






前言警告
有时候在想为什么百度网盘还没有倒闭,这个会员我充的意义是什么?还有为什么V商要在漫画上还要狠狠宰我一笔,明明自己拿的几手的漫画再出来倒的(另一种程度的倒爷)!
然后,我今天要狠狠薅这个漫画APP的羊毛,大家不要举报,万一它也收费了呢,这就很尴尬了>-)

(拿这部《转生成为了只有乙女游戏破灭Flag的邪恶大小姐》开刀)
反爬小贴士:都说不要用PHP辣!要在图片链接之前加二进制编码,不然这些爬佬就会狠狠爬光你的图片再去当倒爷!
正文
整理被爬对象的信息
1.搞清楚里面的网站结构,包括图片有没有blob加密,有没有设置服务器反爬,需不需要科技的帮助
2.整理需要爬取的目录合集,一共爬几话
3.准备转PDF的操作也上一下
4.根据自己电脑的内存设置,选择开几个子线程
主要工作
环境
- Windows 11
- Python
3.8.0or higher - Pycharm
2021.03
安装库
pip install -r requirements.txt
访问网站的权限
总所周知,有一些漫画网站里收录的漫画的链接是不在国内的,也就是说你可能能看它上面的一些漫画,但是某些漫画想看的时候,哎,就是空白无法访问。这时候就要用魔法打败魔法!
如果你没有魔法,请直接看看小黑猫停机坪。再多的就不能说了,我现在这台设备用的不是小黑猫,但是原理基本一致,需要你的转发端口值。
关键代码用于判断当前网页是否需要用魔法进行访问,若在限定时间内未响应则更换科技。
self.proxies = {
'http': "http://127.0.0.1:XXX",
'https': "http://127.0.0.1:XXX",
'socks': "socks5://127.0.0.1:XXX"
}
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36'}
def proxy_sniffer(self, web):
if web:
try:
# timeout -> your preference
response = self.session.get(web, headers=self.headers, timeout=3)
if response.status_code == 200:
init_content = response.text
if init_content is None or []:
return False
self.soup = BeautifulSoup(init_content, 'html.parser')
return True
except requests.exceptions.ProxyError:
print("~~~使用代理爬取~~~")
self.proxy_code = 0
response = self.session.get(web, headers=self.headers, proxies=self.proxies, timeout=5)
if response.status_code == 200:
init_content = response.text
if init_content is None or []:
return False
self.soup = BeautifulSoup(init_content, 'html.parser')
return True
return False
爬图完整类
FastCartoonCrawlerForCMH5/ FasterCartoonCrawlerForBaoZiMH
主要是爬CMH5上的漫画,不过这个网站也没啥好康的。有需要的更换网站,根据它上面的元素来写爬取组件的整理。
class FasterCartoonCrawlerForCMH5:
def __init__(self, target):
# add your VPN info
self.proxies = {
'http': "http://127.0.0.1:?????",
'https': "http://127.0.0.1:?????",
'socks': "socks5://127.0.0.1:??????"
}
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36'}
self.target = target
self.session = requests.Session()
self.proxy_code = 1
# set your thread number according to your settings in python editor, default value is 5
self.max_thread_number = 5
self.soup = None
self.alldata = {}
self.absolute_path = None
self.comic_name = None
def get_contents_component(self, web):
# update soup and init_content to avoid repeated works
if web:
if self.proxy_code == 1:
response = self.session.get(web, headers=self.headers, timeout=5)
if response.status_code == 200:
init_content = response.text
if init_content is None or []:
return False
self.soup = BeautifulSoup(init_content, 'html.parser')
return True
else:
response = self.session.get(web, headers=self.headers, proxies=self.proxies, timeout=5)
if response.status_code == 200:
init_content = response.text
if init_content is None or []:
return False
self.soup = BeautifulSoup(init_content, 'html.parser')
return True
return False
# To sniffer your target web service address
# if it is in foreign countries, you need to use proxy to get access to its sources, else keep initial status.
def proxy_sniffer(self, web):
if web:
try:
# timeout -> your preference
response = self.session.get(web, headers=self.headers, timeout=3)
if response.status_code == 200:
init_content = response.text
if init_content is None or []:
return False
self.soup = BeautifulSoup(init_content, 'html.parser')
return True
except requests.exceptions.ProxyError:
print("~~~使用代理爬取~~~")
self.proxy_code = 0
response = self.session.get(web, headers=self.headers, proxies=self.proxies, timeout=5)
if response.status_code == 200:
init_content = response.text
if init_content is None or []:
return False
self.soup = BeautifulSoup(init_content, 'html.parser')
return True
return False
def get_crawl_list(self):
is_state = self.proxy_sniffer(self.target)
# get crawl list
if is_state:
print("~~~正在获取漫画章节~~~")
self.comic_name = self.soup.find('p', class_='comic-title j-comic-title').get_text(strip=True)
links = self.soup.find_all('a', class_='j-chapter-link')
chapter_links = [{'chapter_name': link.get_text(strip=True),
'chapter_link': 'https://www.cmh5.com' + str(link.get('href'))}
for link in links]
return chapter_links
return {}
def get_chapter_src(self, target_link_dist):
for item in target_link_dist:
name, link = item['chapter_name'], item['chapter_link']
is_state = self.get_contents_component(link)
if is_state:
img_tags = self.soup.find_all('img', class_='lazy-read')
src_list = [str(img['data-original']) for img in img_tags]
item['chapter_src_list'] = src_list
print("~~~获取漫画章节具体信息~~~")
self.alldata = target_link_dist
def create_folder(self, name):
current_directory = os.path.dirname(os.path.abspath(__file__))
new_folder_path = os.path.join(os.path.dirname(current_directory), 'results', name)
os.makedirs(new_folder_path, exist_ok=True)
return new_folder_path
def downloader(self, img_url):
if self.proxy_code == 1:
response = self.session.get(img_url, headers=self.headers, timeout=5)
if response.status_code == 200:
return response.content
return None
else:
response = self.session.get(img_url, headers=self.headers, proxies=self.proxies, timeout=5)
if response.status_code == 200:
return response.content
return None
# In order to download images faster, we import thread pools to accelerate this process.
def download_img_threaded(self, item, pbar_chapter):
chapter_name = item['chapter_name']
chapter_src_list = item['chapter_src_list']
img_folder_path = os.path.join(self.absolute_path, 'img')
os.makedirs(img_folder_path, exist_ok=True)
img_folder_path = os.path.normpath(img_folder_path)
with concurrent.futures.ThreadPoolExecutor(max_workers=self.max_thread_number) as executor:
for per_src in chapter_src_list:
future = executor.submit(self.downloader, per_src)
img_data = future.result()
if img_data:
idx = chapter_src_list.index(per_src)
img_name = f'{idx + 1}.jpg'
chapter_folder = os.path.join(img_folder_path, chapter_name)
os.makedirs(chapter_folder, exist_ok=True)
img_path = os.path.join(chapter_folder, img_name)
with open(img_path, 'wb') as img_file:
img_file.write(img_data)
# update bar
pbar_chapter.update(1)
pbar_chapter.set_postfix_str(f'正在下载{chapter_name}')
return chapter_name, len(chapter_src_list)
def download_img(self, number=None):
total_img_count = sum(len(item['chapter_src_list']) for item in self.alldata)
src_path_data = {}
with tqdm(total=total_img_count, desc=f'正在下载[{self.comic_name}]漫画') as pbar_main:
if self.alldata and self.target:
self.absolute_path = self.create_folder(self.comic_name)
self.datalog(self.alldata, 'crawl-data-set.json')
with concurrent.futures.ThreadPoolExecutor(max_workers=self.max_thread_number) as executor:
if number is None:
items_to_process = self.alldata
else:
items_to_process = self.alldata[:number]
for item in items_to_process:
future_to_url = executor.submit(self.download_img_threaded, item, pbar_main)
try:
chapter_name, length = future_to_url.result()
img_folder_path = os.path.join(self.absolute_path, 'img')
chapter_folder_path = os.path.join(img_folder_path, chapter_name)
chapter_src_path = [os.path.join(chapter_folder_path, f'{i}.jpg') for i in range(1, length + 1)]
src_path_data[chapter_name] = chapter_src_path
except Exception as exc:
print(f"处理章节图片时发生异常: {exc}")
return src_path_data
def datalog(self, dist_data, json_file_path):
json_folder_path = os.path.join(self.absolute_path, 'json')
os.makedirs(json_folder_path, exist_ok=True)
json_file_path = os.path.join(json_folder_path, json_file_path)
json_file_path = os.path.normpath(json_file_path)
with open(json_file_path, "w", encoding="utf-8") as json_file:
json.dump(dist_data, json_file, ensure_ascii=False, indent=4)
def Launcher(self):
chapter_list = self.get_crawl_list()
if chapter_list:
self.get_chapter_src(chapter_list)
# you can assign your number for crawler, like self.download_img(number=3)
isok = self.download_img()
if isok:
print("检查这个文件是否存在: real-img-path.json")
self.datalog(isok, 'real-img-path.json')
print("CartoonCrawlerForCMH5 爬取完成!")
return isok
else:
print("爬取过程中意外失败...")
return False
else:
print("没有得到爬取漫画列表!请检查target_web_list.txt!")
同理另一个Baozi网上的也是改了对元素筛选的内容,其余的基本一致。
class FasterCartoonCrawlerForBaoZiMH:
def __init__(self, target):
# add your VPN info
self.proxies = {
'http': "http://127.0.0.1:????",
'https': "http://127.0.0.1:????",
'socks': "socks5://127.0.0.1:????"
}
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36'}
self.target = target
self.session = requests.Session()
self.proxy_code = 1
# set your thread number according to your settings in python editor, default value is 5
self.max_thread_number = 5
self.soup = None
self.alldata = {}
self.absolute_path = None
self.comic_name = None
# optimized version for www.baozimh.org
def get_contents_component(self, web):
if web:
try:
if self.proxy_code == 1:
with self.session.get(web, headers=self.headers, timeout=(3, 2)) as response:
if response.status_code == 200:
init_content = response.text
if init_content is not None and init_content != []:
self.soup = BeautifulSoup(init_content, 'html.parser')
return True
else:
with self.session.get(web, headers=self.headers, proxies=self.proxies, timeout=(5, 5)) as response:
if response.status_code == 200:
init_content = response.text
if init_content is not None and init_content != []:
self.soup = BeautifulSoup(init_content, 'html.parser')
return True
except requests.exceptions.RequestException as e:
print("An error occurred:", e)
return False
# To sniffer your target web service address
# if it is in foreign countries, you need to use proxy to get access to its sources, else keep initial status.
def proxy_sniffer(self, web):
if web:
try:
with self.session.get(web, headers=self.headers, timeout=(3, 2)) as response:
if response.status_code == 200:
init_content = response.text
if init_content is not None and init_content != []:
self.soup = BeautifulSoup(init_content, 'html.parser')
return True
except requests.exceptions.ProxyError:
print("~~~使用代理爬取~~~")
self.proxy_code = 0
with self.session.get(web, headers=self.headers, proxies=self.proxies, timeout=(5, 5)) as response:
if response.status_code == 200:
init_content = response.text
if init_content is not None and init_content != []:
self.soup = BeautifulSoup(init_content, 'html.parser')
return True
return False
def get_crawl_list(self):
is_state = self.proxy_sniffer(self.target)
# get crawl list
if is_state:
print("~~~正在获取漫画章节~~~")
self.comic_name = self.soup.find('div', id='MangaHistoryStorage')['data-title'].encode('latin-1').decode('utf-8')
chapter_divs = self.soup.find_all('div', class_='chapteritem w-full undefined')
links = [div.find('a') for div in chapter_divs]
chapter_links = [{'chapter_name': link.find('span', class_='chaptertitle').get_text(strip=True).encode('latin-1').decode('utf-8'),
'chapter_link': link['href']} for link in links]
return chapter_links
return []
def get_chapter_src(self, target_link_dist):
for item in target_link_dist:
name, link = item['chapter_name'], item['chapter_link']
is_state = self.get_contents_component(link)
if is_state:
img_tags = self.soup.find_all('img', class_='lazyload h-full w-full m-auto block max-w-full')
src_list = [str(img['src']) for img in img_tags]
item['chapter_src_list'] = src_list
print("~~~获取漫画章节具体信息~~~")
self.alldata = target_link_dist
def create_folder(self, name):
current_directory = os.path.dirname(os.path.abspath(__file__))
new_folder_path = os.path.join(os.path.dirname(current_directory), 'results', name)
os.makedirs(new_folder_path, exist_ok=True)
return new_folder_path
def downloader(self, img_url):
if self.proxy_code == 1:
with self.session.get(img_url, headers=self.headers, stream=True, timeout=(5, 5)) as response:
if response.status_code == 200:
return response.content
return None
else:
with self.session.get(img_url, headers=self.headers, proxies=self.proxies, stream=True, timeout=(5, 5)) as response:
if response.status_code == 200:
return response.content
return None
# In order to download images faster, we import thread pools to accelerate this process.
def download_img_threaded(self, item, pbar_chapter):
chapter_name = item['chapter_name']
chapter_src_list = item['chapter_src_list']
img_folder_path = os.path.join(self.absolute_path, 'img')
os.makedirs(img_folder_path, exist_ok=True)
img_folder_path = os.path.normpath(img_folder_path)
with concurrent.futures.ThreadPoolExecutor(max_workers=self.max_thread_number) as executor:
for per_src in chapter_src_list:
future = executor.submit(self.downloader, per_src)
img_data = future.result()
if img_data:
idx = chapter_src_list.index(per_src)
img_name = f'{idx + 1}.jpg'
chapter_folder = os.path.join(img_folder_path, chapter_name)
os.makedirs(chapter_folder, exist_ok=True)
img_path = os.path.join(chapter_folder, img_name)
with open(img_path, 'wb') as img_file:
img_file.write(img_data)
# update bar
pbar_chapter.update(1)
pbar_chapter.set_postfix_str(f'正在下载{chapter_name}')
return chapter_name, len(chapter_src_list)
def download_img(self, number=None):
total_img_count = sum(len(item['chapter_src_list']) for item in self.alldata)
src_path_data = {}
with tqdm(total=total_img_count, desc=f'正在下载[{self.comic_name}]漫画') as pbar_main:
if self.alldata and self.target:
self.absolute_path = self.create_folder(self.comic_name)
self.datalog(self.alldata, 'crawl-data-set.json')
with concurrent.futures.ThreadPoolExecutor(max_workers=self.max_thread_number) as executor:
if number is None:
items_to_process = self.alldata
else:
items_to_process = self.alldata[:number]
for item in items_to_process:
future_to_url = executor.submit(self.download_img_threaded, item, pbar_main)
try:
chapter_name, length = future_to_url.result()
img_folder_path = os.path.join(self.absolute_path, 'img')
chapter_folder_path = os.path.join(img_folder_path, chapter_name)
chapter_src_path = [os.path.join(chapter_folder_path, f'{i}.jpg') for i in range(1, length + 1)]
src_path_data[chapter_name] = chapter_src_path
except Exception as exc:
print(f"处理章节图片时发生异常: {exc}")
return src_path_data
def datalog(self, dist_data, json_file_path):
json_folder_path = os.path.join(self.absolute_path, 'json')
os.makedirs(json_folder_path, exist_ok=True)
json_file_path = os.path.join(json_folder_path, json_file_path)
json_file_path = os.path.normpath(json_file_path)
with open(json_file_path, "w", encoding="utf-8") as json_file:
json.dump(dist_data, json_file, ensure_ascii=False, indent=4)
def Launcher(self):
chapter_list = self.get_crawl_list()
if chapter_list:
self.get_chapter_src(chapter_list)
# you can assign your number for crawler, like self.download_img(number=3)
isok = self.download_img()
if isok:
print("检查这个文件是否存在: real-img-path.json")
self.datalog(isok, 'real-img-path.json')
print("CartoonCrawlerForBaoZiMH 爬取完成!")
return isok
else:
print("爬取过程中意外失败...")
return False
else:
print("没有得到爬取漫画列表!请检查target_web_list.txt!")
PDF转换类
专门用来处理爬到的章节图片,合并到一个PDF文件里的,如果只想看图片,可以直接忽略这一步。
class PDF_generator:
def __init__(self, output_path, src_path_data):
self.output_path = output_path
self.src_path_data = src_path_data
def create_pdf(self, chapter_name, img_paths):
# create a pdf
pdf_folder_path = os.path.join(self.output_path, 'pdf')
os.makedirs(pdf_folder_path, exist_ok=True)
pdf_path = os.path.join(pdf_folder_path, f'{chapter_name}.pdf')
pdf_path = os.path.normpath(pdf_path)
c = canvas.Canvas(pdf_path, pagesize=(595, 842)) # A4 size
page_width = 595
page_height = 842
for img_path in img_paths:
img = Image.open(img_path)
img_width, img_height = img.size
aspect_ratio = img_height / img_width
scaled_width = page_width
scaled_height = scaled_width * aspect_ratio
if scaled_height > page_height:
scaled_height = page_height
scaled_width = scaled_height / aspect_ratio
x = (page_width - scaled_width) / 2
y = (page_height - scaled_height) / 2
c.drawImage(img_path, x, y, width=scaled_width, height=scaled_height)
c.showPage()
c.save()
print(f"{chapter_name} PDF文件 DONE~~~")
return pdf_path
def connect_img(self):
print("开始拼接PDF~~~")
# src_path_data = {chapter_name,chapter_src_paths} str:list->[]
pdf_paths = []
for chapter_name, chapter_src_paths in self.src_path_data.items():
pdf_path = self.create_pdf(chapter_name, chapter_src_paths)
pdf_paths.append(pdf_path)
return pdf_paths
def Launcher(self):
return self.connect_img()
检查类
检查你有没有目标网站来爬。这里直接暴力用一个文本文件读你写进来的内容,当然你也可以不写,把字符串直接传也是可以的。
def PreChecker():
# get current absolute path
# check target_web_list.txt already exist or not?
# if not then create one, else check the content in it.
current_directory = os.path.dirname(os.path.abspath(__file__))
file_path = os.path.join(current_directory, 'target_web_list.txt')
# check its existence
if os.path.exists(file_path):
with open(file_path, 'r', encoding='utf-8') as file:
content = file.readlines()
return content
else:
with open(file_path, 'w', encoding='utf-8') as file:
pass
return []
主函数
这里要是你不写在文件里,就把target_web=["your web"]写成这样然后继续。
不转PDF就删掉is_success = cartoon_crawler.Launcher()后面的部分。
if __name__ == '__main__':
target_web_list = PreChecker()
cleaned_list = [item.strip() for item in target_web_list if item.strip()]
if target_web_list:
for target in cleaned_list:
cartoon_crawler = FasterCartoonCrawlerForBaoZiMH(target=target)
# cartoon_crawler = FasterCartoonCrawlerForCMH5(target=target)
is_success = cartoon_crawler.Launcher()
if is_success:
pdf_gen = PDF_generator(output_path=cartoon_crawler.absolute_path, src_path_data=is_success)
pdf_paths = pdf_gen.Launcher()
print('~~~PDF拼接完成!~~~')
懒人版
不想配科技,也不想用线程,那么直接用这个,前提是网站可以被访问。
import os.path
import requests
from bs4 import BeautifulSoup
from reportlab.pdfgen import canvas
from PIL import Image
import json
class CartoonCrawlerForCMH5:
def __init__(self, target):
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36'}
self.target = target
self.session = requests.Session()
self.soup = None
self.alldata = {}
self.absolute_path = None
self.comic_name = None
def get_contents_component(self, web):
# update soup and init_content to avoid repeated works
if web:
response = self.session.get(web, headers=self.headers)
if response.status_code == 200:
init_content = response.text
if init_content is None or []:
return False
self.soup = BeautifulSoup(init_content, 'html.parser')
return True
return False
def get_crawl_list(self):
is_state = self.get_contents_component(self.target)
# get crawl list
if is_state:
self.comic_name = self.soup.find('p', class_='comic-title j-comic-title').get_text(strip=True)
links = self.soup.find_all('a', class_='j-chapter-link')
chapter_links = [{'chapter_name': link.get_text(strip=True), 'chapter_link': 'https://www.cmh5.com' + str(link.get('href'))}
for link in links]
return chapter_links
return {}
def get_chapter_src(self, target_link_dist):
for item in target_link_dist:
name, link = item['chapter_name'], item['chapter_link']
is_state = self.get_contents_component(link)
if is_state:
img_tags = self.soup.find_all('img', class_='lazy-read')
src_list = [str(img['data-original']) for img in img_tags]
item['chapter_src_list'] = src_list
self.alldata = target_link_dist
def create_folder(self, name):
current_directory = os.path.dirname(os.path.abspath(__file__))
new_folder_path = os.path.join(os.path.dirname(current_directory), 'results', name)
os.makedirs(new_folder_path, exist_ok=True)
return new_folder_path
def downloader(self, img_url):
response = self.session.get(img_url, headers=self.headers)
if response.status_code == 200:
return response.content
return None
def download_img(self, number=None):
# download and rename them
# create folders like: target_name/chapter_name/img_name...
src_path_data = {}
if self.alldata and self.target:
self.absolute_path = self.create_folder(self.comic_name)
self.datalog(self.alldata,'crawl-data-set.json')
img_folder_path = os.path.join(self.absolute_path, 'img')
os.makedirs(img_folder_path, exist_ok=True)
img_folder_path = os.path.normpath(img_folder_path)
if number is None:
items_to_process = self.alldata
else:
items_to_process = self.alldata[:number]
for item in items_to_process:
chapter_name = item['chapter_name']
chapter_src_list = item['chapter_src_list']
chapter_src_path = []
for idx, per_src in enumerate(chapter_src_list):
chapter_folder = os.path.join(img_folder_path,chapter_name)
os.makedirs(chapter_folder, exist_ok=True)
img_data = self.downloader(per_src)
img_name = f'{idx+1}.jpg'
img_path = os.path.join(chapter_folder, img_name)
chapter_src_path.append(img_path)
with open(img_path, 'wb') as img_file:
img_file.write(img_data)
print('{}的{}张图片下载完成!'.format(chapter_name, idx+1))
src_path_data[chapter_name] = chapter_src_path
return src_path_data
return False
def datalog(self, dist_data, json_file_path):
json_folder_path = os.path.join(self.absolute_path, 'json')
os.makedirs(json_folder_path, exist_ok=True)
json_file_path = os.path.join(json_folder_path, json_file_path)
json_file_path = os.path.normpath(json_file_path)
with open(json_file_path, "w", encoding="utf-8") as json_file:
json.dump(dist_data, json_file, ensure_ascii=False, indent=4)
def Launcher(self):
chapter_list = self.get_crawl_list()
if chapter_list:
self.get_chapter_src(chapter_list)
isok = self.download_img()
if isok:
self.datalog(isok, 'real-img-path.json')
print("CartoonCrawlerForCMH5 爬取完成!")
return isok
else:
print("爬取过程中意外失败...")
return False
class PDF_generator:
def __init__(self, output_path, src_path_data):
self.output_path = output_path
self.src_path_data = src_path_data
def create_pdf(self, chapter_name, img_paths):
# create a pdf
pdf_folder_path = os.path.join(self.output_path, 'pdf')
os.makedirs(pdf_folder_path, exist_ok=True)
pdf_path = os.path.join(pdf_folder_path, f'{chapter_name}.pdf')
pdf_path = os.path.normpath(pdf_path)
c = canvas.Canvas(pdf_path, pagesize=(595, 842)) # A4 size
# add images
for img_path in img_paths:
img = Image.open(img_path)
img_width, img_height = img.size
aspect_ratio = img_height / img_width
page_width, page_height = 595, 842 # A4 size
c.drawImage(img_path, 0, 0, width=page_width, height=page_width * aspect_ratio)
c.showPage()
c.save()
return pdf_path
def connect_img(self):
#src_path_data = {chapter_name,chapter_src_paths} str:list->[]
pdf_paths = []
for chapter_name, chapter_src_paths in self.src_path_data.items():
pdf_path = self.create_pdf(chapter_name, chapter_src_paths)
pdf_paths.append(pdf_path)
return pdf_paths
def Launcher(self):
print('PDF转换完成!')
return self.connect_img()
def PreChecker():
# get current absolute path
# check target_web_list.txt already exist or not?
# if not then create one, else check the content in it.
current_directory = os.path.dirname(os.path.abspath(__file__))
file_path = os.path.join(current_directory, 'target_web_list.txt')
# check it
if os.path.exists(file_path):
with open(file_path, 'r', encoding='utf-8') as file:
content = file.readlines()
return content
else:
with open(file_path, 'w', encoding='utf-8') as file:
pass
return []
if __name__ == '__main__':
target_web_list = PreChecker()
cleaned_list = [item.strip() for item in target_web_list if item.strip()]
if target_web_list:
for target in cleaned_list:
cartoon_crawler = CartoonCrawlerForCMH5(target=target)
is_success = cartoon_crawler.Launcher()
if is_success:
pdf_gen = PDF_generator(output_path=cartoon_crawler.absolute_path, src_path_data=is_success)
pdf_paths = pdf_gen.Launcher()
查看结果
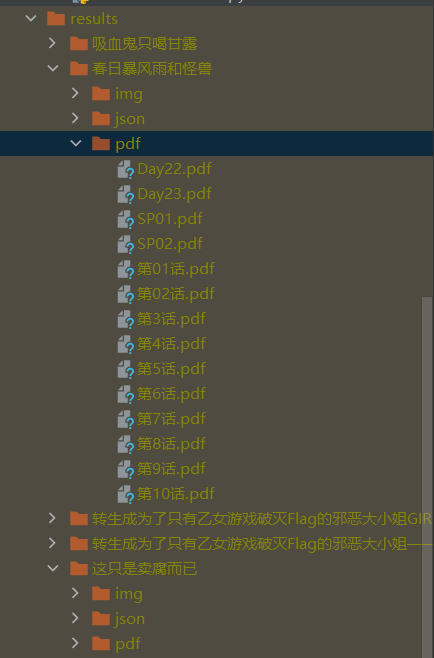
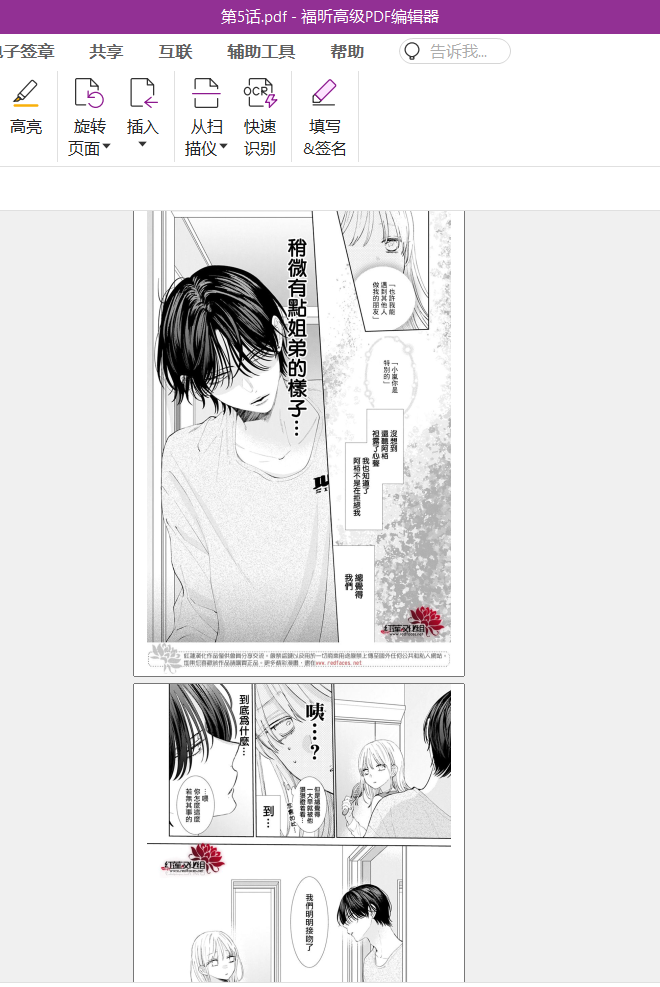
呃呃,如果是这部或者其他比较离谱的漫画(比如交通过于发达)就需要科技TVT…
json文件是来保存中间过程的数据的,可以查看保存位置,和对应每章里每张图片的链接。
图片爬取有一个雷点,若为blob格式就爬不了了,但是视频通过手操还是可爬。
很久之后才发现自己写了这篇爬虫然后搁置了,在github上面的UI也没有更新,还发现了拼接图片的顺序不太对,之后的代码还是参照仓库里面的为准。
之后的UI框子部分也给出参考,因为它就是个美丽的外壳!
没错直接硬写的UI,QT_viewer我放弃你这次,交互什么的还没有写…
JustCrawler.py
from os.path import split
from PyQt5.QtCore import QFile, Qt
from PyQt5.QtGui import QIcon, QPixmap
from PyQt5.QtWidgets import QApplication, QMainWindow, QPushButton, QVBoxLayout, \
QWidget, QHBoxLayout, QTextEdit, QTextBrowser, QLineEdit, QLabel, QTabWidget, QFrame, QFileDialog, QMessageBox
from qt_material import apply_stylesheet
from utils.comics_crawler import ComicsCrawlerForCMH5, PDF_generator
from utils.video_crawler import VideoCrawlerForYHDMDM
from utils.ztool import Auxiliary
class JustCrawlerWindow(QMainWindow):
def __init__(self):
super().__init__()
self.setWindowTitle("JustCrawler")
self.setWindowIcon(QIcon('img/icon.png'))
self.setFixedSize(1048, 800)
# mainframe
main_frame = QFrame()
main_layout = QVBoxLayout(main_frame)
# create TabWidget
self.tabWidget = QTabWidget()
# set banner
pixmap = QPixmap('img/start.png')
banner = QLabel()
banner.setPixmap(pixmap)
banner.setScaledContents(True)
# set tips
tips_label = QLabel("Tips: 这是一个JustCrawler爬虫,请输入 https://www.cmh5.com 链接爬取漫画, https://www.yhdmdm.com 链接爬取视频o("
"QWQ)o")
tips_label.setStyleSheet("color: red")
tips_label.setTextInteractionFlags(Qt.TextSelectableByMouse) # copy enable
# log button
h_layout = QHBoxLayout()
self.log_button = QPushButton('生成日志')
h_layout.addWidget(tips_label)
h_layout.addWidget(self.log_button)
# For CartoonCrawler Page
# first create the container
container = QWidget()
layout = QVBoxLayout(container)
# we need three QHBoxLayout components
self.h_layout_1 = QHBoxLayout()
self.h_layout_2 = QHBoxLayout()
self.h_layout_3 = QHBoxLayout()
self.h_layout_1_1 = QVBoxLayout()
# init everything
self.comics_run = QPushButton(text='RUN')
self.open_file_button = QPushButton(text='打开输入文件')
self.select_save_path = QPushButton(text='选择生成路径')
self.check_crawler_result = QPushButton(text='查看爬取结果')
self.textBrowser = QTextBrowser()
self.textEditor_input = QTextEdit()
self.lineEditor_input_number = QLineEdit()
self.lineEditor_show = QLineEdit()
self.lineEditor_show.setReadOnly(True)
self.textEditor_input.setPlaceholderText('请输入爬取漫画链接')
self.textBrowser.setPlaceholderText('~~~爬虫活动日志~~~')
# for 1: textEditor + button
self.h_layout_1.addWidget(self.textEditor_input)
self.h_layout_1_1.addWidget(self.lineEditor_input_number)
self.h_layout_1_1.addWidget(self.comics_run)
container_1_1 = QWidget()
# 将布局添加到容器中
container_1_1.setLayout(self.h_layout_1_1)
# 设置容器的固定大小
container_1_1.setFixedSize(100, 100)
self.h_layout_1.addWidget(container_1_1)
# for 2: lineEditor + button
self.h_layout_2.addWidget(self.lineEditor_show)
self.h_layout_2.addWidget(self.open_file_button)
# for 3: two buttons
self.h_layout_3.addWidget(self.select_save_path)
self.h_layout_3.addWidget(self.check_crawler_result)
layout.addLayout(self.h_layout_1)
layout.addLayout(self.h_layout_2)
layout.addLayout(self.h_layout_3)
layout.addWidget(self.textBrowser)
# layout.addWidget(tips_label)
# For VideoCrawler
container_ = QWidget()
layout_ = QVBoxLayout(container_)
self.textBrowser_ = QTextBrowser()
self.textEditor_input_web = QTextEdit()
self.textEditor_input_m3u8 = QTextEdit()
self.lineEditor_show_ = QLineEdit()
self.lineEditor_show_.setReadOnly(True)
self.textEditor_input_web.setPlaceholderText('请输入爬取视频链接')
self.textEditor_input_m3u8.setPlaceholderText('请输入对应的m3u8链接')
self.textBrowser_.setPlaceholderText('~~~爬虫活动日志~~~')
# string input / file input
self.h_layout_4 = QHBoxLayout()
self.h_layout_5 = QHBoxLayout()
self.h_layout_6 = QHBoxLayout()
self.video_run = QPushButton(text='RUN')
self.open_m3u8_file = QPushButton(text='打开输入m3u8链接文件')
self.select_save_path_ = QPushButton(text='选择生成路径')
self.check_crawler_result_ = QPushButton(text='查看爬取结果')
# for 4: textEditor + button
self.h_layout_4.addWidget(self.textEditor_input_web)
self.h_layout_4.addWidget(self.video_run)
# for 5: lineEditor + button
self.h_layout_5.addWidget(self.lineEditor_show_)
self.h_layout_5.addWidget(self.open_m3u8_file)
# for 6: 2 buttons
self.h_layout_6.addWidget(self.select_save_path_)
self.h_layout_6.addWidget(self.check_crawler_result_)
layout_.addLayout(self.h_layout_4)
layout_.addWidget(self.textEditor_input_m3u8)
layout_.addLayout(self.h_layout_5)
layout_.addLayout(self.h_layout_6)
layout_.addWidget(self.textBrowser_)
self.tabWidget.addTab(container, "CartoonCrawler")
self.tabWidget.addTab(container_, "VideoCrawler")
# set main layout
main_layout.addWidget(banner)
main_layout.addWidget(self.tabWidget)
main_layout.addLayout(h_layout)
# global variable
# self.comics_string = None
# self.comics_input_path = []
self.comics_save_path = None
# self.video_string = None
# self.video_input_path = []
# self.video_m3u8_path = []
self.video_save_path = None
self.tool = Auxiliary()
self.setCentralWidget(main_frame)
self.function_connect()
def function_connect(self):
# For comics crawler
self.comics_run.clicked.connect(self.comics_RUN)
self.open_file_button.clicked.connect(self.comics_openFile)
self.select_save_path.clicked.connect(self.comics_saveFile)
self.check_crawler_result.clicked.connect(self.check_crawler_result_FUN)
# For video crawler
self.video_run.clicked.connect(self.video_RUN)
self.open_m3u8_file.clicked.connect(self.video_openFile)
self.select_save_path_.clicked.connect(self.video_saveFile)
self.check_crawler_result_.clicked.connect(self.check_crawler_result_FUN)
# For log generator
self.log_button.clicked.connect(self.log_generator)
# others
def comics_RUN(self):
# Main codes
pass
def video_RUN(self):
pass
def open_input_file(self):
file_path, _ = QFileDialog.getOpenFileName(self, "选择输入文件", "", "All Files (*);;Text Files (*.txt)")
return file_path
def select_save_path_FUN(self):
folder_path = QFileDialog.getExistingDirectory(self, "选择保存路径", "")
return folder_path
def check_crawler_result_FUN(self):
pass
def log_generator(self):
logging = None
if self.getTabStatus() == 'CartoonCrawler':
logging = self.textBrowser.toPlainText()
elif self.getTabStatus() == 'VideoCrawler':
logging = self.textBrowser_.toPlainText()
if logging:
# 创建新文件对话框
directory = QFileDialog.getExistingDirectory(self, "选择文件夹", "")
if directory:
file_dialog = QFileDialog(self)
file_dialog.setWindowTitle("新建文件")
file_dialog.setNameFilters(["Log Files (*.log)", "Text Files (*.txt)"])
file_dialog.setDirectory(directory)
file_dialog.setLabelText(QFileDialog.Accept, "保存")
file_dialog.setLabelText(QFileDialog.Reject, "取消")
if file_dialog.exec_() == QFileDialog.Accepted:
log_path = file_dialog.selectedFiles()[0]
_, log_name = split(log_path)
log_path = self.tool.log_generator(logging, log_name, log_path)
print('success')
else:
print('failed')
else:
print('日志无内容')
def getTabStatus(self):
current_tab_index = self.tabWidget.currentIndex()
current_tab_name = self.tabWidget.tabText(current_tab_index)
return current_tab_name
def comics_openFile(self):
comics_input_path = self.open_input_file()
self.lineEditor_show.setText(comics_input_path)
def video_openFile(self):
video_input_path = self.open_input_file()
self.lineEditor_show_.setText(video_input_path)
test_contents = self.HandleInputM3U8()
self.textBrowser_.append(test_contents)
def comics_saveFile(self):
self.comics_save_path = self.select_save_path_FUN()
def video_saveFile(self):
self.video_save_path = self.select_save_path_FUN()
# noinspection DuplicatedCode
def HandleInputWeb(self):
if self.getTabStatus() == 'CartoonCrawler':
input_string = self.textEditor_input.toPlainText()
input_file = self.lineEditor_show.text()
if input_string and input_file:
input_string = self.tool.remove_string_list_tags(input_string)
with open(input_file, 'r') as file:
input_content = file.read()
input_content = self.tool.remove_string_list_tags(input_content)
merge_list = input_string + input_content
merge_list = list(set(merge_list))
return merge_list
elif input_string and not input_file:
input_string = self.tool.remove_string_list_tags(input_string)
return input_string
elif input_file and not input_string:
with open(input_file, 'r') as file:
input_content = file.read()
input_content = self.tool.remove_string_list_tags(input_content)
return input_content
else:
return False
else:
input_string = self.textEditor_input_web.toPlainText()
if input_string:
input_string = self.tool.remove_string_list_tags(input_string)
return input_string
else:
return False
def HandleInputM3U8(self):
if self.getTabStatus() == 'VideoCrawler':
m3u8_string = self.textEditor_input_m3u8.toPlainText()
m3u8_file = self.lineEditor_show_.text()
if m3u8_string and m3u8_file:
m3u8_string = self.tool.remove_string_list_tags(m3u8_string)
with open(m3u8_file, 'r') as file:
m3u8_content = file.read()
m3u8_content = self.tool.remove_string_list_tags(m3u8_content)
merge_list = m3u8_string + m3u8_content
merge_list = list(set(merge_list))
return merge_list
elif m3u8_string and not m3u8_file:
input_string = self.tool.remove_string_list_tags(m3u8_string)
return input_string
elif m3u8_file and not m3u8_string:
with open(m3u8_file, 'r') as file:
m3u8_content = file.read()
m3u8_content = self.tool.remove_string_list_tags(m3u8_content)
return m3u8_content
else:
return False
else:
return False
if __name__ == '__main__':
app = QApplication([])
just_crawler = JustCrawlerWindow()
apply_stylesheet(app, theme='light_purple_500.xml', invert_secondary=True)
just_crawler.show()
app.exec_()
效果图:


最后:我的项目链接
这个坑可能要等我毕业的时候再补…因为我又开始搞新东西了…


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









