



 本文详细介绍了Python中的序列数据类型如列表和元组的创建、索引、切片以及基本操作,还涵盖了字典和集合的使用,包括数据结构、函数、类和模块等内容,适合初学者理解基础编程概念。
本文详细介绍了Python中的序列数据类型如列表和元组的创建、索引、切片以及基本操作,还涵盖了字典和集合的使用,包括数据结构、函数、类和模块等内容,适合初学者理解基础编程概念。
序列数据结构
*序列数据结构:成员是有序排列的
*每个元素的位置成为下表或索引
*通过索引访问程序中的成员
*Python中的序列数据类型有字符串、列表、元组、"abc"≠"cba"
创建列表和元组
Python中的列表和元组可以存放不同类型的数据。
列表:使用方括号‘[ ]'表示
元组:使用小括号‘( )’表示 元组定义后,内容不能更改。
列表:
lst_1=[2,3,1]
lst_2=[2]
lst_3=[[1,3,2],[3,6,5]]
lst_max=[8798,"ziboo",2,[9,0,8]]
lst_empty=[]
元组:
t1=(1)#创建只有一个元素的元组使不能使用这种
t1=(1,)#创建只有一个元素的元组
print("t1=",t1,type(t1))
t1=1 <class'int'>
print("t2=",t2,type(t2))
t2=(1,) <class'tple'>
索引
#字符串索引
str_py = "Python"
print(str_py[0])
print(str_py[1])
#列表索引
lst_1=[1,2,3]
print(lst_1[1])
print(lst_1[-2])#从后到前的第二个元素
切片
[开始位置:结束位置] 切片不包括结束位置的元素一次性从序列中获取多个元素,得到序列的子集。
开始位置省略:从序列中第一个元素开始。
结束位置省略:取到序列中的最后一个元素。
#字符串切片
str_py = "Python"
print(str_py[1:5])
str_py = "Python"
print(str_py[:3])
str_py = "Python"
print(str_py[3:])
[Running] python -u
ytho
Pyt
hon
#列表切片
list1=[1,2,3]
print(list1[2:])
[Running] python -u
[3]
打印:print() print(序列数据结构名称):输出整个序列
获取序列长度:len(序列名称)
更新列表:向列表中添加元素
#append()函数
lst_1=[1,2,3]
lst_1.append(4)
print(lst_1)
#insert函数
lst_2=[1,2,3]
lst_2.insert(1,4)
print(lst_2)
[Running] python -u
[1, 2, 3, 4]
[1, 4, 2, 3]
合并列表:extend()或“+”运算符
删除列表中的元素:del +语句
元素排序:sort()
元素到排序:reverse()
字典和集合
字典
字典:{键:值,键:值,……}
dic_score={"语文":80,"数学":90,"英语":60}
dic_employ={"name":"ziboo","age":18}
dic_employ={"name":{"first":"Boogie","last":"ziboo"},"age":18}
打印字典::访问字典中的元素
判断字典中是否存在元素——in运算符,返回布尔值
dic_score={"语文":80,"数学":90,"英语":60}
"语文" in dic_score
遍历字典的元素:keys():返回字典中所有的关键字
values():返回字典中所有的值
items():返回字典中所有的键值对
dic_score={"语文":80,"数学":90,"英语":60}
for key in dic_score.key():
print(key,end=" ")
格式化输出:
dic_score={"语文":80,"数学":90,"英语":60}
for key,val in dic_score.item():
print("student[%s]=" %(key),val)
[Running] python -u
student[����]= 80
student[��ѧ]= 90
student[Ӣ��]= 60
更新字典:添加元素,修改指定元素的取值
dic_score={"name":ziboo,"score":90,"high":190}
dic_score['weight'] = 140#增加
dic_score['weight'] = 130#修改
字典合并:dic_score.update(dic_student)
删除字典中的元素:pop(指定元素的关键字) clear() del语句
集合
集合:由一组无序排列的元素组成
可变集合 (set)
不可变集合 (frozenset)
set_1=set("Python")
print(set_1)
set_2=frozenset("Python")
print(set_2)
[Running] python -u
{'h', 'P', 'o', 'y', 'n', 't'}
frozenset({'h', 'P', 'o', 'y', 'n', 't'})
函数
*实现某种特定功能的代码块
*陈旭简洁,可重复调用、封装性好、便于共享
*系统函数和用户自定义函数
内置函数
数学运算函数 输入输出函数 类型转换函数 逻辑判断函数 序列操作函数 对象操作函数等
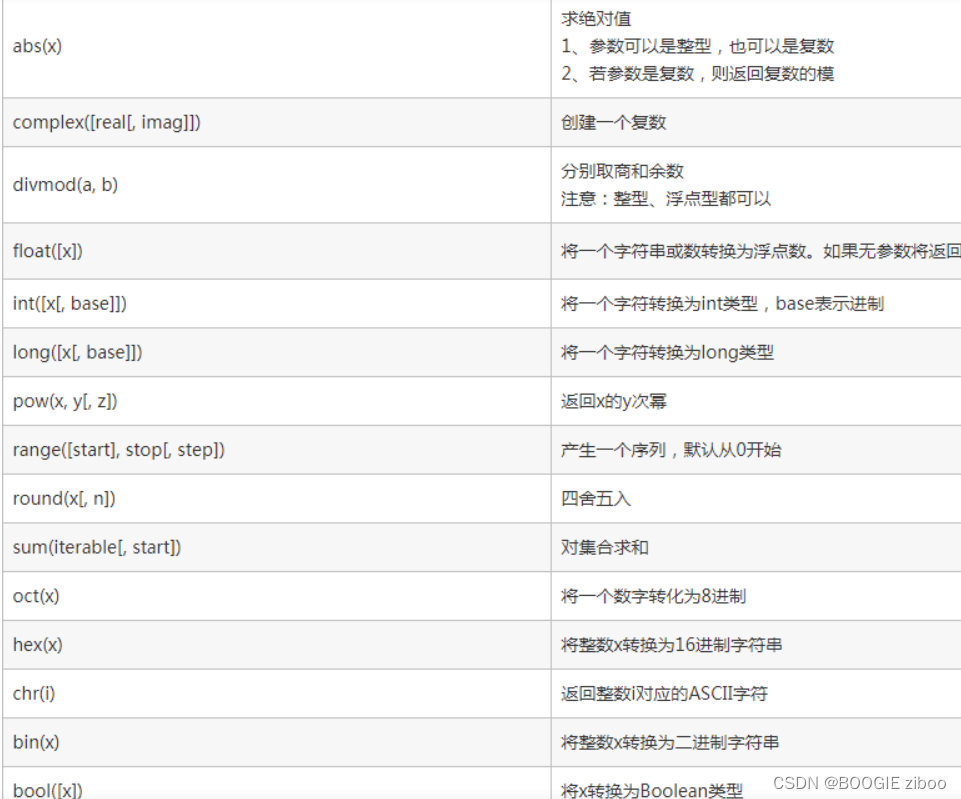
用户自定义的函数
定义函数:函数名、参数和返回值
调用函数:函数名(参数列表)
def add(a,b)#定义
c=a+b
return c
add(1,2)#调用
多元赋值语句可以同时获取多个返回值,参数后必须加小括号!!!
变量的作用域
*局部变量:在函数定义的变量,仅在定义它的函数内部有效
*全局变量:在函数体之外定义的变量,在定义后的代码中都有效,包括在他之后定义的函数体内。
函数的参数-参数的传递
*按值传递:形参和实参分别储存,相互独立。
*在内部函数改变形参的值时,实参的值不会随之改变
函数的参数-参数的默认值
def 函数名(参数1=默认值,参数2=默认值……)
函数体
只能从右往左依次设置
函数的参数-向函数内部批量传递数据
可以使用列表,字典变量作为参数,向函数内部批量传递数据
def sum(list):
sum=0
for x in list:
sum+=x
return sum
lst_1=[1,2,3,4,5]
print(sum(lst_1))
运行结果:15
模块、包和库
模块(Module):模块是一个python文件 (.py),拥有多个功能相近的函数或类,便于代码复用,提高编程效率,提高代码的可维护性。可以避免函数名和变量名冲突。
包(Package):为了避免模块名冲突,Python引入按目录来组织模块的方法。一个包对应一个文件夹,将功能相近的模块(Python文件),放在同一个文件夹下。 在作为包的文件夹下有一个__init__.py文件。
子包:子目录中也有__init__.py文件。
import numpy as np #导入名为numpy的包 简写为np
np.random.random()
导入语句的作用域:
*在程序顶部导入模块,作用域是全局的
*在函数内部导入语句,作用域是局部 的
创建自定义模块:将常用的函数的定义放在一个.py文件中。例如创建一个mymodule.py,在需要使用时可直接import mymodule as mm
Python标准库是python自带的开发包
sys模块:提供有关Python运行环境的变量和函数

Python面对对象编程
类(class):具有相同的属性和方法的对象集合
*对象是类的实例
*子类继承了父类的全部属性和方法,并且也有自己特有的属性和方法。
*继承 描述了类之间的层次关系
声明类:
类属性是类中所有对象共同拥有的属性,他在内存中只存在一个副本,它可以通过类名访问,也可以被类的所有对象访问,在类定义之后,可以通过类名添加类属性新增的类属性也被类和所有对象共有
class Person():
money=10000
def say_hello(slef):
print("Hello")
ziboo = Person()
print(ziboo.money)
ziboo.say_hello()
[Running] python -u
10000
Hello
添加对象属性:
ziboo.major="Python" #这个属性只属于ziboo
删除对象
del ziboo
构造函数
构造函数:在创建对象时,用来完成初始化操作。
析构函数:在清楚对象时,回收和释放对象所占用的资源。
class Person():
def __init__(self,name,age,gender="man"): #设置默认值男
self.name=name
self.age=age
self,gender=gender
def __del__(self):
print("see you",self.name)
def printInfo(self):
print("姓名:",self.name,"年龄:",self.age,"性别:",self.gender)
zhangsan=Person("张三",18)
lisi.Person("李四",19,"女")
zhangsan.printInfo() #输出
lisi.printInfo
del zhangsan #删除时调用see you
类方法:可以通过类名或对象名调用,不能访问实例属性,可以访问类属性。
静态:可以通过类名或对象名调用,不能访问实例属性,也不能直接访问类属性。但是可以通过类名访问类属性
共有变量:可以在类外部访问
保护变量:只能运行其本身和子类进行访问 : _xxx
私有变量:不允许在类的外部访问 :__xxx
继承
子类能够继承父类中所有非私有成员变量和成员函数
class 子类名(父类名)
类属性=初值
方法(参数列表)
class Person():
money=10000
def say_hello(self):
print("HELLO")
class Teacher(Person):
pass
amy =Teacher()
print(ame.money)
amy.say_hello()
结果:10000
HELLO
文件
打开文件:open(文件名,访问模式)可以是绝对路径也可以是相对路径
获取当前路径:
import os
print(os.getcwd())
关闭文件:文件对象.close()
读取文件内容:文件对象.read
文件对象.readline():逐行输出
read readline 括
号里可以加读取的字节数。
向文件中写入数据:write(写入内容)
在使用write函数之前,要确保open()函数的访问模式是支持写入的,写入成功后,会返回一个字符数,是一个整数。
f = open("myfile.txt","w")
f.write("Hello")
异常
try-except语句
try:
aList = [1,2,3]
print(aList[3])
print("try continue..")
except IndexError as e:
print(e)
print("existing")
print("continue..")
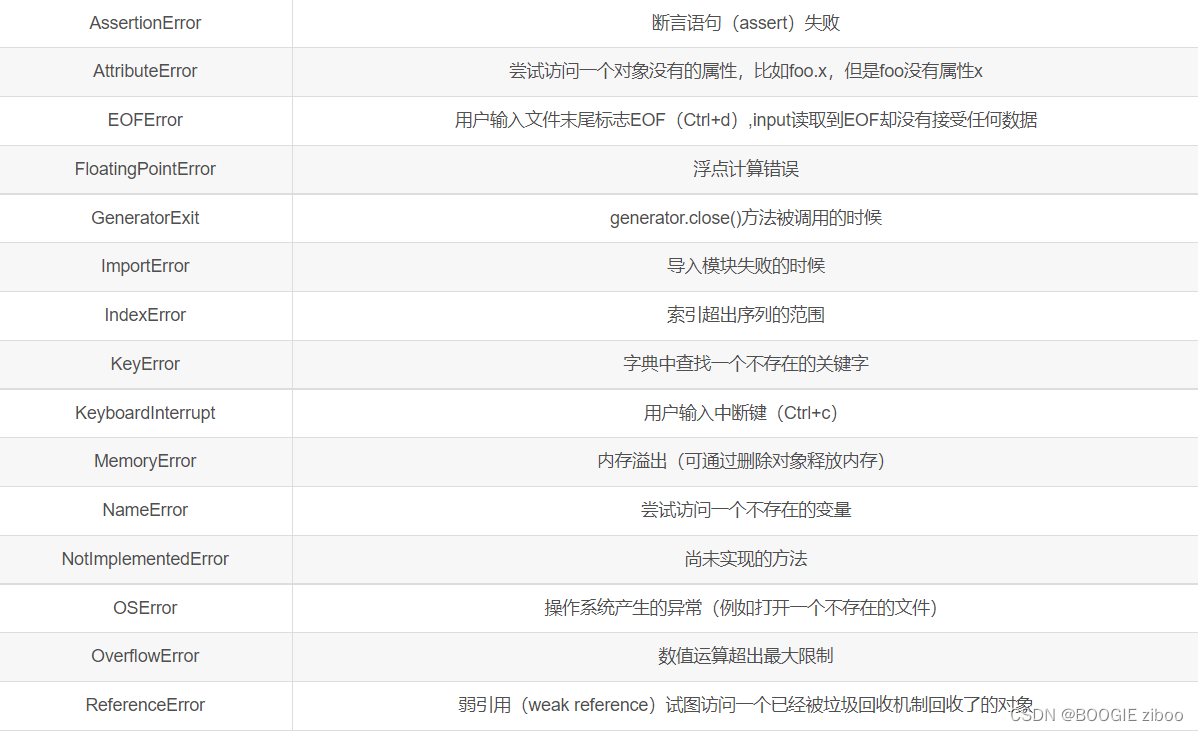
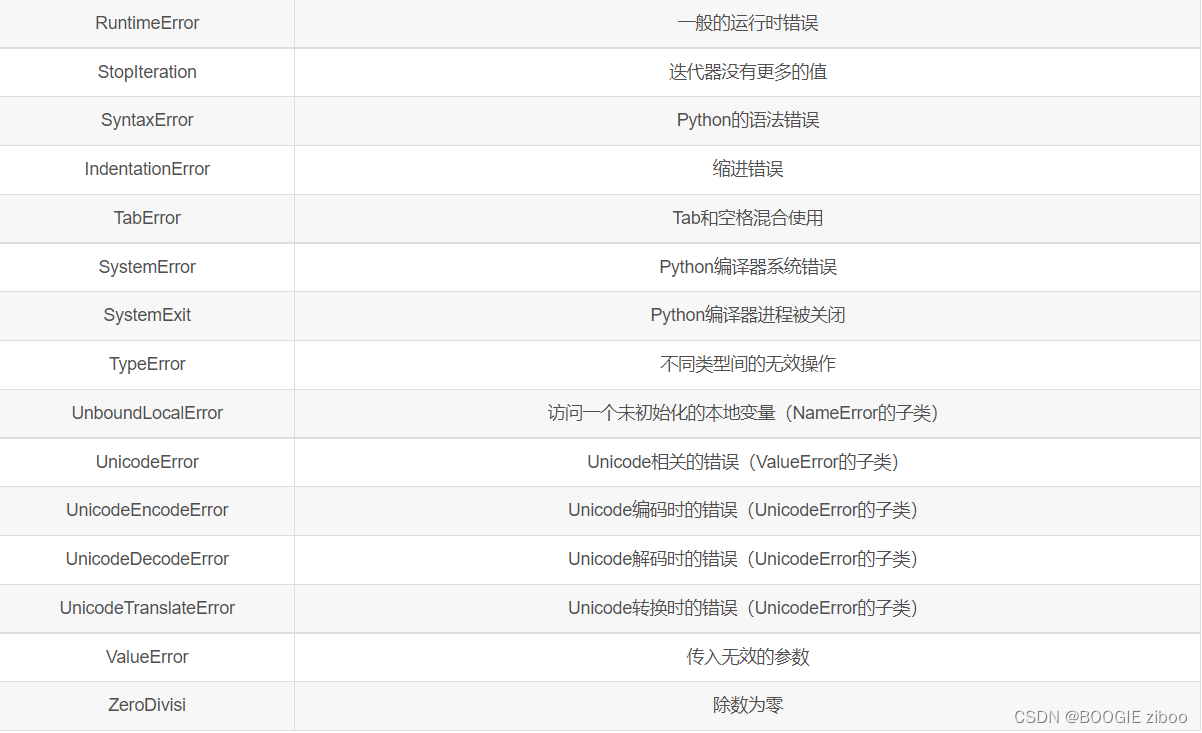
finally子句:无论如何都会执行的语句块:
finally:
print("close")
f.close()
with语句:运行完就关闭。:with open(。。。。。) as f:


















 1298
1298

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











