结就是用同步的方法,如果其中有同步数据慢的follow的情况,直接把该follow给T除,如果后来速度又追上,则恢复其身份。如果leader副本宕机,那么从ISR中选举出来新的leader副本。因为follow副本中都有记录HW。这样也会减少数据的丢失。Follow副本能够从leader中批量的读取数据并批量写入,从而减少了I/0的开销。
kafka消息是否会丢失?为什么?
-
Kafka消息发送分同步(sync)、异步(async)两种方式
默认是使用同步方式,可通过producer.type属性进行配置;
-
Kafka保证消息被安全生产,有三个选项分别是0,1,-1
通过request.required.acks属性进行配置:
0代表:不进行消息接收是否成功的确认(默认值);
1代表:当Leader副本接收成功后,返回接收成功确认信息;
-1代表:当Leader和Follower副本都接收成功后,返回接收成功确认信息;
两个维度相交,生成六种情况,如下:
(1)网络异常
acks设置为0时,不和Kafka集群进行消息接受确认,当网络发生异常等情况时,存在消息丢失的可能;
(2)客户端异常
异步发送时,消息并没有直接发送至Kafka集群,而是在Client端按一定规则缓存并批量发送。在这期间,如果客户端发生死机等情况,都会导致消息的丢失;
(3)缓冲区满了
异步发送时,Client端缓存的消息超出了缓冲池的大小,也存在消息丢失的可能;
(4)Leader副本异常
acks设置为1时,Leader副本接收成功,Kafka集群就返回成功确认信息,而Follower副本可能还在同步。这时Leader副本突然出现异常,新Leader副本(原Follower副本)未能和其保持一致,就会出现消息丢失的情况;
想要更高的吞吐量就设置:异步、ack=0;想要不丢失消息数据就选:同步、ack=-1策略
kafka最合理的配置是什么?
kafka的leader选举机制是什么?
从ISR集合中进行选举,选举数据同步最完整的副本为leader
kafka对硬件的配置有什么要求?
kafka的消息保证有几种方式?
0 1 -1
kafka和传统mq的区别?
1 kafka是什么:Kafka® is used for building real-time data pipelines and streaming apps
2 kafka没有严格遵守jms的设计
3 说一下kafka是一个分布式的消息流处理系统,分区问题
4 kafka的副本
5 分区内的消息有序,无法保证整体有序
6 消费者组,每个分区只能被一个group内的一个consumer消费


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









