



 本文介绍了异构信息网络的基本概念,包括信息网络、网络模式及元路径的定义,并以文献信息网络为例,深入探讨了如何通过元路径进行相似度计算。适合于对网络分析感兴趣的研究者和从业者。
本文介绍了异构信息网络的基本概念,包括信息网络、网络模式及元路径的定义,并以文献信息网络为例,深入探讨了如何通过元路径进行相似度计算。适合于对网络分析感兴趣的研究者和从业者。
定义1.信息网络(Information Network)是一个有向图G=(V, E),它有一个对象类型映射函数ψ:V→A和一个链接类型映射函数φ:E→R,其中,每一个对象v∈V属于一个特定的类型对象ψ(v)∈A,每一个链接对象e∈E属于一个特定的关系类型φ(e)∈R,如果2个链接属于同一个关系类型,那么2个链接具有同样的开始对象类型和终止对象类型。当对象类型|A|>1或者关系类型|R|>1时,该网络称为异构信息网络(Heterogeneous Information Network, HIN),否则称为同构信息网络。
例1.文献信息网络(Bibliographic Information Network)是一个经典的异构信息网络,包含四种实体:文章(papers, P),场合(例如,会议/期刊)(venues, V),作者(author, A)和关键词(terms,T),对于每篇文章p∈P,它的链接有一组作者,一个场合,一组词汇(作为题目中的术语),一组被引用文章和一组引用文章p的文章,链接类型由它们之间的关系定义。
如图所示:

图片来源:Shi, C.; Li,Y.;Zhang J.; Sun, Y.; Yu, P. S. (2017). A Survey of Heterogeneous Information Network Analysis.IEEE Transactions on Knowledge and Data Engineering.29(1):17 - 37.
对于一个给定的复杂异构信息网络,为了更好地理解网络中的对象类型和链接类型,必须提供它的元描述.因此要定义描述网络元结构的网络模式:
定义2.网络模式(Network Schema)记作TG=(A, R),是异构网络G=(V, E)的元模板,它具有对象类型映射ψ:V→A和一个关系类型映射φ:E→R,是定义在对象类型集合A和关系类型集合R上的有向图。
下图中的(a)就是PathSim论文中给出文献信息网络的的Network Schema:
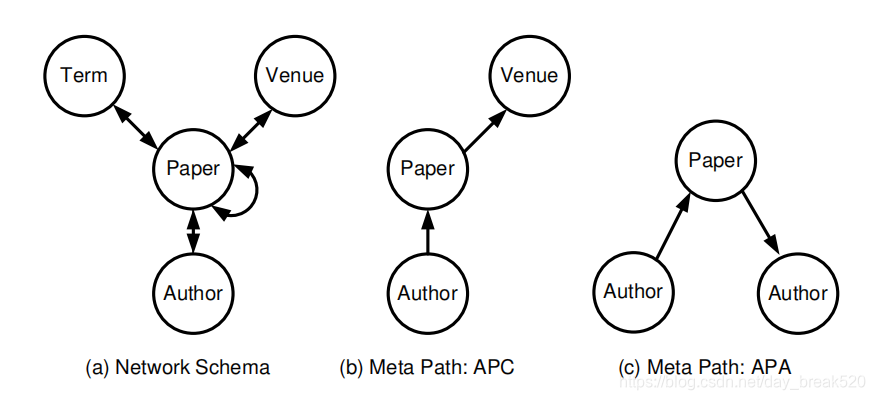
图片来源:Sun, Y.Z., Han, J.W., Yan, X.F., Yu, P.S., Wu, T.(2011). PathSim: Meta Path-Based Top-K Similarity Search in Heterogeneous Information Networks.Proceedings of the VLDB Endowment. 4:992-1003.
定义3.元路径是一个定义在图的网络模式TG=(A, R)上的路径。它的表示结构为![]() ,它定义
,它定义![]() 到
到![]() 之间的一组复合关系
之间的一组复合关系![]() 。
。
上面的图片中(b)、(c)就是给出的文献信息网络中的两个元路径实例,一个异构信息网络中,元路径并不是唯一的,可以是APV、APA、APVPA,如果我们要计算两个Author之间的相似度,我们可以使用元路径APA或者元路径APVPA,看了下面的公式也许就明白这句话的意思了。经过上面那些介绍,现在可以给出PathSim中相似度计算的公式:
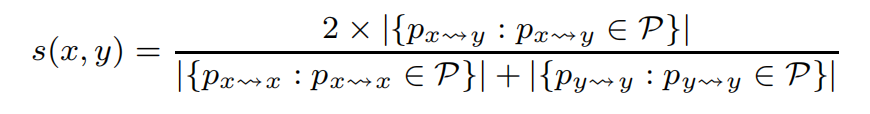
![]() 是x与y之间的路径实例,
是x与y之间的路径实例,![]() 是x与x之间的路径实例,
是x与x之间的路径实例,![]() 是y与y之间的路径实例。论文中还给出了一些提高计算效率的方法,可以去看一下,文章链接:
是y与y之间的路径实例。论文中还给出了一些提高计算效率的方法,可以去看一下,文章链接:
http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.227.9062&rep=rep1&type=pdf

















 3778
3778

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









