




 本文介绍如何使用飞桨的图像分类套件PaddleClas进行模型训练、评估及推理全流程。涵盖环境搭建、数据集准备、模型训练配置、模型评估及部署等关键步骤。
本文介绍如何使用飞桨的图像分类套件PaddleClas进行模型训练、评估及推理全流程。涵盖环境搭建、数据集准备、模型训练配置、模型评估及部署等关键步骤。
飞桨图像分类套件PaddleClas是飞桨为工业界和学术界所准备的一个图像分类任务的工具集,助力使用者训练出更好的视觉模型和应用落地。
https://github.com/PaddlePaddle/PaddleClas
截至2020-12-10最新版本PaddleClas需要需要PaddlePaddle 2.0rc或更高版本,有些新的方法在稳定版本1.8.5中没有。
安装方法:https://www.paddlepaddle.org.cn/install/quick/zh/2.0rc-windows-pip
python -m pip install paddlepaddle-gpu==2.0.0rc0 -f https://paddlepaddle.org.cn/whl/stable.html我的运行环境:
- Python3.7
- CUDA= 10.2
- cuDNN >= 8.0.3
克隆PaddleClas模型库:
cd path_to_clone_PaddleClas
git clone https://github.com/PaddlePaddle/PaddleClas.git
安装Python依赖库:
Python依赖库在requirements.txt中给出,可通过如下命令安装:
pip install --upgrade -r requirements.txt数据准备:
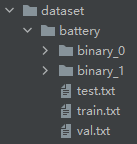
将数据拷贝到项目的dataset目录下,目录结构如上图
battery为名称目录
binary_0和binary_1为2个分类目录,每个目录下存放对应类别图片
test.txt train.txt val.txt为存放图片路径及分类的文件,通过下方的分隔数据集代码生成
分割数据集代码:
import os
import numpy as np
img_dir = r'battery'
classes_dict = {}
split_sets = {'train': [], 'val': [], 'test': []}
go = os.walk(img_dir)
for path, d, fileList in go:
for c in d:
if len(c) > 0:
classes_dict[c] = []
for index, filename in enumerate(fileList):
if filename.endswith(('jpg', 'png', 'bmp')):
class_name = os.path.basename(path)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1465
1465






 到【灌水乐园】发言
到【灌水乐园】发言







