









 本文深入探讨了Spark Streaming的核心概念DStream,介绍了其在实时数据流处理中的作用及实现方式。通过具体示例,展示了如何使用DStream进行WordCount统计,解析了DStream的创建过程及其内部结构。
本文深入探讨了Spark Streaming的核心概念DStream,介绍了其在实时数据流处理中的作用及实现方式。通过具体示例,展示了如何使用DStream进行WordCount统计,解析了DStream的创建过程及其内部结构。
spark-streaming
概述
SparkStreaming用于流式数据的处理,支持很多数据源

和spark基于rdd的概念类似,sparkStreaming使用离散化流(discretized stream)作为抽象表示,叫DStream。Dstream是随着时间推移而收到的数据的序列。在内部,每个时间区间收到的数据都作为RDD存在,而DStream是由这些RDD所组成的序列。
特点
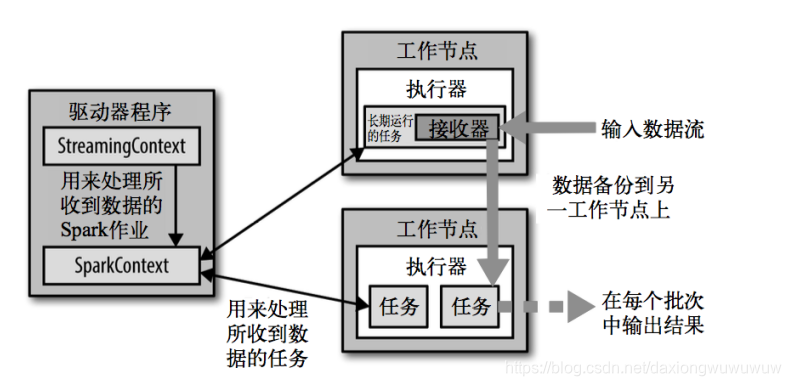
易用、容错、架构如下
DStream
Wordcount
1.需求:netcat工具(windows下载netcat配置path即可,nc -l -p 8080)不断往8080发数据,用SparkSTreaming读取端口数据并统计不同单词出现的次数
2.依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>2.1.1</version>
</dependency>
代码:
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.SparkConf
object StreamWordCount {
def main(args: Array[String]): Unit = {
//初始化配置sparkCOnf,然后初始化上下文ssc
var sparkConf = new SparkConf().setMaster("local[*]").setAppName("StreamWordCount")
var ssc = new StreamingContext(sparkConf, Seconds(5))
ssc.sparkContext.setLogLevel("Warn")
val lineStreams = ssc.socketTextStream("localhost",8080)
//将每一行数据做切分,形成一个个单词
val wordStreams = lineStreams.flatMap(_.split(" "))
//将单词映射成元组(word,1)
val wordAndOneStreams = wordStreams.map((_, 1))
//将相同的单词次数做统计
val wordAndCountStreams = wordAndOneStreams.reduceByKey(_+_)
//打印
wordAndCountStreams.print()
//启动SparkStreamingContext
ssc.start()
ssc.awaitTermination()
}
}
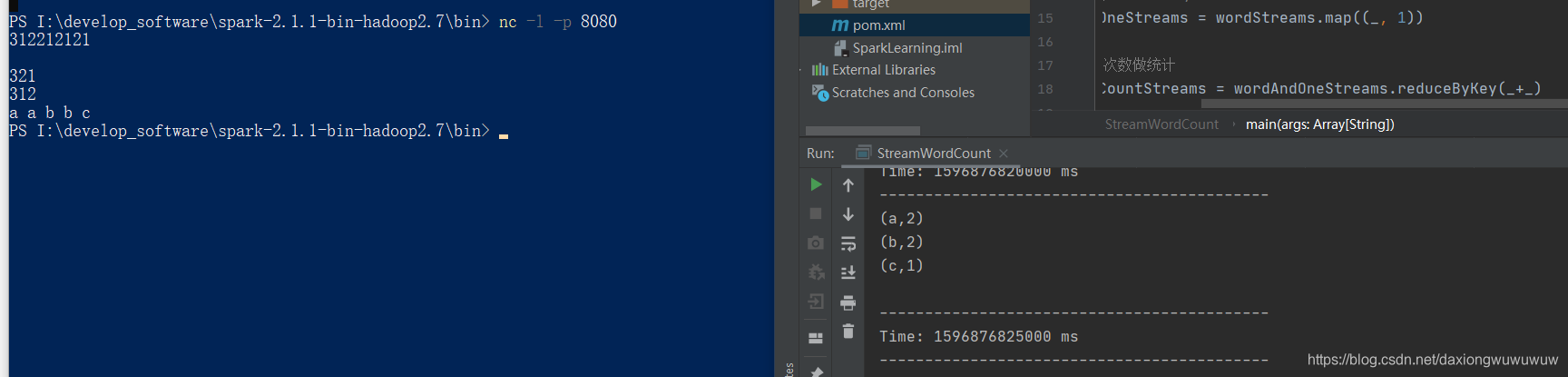
wordCount解析
Discretized Stream是Spark Streaming的基础抽象,代表持续性的数据流和经过各种Spark原语操作后的结果数据流。在内部实现上,DStream是一系列连续的RDD来表示。每个RDD含有一段时间间隔内的数据
Dstream的创建
Spark Streaming原生支持一些不同的数据源。一些“核心”数据源已经被打包到Spark Streaming 的 Maven 工件中,而其他的一些则可以通过 spark-streaming-kafka 等附加工件获取。每个接收器都以 Spark 执行器程序中一个长期运行的任务的形式运行,因此会占据分配给应用的 CPU 核心。此外,我们还需要有可用的 CPU 核心来处理数据。这意味着如果要运行多个接收器,就必须至少有和接收器数目相同的核心数,还要加上用来完成计算所需要的核心数。例如,如果我们想要在流计算应用中运行 10 个接收器,那么至少需要为应用分配 11 个 CPU 核心。所以如果在本地模式运行,不要使用local[1]。

















 715
715

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









