







前言:
环境:
阿里 VPM:jpn 位置在东京, 20GB vSSD, 0.5GB vMem, Ubuntu 24
网盘: Baidu Pan
目的:
使用 VPM 用做缓存来周转模型文件到狗度网盘,解决网络慢的问题。
但今天正在测试时,阿里云上的主机被减速了...

以上是工单内容,我想传个图回复,一直卡着。
程序功能:
从 Hugging Face 下载模型并传输到百度网盘的工具,组成:
一个 Bash Shell:run_transfer.sh
一个 Python file:auto_transfer.py
特点:
- 输出下载命令到 2 个存储文件:
- download_commands.txt
- download_commands_large.txt
- 日志文件,记录执行过程:transfer_script.log
- 对大文件按照大小排序,从小到大下载
- 下载前检查磁盘空间
- 跳过 original/ 和 .git 目录
- 预留 5GB 最小空间要求
- 下载失败恢复功能 ,自动重试
基础运行环境:
- 系统中要已经安装如下:
- Python 虚拟环境(/root/venv)
-
apt update apt install python3 python3-venv python3-pip python -m venv /root/venv -
Hugging Face CLI
-
source /root/venv/bin/activate pip install huggingface_hub huggingface-cli requests pip install --upgrade huggingface_hub pip install --upgrade huggingface-cli
-
-
- BaiduPCS-Go 客户端
- 下载源 GitHub - qjfoidnh/BaiduPCS-Go: iikira/BaiduPCS-Go原版基础上集成了分享链接/秒传链接转存功能
- 我调整的参数:
- 同时进行上传文件的最大数量:BaiduPCS-Go config set --max_upload_load 1
- 上载文件最大并发量:BaiduPCS-Go config set --max_upload_parallel 1 #不切割文件并发上传,即以单个文件上传
- 上载遇到重名文件覆盖:BaiduPCS-Go config set --upload_policy overwrite
- PCS 服务器地址(找ping得快的,日本到这里是 54ms):BaiduPCS-Go config set --pcs_addr c3.pcs.baidu.com
- Python 虚拟环境(/root/venv)
- HuggingFace 设置
- 有 Access Token https://huggingface.co/settings/tokens
- 在 Python venv 已经登录 HuggingFace :huggingface-cli login
- 文件 /root/.huggingface/token 已经存在 (上面命令,正常登录后会创建)
- 查询是:在 Python venv 中, 执行: huggingface-cli whoami #返回是你的 HF 注册名
- BaiduPCS-Go 已正确配置
- 配置文件 Linux: ~/.config/BaiduPCS-Go/pcs_config.json 里面 "bduss": “你的BDUSS” 是有效的
- 获取 Baidu BDUSS 我是看这篇文章:百度网盘BDUSS获取教程-优快云博客
- 两个脚本文件要会在一起
- 本文件要有执行权限
-
chmod +x run_transfer.sh -
chmod 644 auto_transfer.py
-
这么看,还挺复杂的。
运行方法:
自行修改目录:
下载目录: “/root/download/ai” 如需修改在 auto_transfer.py 中 “base_dir="/root/download/ai"”
上传目录,百度盘:/shared/<模型名>
1 复制所需要有模型名:
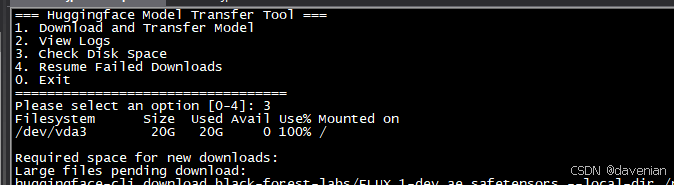
2 在 Shell 中执行:
./run_transfer.sh 3. 换界面操作:
4. 狗度盘查收

脚本代码:
1. 主程序 auto_transfer.py
# Created by Dave on 29Jan2025
# History 0.7
# Ver.0.4 rebuilt this script
# Ver.0.5 rebuilt the run_transfer.sh for UI input
# Ver.0.6 handle disk space warnings
# Ver.0.7 adding prompts for existing files and directories confirmation.
import os
import subprocess
import time
from huggingface_hub import list_repo_files, hf_hub_url, HfApi
from huggingface_hub.utils import HfHubHTTPError
import logging
import requests
from urllib3.util.retry import Retry
from requests.adapters import HTTPAdapter
# logging
logging.basicConfig(
filename='model_transfer.log',
level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s'
)
class ModelTransferManager:
def __init__(self, repo_name, base_dir="/root/download/ai"):
self.repo_name = repo_name
self.base_dir = base_dir
self.save_dir = f"{base_dir}/{repo_name.replace('/', '--')}"
self.min_space_required = 5 * 1024 * 1024 * 1024 # 5GB in bytes
self.baidu_target_dir = f"/shared/{repo_name.replace('/', '--')}"
self.session = self._create_session()
self.api = HfApi()
def _create_session(self):
session = requests.Session()
retries = Retry(
total=5,
backoff_factor=1,
status_forcelist=[500, 502, 503, 504]
)
session.mount('https://', HTTPAdapter(max_retries=retries))
return session
def check_baidu_directory_exists(self):
try:
result = subprocess.run(['BaiduPCS-Go', 'ls', self.baidu_target_dir],
capture_output=True, text=True)
return result.returncode == 0
except Exception:
return False
def prompt_for_replacement(self, path, type_str="directory"):
while True:
response = input(f"{type_str} '{path}' already exists. Replace? (y/n): ").lower()
if response in ['y', 'n']:
return response == 'y'
print("Please enter 'y' for yes or 'n' for no.")
def create_baidu_directory(self):
try:
if self.check_baidu_directory_exists():
if not self.prompt_for_replacement(self.baidu_target_dir, "Baidu Pan directory"):
logging.info("User chose not to replace existing Baidu Pan directory")
raise ValueError("Operation cancelled by user - directory exists")
subprocess.run(['BaiduPCS-Go', 'rm', self.baidu_target_dir], check=True)
logging.info(f"Removed existing Baidu Pan directory: {self.baidu_target_dir}")
subprocess.run(['BaiduPCS-Go', 'mkdir', self.baidu_target_dir], check=True)
logging.info(f"Created directory in Baidu Pan: {self.baidu_target_dir}")
except subprocess.CalledProcessError as e:
logging.error(f"Error managing Baidu Pan directory: {e}")
raise
def get_available_space(self):
"""Get available space in bytes"""
df = subprocess.check_output(['df', '/']).decode().split('\n')[1]
available_bytes = int(df.split()[3]) * 1024
return available_bytes
def get_file_size(self, file_info):
"""Get file size from HuggingFace API"""
try:
size = file_info.size if hasattr(file_info, 'size') else None
if size is None:
url = hf_hub_url(self.repo_name, file_info.rfilename)
response = requests.head(url, allow_redirects=True)
size = int(response.headers.get('content-length', 0))
return size
except Exception as e:
logging.error(f"Error getting file size for {file_info}: {e}")
return None
def check_space_requirements(self, files):
available_space = self.get_available_space()
total_size = 0
large_files = []
for file in files:
if isinstance(file, str):
filename = file
else:
filename = file.rfilename if hasattr(file, 'rfilename') else str(file)
if self.is_large_file(filename):
size = self.get_file_size(file) if not isinstance(file, str) else None
if size:
total_size += size
large_files.append((filename, size))
if total_size > available_space:
error_msg = (
f"Not enough disk space available.\n"
f"Required space: {total_size / (1024**3):.2f} GB\n"
f"Available space: {available_space / (1024**3):.2f} GB\n"
"Large files found:\n"
)
for fname, size in large_files:
error_msg += f"- {fname}: {size / (1024**3):.2f} GB\n"
raise ValueError(error_msg)
def is_large_file(self, filename):
return filename.endswith('.safetensors')
def get_file_list_with_retry(self, max_retries=5):
for attempt in range(max_retries):
try:
files = list_repo_files(self.repo_name)
return files
except HfHubHTTPError as e:
if "500 Server Error" in str(e) and attempt < max_retries - 1:
wait_time = (attempt + 1) * 5
logging.warning(f"Attempt {attempt + 1} failed. Waiting {wait_time} seconds before retry...")
time.sleep(wait_time)
else:
raise
raise Exception("Failed to get file list after maximum retries")
def process_model_files(self):
"""Main process to handle model files"""
try:
if os.path.exists(self.save_dir):
if not self.prompt_for_replacement(self.save_dir, "Local directory"):
logging.info("User chose not to replace existing local directory")
raise ValueError("Operation cancelled by user - local directory exists")
subprocess.run(['rm', '-rf', self.save_dir], check=True)
logging.info(f"Removed existing local directory: {self.save_dir}")
os.makedirs(self.save_dir, exist_ok=True)
self.create_baidu_directory()
logging.info(f"Attempting to get file list for repository: {self.repo_name}")
files = self.get_file_list_with_retry()
self.check_space_requirements(files)
download_commands = []
large_file_commands = []
for file in files:
if isinstance(file, str):
filename = file
else:
filename = file.rfilename if hasattr(file, 'rfilename') else str(file)
if 'original/' in filename or '.git' in filename:
continue
cmd = f"huggingface-cli download {self.repo_name} {filename} --local-dir {self.save_dir}"
if self.is_large_file(filename):
size = self.get_file_size(file) if not isinstance(file, str) else None
large_file_commands.append((cmd, size))
else:
download_commands.append(cmd)
large_file_commands.sort(key=lambda x: x[1] if x[1] is not None else 0)
large_file_commands = [cmd for cmd, _ in large_file_commands]
with open('download_commands.txt', 'w') as f:
f.write('\n'.join(download_commands))
with open('download_commands_large.txt', 'w') as f:
f.write('\n'.join(large_file_commands))
logging.info(f"Generated {len(download_commands)} regular and {len(large_file_commands)} large file commands")
return download_commands + large_file_commands
except ValueError as e:
logging.error(str(e))
print(str(e))
raise
except Exception as e:
logging.error(f"Error processing model files: {e}")
raise
class ModelTransferManager:
def __init__(self, repo_name, base_dir="/root/download/ai"):
self.repo_name = repo_name
self.base_dir = base_dir
self.save_dir = f"{base_dir}/{repo_name.replace('/', '--')}"
self.min_space_required = 5 * 1024 * 1024 * 1024 # 5GB in bytes
self.baidu_target_dir = f"/shared/{repo_name.replace('/', '--')}"
self.session = self._create_session()
self.api = HfApi()
self.upload_retries = 3
self.upload_retry_delay = 300 # 5 minutes
def upload_to_baidu(self, local_path):
"""Upload a file or directory to Baidu Pan with retries"""
logging.info(f"Starting upload to Baidu Pan: {local_path} -> {self.baidu_target_dir}")
retry_count = 0
while retry_count < self.upload_retries:
try:
# Verify target directory exists
if not self.check_baidu_directory_exists():
self.create_baidu_directory()
# Start upload with progress monitoring
cmd = [
'BaiduPCS-Go',
'upload',
'--norapid', # Disable rapid upload for reliability
'--retry', '3',
local_path,
self.baidu_target_dir
]
process = subprocess.Popen(
cmd,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE,
universal_newlines=True
)
# Monitor upload progress
while True:
output = process.stdout.readline()
if output == '' and process.poll() is not None:
break
if output:
logging.info(f"Upload progress: {output.strip()}")
if process.returncode == 0:
# Verify upload
if self.verify_upload(local_path):
logging.info(f"Successfully uploaded and verified: {local_path}")
return True
else:
raise Exception("Upload verification failed")
else:
raise Exception(f"Upload process failed with return code: {process.returncode}")
except Exception as e:
retry_count += 1
logging.error(f"Upload attempt {retry_count} failed: {str(e)}")
if retry_count < self.upload_retries:
logging.info(f"Retrying upload in {self.upload_retry_delay} seconds...")
time.sleep(self.upload_retry_delay)
else:
logging.error(f"Upload failed after {self.upload_retries} attempts")
raise
def verify_upload(self, local_path):
"""Verify uploaded file exists and has correct size"""
try:
local_name = os.path.basename(local_path)
remote_path = f"{self.baidu_target_dir}/{local_name}"
# Check remote file exists
result = subprocess.run(
['BaiduPCS-Go', 'meta', remote_path],
capture_output=True,
text=True
)
if result.returncode != 0:
logging.error(f"Failed to verify remote file: {remote_path}")
return False
# Get local file size
local_size = os.path.getsize(local_path)
# Parse remote size from meta output
remote_size = None
for line in result.stdout.splitlines():
if "size" in line.lower():
try:
remote_size = int(line.split(':')[1].strip())
break
except (ValueError, IndexError):
pass
if remote_size is None:
logging.error("Could not determine remote file size")
return False
# Compare sizes
if local_size != remote_size:
logging.error(f"Size mismatch - Local: {local_size}, Remote: {remote_size}")
return False
return True
except Exception as e:
logging.error(f"Verification error: {str(e)}")
return False
def process_model_files(self):
"""Main process to handle model files with upload"""
try:
# Existing download logic...
commands = super().process_model_files()
# After successful download, upload to Baidu Pan
logging.info("Downloads completed, starting Baidu Pan upload...")
# Upload regular files first
small_files = [f for f in os.listdir(self.save_dir)
if os.path.isfile(os.path.join(self.save_dir, f))
and not f.endswith('.safetensors')]
for file in small_files:
local_path = os.path.join(self.save_dir, file)
self.upload_to_baidu(local_path)
# Upload large files
large_files = [f for f in os.listdir(self.save_dir)
if f.endswith('.safetensors')]
for file in large_files:
local_path = os.path.join(self.save_dir, file)
self.upload_to_baidu(local_path)
logging.info("All files uploaded to Baidu Pan successfully")
return commands
except Exception as e:
logging.error(f"Error in process_model_files: {e}")
raise
def main():
import sys
if len(sys.argv) != 2:
print("Usage: python auto_transfer.py <repo_name>")
print("Example: python auto_transfer.py black-forest-labs/FLUX.1-dev")
sys.exit(1)
repo_name = sys.argv[1]
transfer_manager = ModelTransferManager(repo_name)
try:
commands = transfer_manager.process_model_files()
print(f"Generated {len(commands)} download commands.")
print("Commands have been written to download_commands.txt")
print("Large file commands have been written to download_commands_large.txt")
print("Log file is available at model_transfer.log")
except ValueError as e:
print(f"Error: {str(e)}")
sys.exit(1)
except Exception as e:
print(f"Error: {str(e)}")
sys.exit(1)
if __name__ == "__main__":
main()2. 菜单 run_transfer.sh
#!/bin/bash
# This script need to work with auto_transfer.py in same folder.
# Created by Dave Ver.0.5
VENV_PATH="/root/venv"
DEFAULT_REPO="black-forest-labs/FLUX.1-dev"
SCRIPT_DIR="$( cd "$( dirname "${BASH_SOURCE[0]}" )" && pwd )"
LOG_FILE="$SCRIPT_DIR/transfer_script.log"
RETRY_DELAY=300
MAX_RETRIES=3
CRITICAL_DISK_THRESHOLD=95
log_message() {
echo "[$(date '+%Y-%m-%d %H:%M:%S')] $1" | tee -a "$LOG_FILE"
}
get_disk_usage() {
df / | awk 'NR==2 {print $5}' | sed 's/%//'
}
emergency_stop() {
local reason="$1"
log_message "EMERGENCY STOP: $reason"
log_message "Killing all huggingface-cli processes..."
pkill -f "huggingface-cli"
echo "Emergency stop triggered: $reason"
echo "System status:"
df -h /
exit 1
}
check_disk_emergency() {
local usage=$(get_disk_usage)
if [ "$usage" -ge "$CRITICAL_DISK_THRESHOLD" ]; then
emergency_stop "Disk usage is critical (${usage}%) - stopping all operations"
fi
}
monitor_disk_space() {
while true; do
check_disk_emergency
sleep 5
done
}
# Add Baidu Pan configuration
CONFIG_FILE="$SCRIPT_DIR/.transfer_config"
AUTO_UPLOAD=true
# Load configuration
load_config() {
if [ -f "$CONFIG_FILE" ]; then
source "$CONFIG_FILE"
else
# Create default config
echo "AUTO_UPLOAD=$AUTO_UPLOAD" > "$CONFIG_FILE"
fi
}
save_config() {
echo "AUTO_UPLOAD=$AUTO_UPLOAD" > "$CONFIG_FILE"
}
toggle_auto_upload() {
if $AUTO_UPLOAD; then
AUTO_UPLOAD=false
else
AUTO_UPLOAD=true
fi
save_config
echo "自动上传已设置为: $AUTO_UPLOAD"
}
# Manual upload function
manual_upload() {
local download_dir="/root/download/ai"
echo "可上传的目录:"
ls -lh "$download_dir"
echo
read -p "输入要上传的目录名: " dir_name
if [ -d "$download_dir/$dir_name" ]; then
local baidu_target="/shared/$dir_name"
echo "开始上传到百度网盘..."
log_message "Starting manual upload for directory: $dir_name"
# Upload regular files first
find "$download_dir/$dir_name" -type f ! -name "*.safetensors" -print0 | while IFS= read -r -d '' file; do
"$SCRIPT_DIR/baidu_upload.sh" "$file" "$baidu_target"
done
# Upload large files
find "$download_dir/$dir_name" -type f -name "*.safetensors" -print0 | while IFS= read -r -d '' file; do
"$SCRIPT_DIR/baidu_upload.sh" "$file" "$baidu_target"
done
log_message "Manual upload completed for: $dir_name"
else
echo "目录不存在"
fi
}
heck_baidu_status() {
echo "百度网盘上传状态:"
echo "=================="
if [ -f "$SCRIPT_DIR/baidu_upload.log" ]; then
echo "最近的上传记录:"
tail -n 20 "$SCRIPT_DIR/baidu_upload.log"
else
echo "尚无上传日志"
fi
echo
echo "正在检查网盘空间..."
BaiduPCS-Go quota
}
check_disk_space_for_file() {
local required_size=$1 # MB
local available_space=$(df / | awk 'NR==2 {print $4}') # KB
local available_mb=$((available_space / 1024))
local usage=$(get_disk_usage)
if [ "$usage" -ge "$CRITICAL_DISK_THRESHOLD" ]; then
log_message "ERROR: Disk usage is critical (${usage}%)"
return 1
fi
if [ $available_mb -lt $((required_size + 1024)) ]; then
log_message "WARNING: Not enough disk space for file"
log_message "Required: ${required_size}MB (plus 1GB buffer)"
log_message "Available: ${available_mb}MB"
return 1
fi
return 0
}
cleanup() {
pkill -P $$
}
trap cleanup EXIT
execute_download_with_space_check() {
local cmd="$1"
local filename=$(basename "${cmd##* }")
check_disk_emergency
monitor_disk_space &
local monitor_pid=$!
log_message "Checking size for $filename..."
local size_check_output
size_check_output=$(eval "$cmd" 2>&1 | grep "expected file size is")
if [[ $size_check_output =~ "expected file size is: "([0-9.]+)" MB" ]]; then
local required_size=${BASH_REMATCH[1]}
required_size=${required_size%.*}
if ! check_disk_space_for_file "$required_size"; then
kill $monitor_pid
return 1
fi
fi
log_message "Executing: $cmd"
# 使用 tee 来同时显示和记录输出
eval "$cmd" 2>&1 | while IFS= read -r line; do
if [[ $line =~ "Not enough free disk space" ]] || \
[[ $line =~ "No space left on device" ]]; then
kill $monitor_pid
emergency_stop "Disk space exhausted during download"
return 1
fi
if [[ $line =~ "%" ]] || [[ $line =~ ([0-9]+.[0-9]+[[:space:]][KMGTkmgt]?[Bb]/s) ]]; then
log_message "[$filename] $line"
fi
echo "$line"
done
kill $monitor_pid
}
activate_venv() {
if [ -f "$VENV_PATH/bin/activate" ]; then
source "$VENV_PATH/bin/activate"
log_message "Virtual environment activated"
else
log_message "ERROR: Virtual environment not found at $VENV_PATH"
exit 1
fi
}
process_model() {
local repo_name="$1"
local resume_mode="$2"
check_disk_emergency
activate_venv
if [ "$resume_mode" != "resume" ]; then
log_message "Starting transfer process for repository: $repo_name"
python "$SCRIPT_DIR/auto_transfer.py" "$repo_name"
if [ $? -ne 0 ]; then
log_message "ERROR: Failed to generate download commands"
return 1
fi
fi
log_message "Current disk space status:"
df -h / | tee -a "$LOG_FILE"
# Process downloads
local download_success=true
if [ -f "download_commands.txt" ]; then
log_message "Processing regular files..."
while IFS= read -r cmd; do
if [[ ! $cmd =~ .safetensors ]]; then
execute_download_with_space_check "$cmd"
if [ $? -ne 0 ]; then
log_message "ERROR: Download failed due to insufficient space"
download_success=false
break
fi
fi
done < "download_commands.txt"
fi
if $download_success && [ -f "download_commands_large.txt" ]; then
log_message "Processing large files..."
while IFS= read -r cmd; do
execute_download_with_space_check "$cmd"
if [ $? -ne 0 ]; then
log_message "ERROR: Download failed due to insufficient space"
download_success=false
break
fi
sleep 3
done < "download_commands_large.txt"
fi
# Start Baidu Pan upload if downloads were successful
if $download_success; then
local download_dir="/root/download/ai/${repo_name/\//__}"
local baidu_target="/shared/${repo_name/\//__}"
log_message "Starting Baidu Pan upload process..."
# Upload regular files first
log_message "Uploading regular files..."
find "$download_dir" -type f ! -name "*.safetensors" -print0 | while IFS= read -r -d '' file; do
"$SCRIPT_DIR/baidu_upload.sh" "$file" "$baidu_target"
if [ $? -ne 0 ]; then
log_message "ERROR: Failed to upload regular file: $file"
return 1
fi
done
# Upload large files
log_message "Uploading large files..."
find "$download_dir" -type f -name "*.safetensors" -print0 | while IFS= read -r -d '' file; do
"$SCRIPT_DIR/baidu_upload.sh" "$file" "$baidu_target"
if [ $? -ne 0 ]; then
log_message "ERROR: Failed to upload large file: $file"
return 1
fi
done
log_message "All files uploaded to Baidu Pan successfully"
else
log_message "Skipping Baidu Pan upload due to download failures"
return 1
fi
}
# menu
show_menu() {
clear
echo "=== Huggingface Model Transfer Tool ==="
echo "1. Download and Transfer Model"
echo "2. View Logs"
echo "3. Check Disk Space"
echo "4. Clean Downloaded Files"
echo
echo "百度网盘选项:"
echo "5. 手动上传到百度网盘"
echo "6. 查看上传状态"
echo "7. 查看上传日志"
echo "8. 切换自动上传 (当前: $AUTO_UPLOAD)"
echo "0. Exit"
echo "=================================="
}
clean_downloads() {
local download_dir="/root/download/ai"
echo "Current disk usage:"
df -h /
echo
echo "Available directories to clean:"
ls -lh "$download_dir"
echo
read -p "Enter directory name to remove (or 'all' for everything): " dir_name
if [ "$dir_name" = "all" ]; then
read -p "Are you sure you want to remove all downloaded files? (y/n): " confirm
if [ "$confirm" = "y" ]; then
rm -rf "$download_dir"/*
mkdir -p "$download_dir"
echo "All downloaded files removed"
fi
elif [ -d "$download_dir/$dir_name" ]; then
read -p "Are you sure you want to remove $dir_name? (y/n): " confirm
if [ "$confirm" = "y" ]; then
rm -rf "$download_dir/$dir_name"
echo "Directory $dir_name removed"
fi
else
echo "Directory not found"
fi
echo "Current disk usage after cleaning:"
df -h /
}
while true; do
show_menu
read -p "Please select an option [0-8]: " choice
case $choice in
1)
usage=$(get_disk_usage)
if [ "$usage" -ge "$CRITICAL_DISK_THRESHOLD" ]; then
echo "ERROR: Disk usage is critical (${usage}%)"
echo "Please clean up some space first"
read -p "Press Enter to continue..."
continue
fi
echo "Repository format example: $DEFAULT_REPO"
read -p "Enter repository name (or press Enter for default): " repo_name
repo_name=${repo_name:-$DEFAULT_REPO}
process_model "$repo_name"
read -p "Press Enter to continue..."
;;
2)
if [ -f "$LOG_FILE" ]; then
less "$LOG_FILE"
else
echo "No log file found"
read -p "Press Enter to continue..."
fi
;;
3)
df -h /
echo
echo "Disk usage: $(get_disk_usage)%"
if [ -f "download_commands_large.txt" ]; then
echo "Large files pending download:"
grep "safetensors" "download_commands_large.txt"
fi
read -p "Press Enter to continue..."
;;
4)
clean_downloads
read -p "Press Enter to continue..."
;;
5)
manual_upload
read -p "按回车键继续..."
;;
6)
check_baidu_status
read -p "按回车键继续..."
;;
7)
if [ -f "$SCRIPT_DIR/baidu_upload.log" ]; then
less "$SCRIPT_DIR/baidu_upload.log"
else
echo "未找到上传日志"
read -p "按回车键继续..."
fi
;;
8)
toggle_auto_upload
read -p "按回车键继续..."
;;
0)
log_message "Exiting script"
exit 0
;;
*)
echo "Invalid option"
read -p "Press Enter to continue..."
;;
esac
done3. 监控脚本:monitor_downloader.sh
#!/bin/bash
#
# HuggingFace Download Monitor
# Version: 1.1
# Created: 2025-01-30
# Updated: 2025-01-30 - Added improved speed tracking
#
# This script monitors HuggingFace model downloads and displays progress
# Requires: bc, awk, grep, stat
#
# Constants
TEMP_DIR="/tmp/download_monitor"
SPEED_FILE="${TEMP_DIR}/speeds.txt"
SIZE_FILE="${TEMP_DIR}/sizes.txt"
UPDATE_INTERVAL=2 # seconds
LOG_FILE="model_transfer.log"
ZERO_SPEED_THRESHOLD=4 # number of consecutive zero speed readings before showing 0
# Debug setting true / false
DEBUG=false
# ANSI color codes
BLUE='\033[0;34m'
GREEN='\033[0;32m'
YELLOW='\033[1;33m'
RED='\033[0;31m'
NC='\033[0m' # No Color
######################
# Utility Functions
######################
# Initialize temp files
init_temp_files() {
mkdir -p "$TEMP_DIR"
touch "$SPEED_FILE"
touch "$SIZE_FILE"
trap cleanup EXIT
}
# Cleanup on exit
cleanup() {
rm -rf "$TEMP_DIR"
}
# Print colored header
print_header() {
local title="$1"
echo -e "${BLUE}=== $title ===${NC}"
}
# Print section separator
print_separator() {
echo -e "${BLUE}----------------------------------------${NC}"
}
# Format size in human readable format
format_size() {
local size=$1
if [ "$size" -eq 0 ]; then
echo "0 MB"
return
fi
printf "%.2f MB" $(echo "$size/1048576" | bc -l)
}
######################
# File Information Functions
######################
# Get directory being monitored
get_download_dir() {
local dir=$(ps -ef | grep "huggingface-cli.*download" | grep -v grep | head -n 1 | grep -o "\-\-local-dir [^ ]*" | cut -d' ' -f2)
echo "$dir"
}
# Get current downloading file
get_downloading_filename() {
local filename
# First try to get complete safetensors filename
filename=$(ps -ef | grep "huggingface-cli.*download" | grep -v grep | grep -o "model-[0-9]\+-of-[0-9]\+\.safetensors" | head -1)
# If not found, try other patterns
if [ -z "$filename" ]; then
filename=$(ps -ef | grep "huggingface-cli.*download" | grep -v grep | grep -o "[^ ]*\.safetensors" | head -1)
fi
echo "$filename"
}
# Get total file size
get_total_size() {
local file_hash=$1
local current_file=$2
local log_file="model_transfer.log"
local size=0
local log_line=""
if $DEBUG; then
echo "Debug: Searching for file: $current_file (hash: $file_hash)" >&2
fi
# 首先尝试使用文件名搜索
if [ ! -z "$current_file" ]; then
while IFS= read -r line; do
if [[ "$line" == *"$current_file"* ]]; then
log_line="$line"
if $DEBUG; then
echo "Debug: Found log line by filename: $log_line" >&2
fi
break
fi
done < <(tac "$log_file" 2>/dev/null)
fi
# 如果通过文件名没找到,尝试使用hash搜索
if [ -z "$log_line" ]; then
while IFS= read -r line; do
if [[ "$line" == *"$file_hash"* ]]; then
log_line="$line"
if $DEBUG; then
echo "Debug: Found log line by hash: $log_line" >&2
fi
break
fi
done < <(tac "$log_file" 2>/dev/null)
fi
# 使用更灵活的模式匹配
if [[ $log_line =~ expected[[:space:]]*file[[:space:]]*size[[:space:]]*is:[[:space:]]*([0-9.]+)[[:space:]]*MB ]]; then
size=$(echo "${BASH_REMATCH[1]} * 1048576" | bc | cut -d'.' -f1)
elif [[ $log_line =~ ([0-9.]+)[[:space:]]*MB ]]; then
size=$(echo "${BASH_REMATCH[1]} * 1048576" | bc | cut -d'.' -f1)
elif [[ $log_line =~ resume[[:space:]]*from[[:space:]]*[0-9]+/([0-9]+) ]]; then
size="${BASH_REMATCH[1]}"
elif [[ $log_line =~ total[[:space:]]*size:[[:space:]]*([0-9]+) ]]; then
size="${BASH_REMATCH[1]}"
fi
# 如果在日志中没找到大小,检查是否是分片文件
if [ "$size" -eq 0 ] && [[ "$current_file" =~ model-([0-9]+)-of-([0-9]+)\.safetensors ]]; then
local base_dir=$(dirname "$current_file")
local first_part="${base_dir}/model-00001-of-${BASH_REMATCH[2]}.safetensors"
if $DEBUG; then
echo "Debug: Checking reference file: $first_part" >&2
fi
if [ -f "$first_part" ]; then
local ref_size=$(stat -c %s "$first_part" 2>/dev/null)
if [ ! -z "$ref_size" ] && [ "$ref_size" -gt 0 ]; then
size="$ref_size"
if $DEBUG; then
echo "Debug: Using reference file size: $size bytes" >&2
fi
fi
fi
fi
# 确保返回有效整数
if [[ $size =~ ^[0-9]+$ ]]; then
echo "$size"
else
echo "0"
fi
}
######################
# Speed Tracking Functions
######################
# Get stored size from temp file
get_stored_size() {
local file_hash=$1
if [ ! -f "$SIZE_FILE" ]; then
echo "0"
return
fi
local size
size=$(grep "^${file_hash}:" "$SIZE_FILE" | cut -d: -f2)
if [ -z "$size" ] || [[ ! "$size" =~ ^[0-9]+$ ]]; then
echo "0"
else
echo "$size"
fi
}
# Update size in temp file
update_stored_size() {
local file_hash=$1
local size=$2
local tmp_file="${SIZE_FILE}.tmp"
if grep -q "^${file_hash}:" "$SIZE_FILE"; then
sed "s|^${file_hash}:.*|${file_hash}:${size}|" "$SIZE_FILE" > "$tmp_file"
mv "$tmp_file" "$SIZE_FILE"
else
echo "${file_hash}:${size}" >> "$SIZE_FILE"
fi
}
# Get stored speed info
get_stored_speed_info() {
local file_hash=$1
local info
# 检查文件是否存在
if [ ! -f "$SPEED_FILE" ]; then
echo "0 0 0" # speed zero_count had_speed
return
fi
# 获取匹配行
info=$(grep "^${file_hash}:" "$SPEED_FILE" | cut -d: -f2)
if [ -z "$info" ]; then
echo "0 0 0"
return
fi
# 处理不同格式
if [[ "$info" != *" "* ]]; then
# 单个数字,添加计数器和had_speed标记
echo "$info 0 0"
elif [[ "$info" =~ ^([0-9]+)[[:space:]]+([0-9]+)$ ]]; then
# 旧格式:只有speed和zero_count,添加had_speed
echo "$info 0"
else
# 新格式:已包含所有三个值
echo "$info"
fi
}
# Update stored speed info
update_stored_speed_info() {
local file_hash=$1
local speed=$2
local zero_count=$3
local had_speed=$4
local tmp_file="${SPEED_FILE}.tmp"
if grep -q "^${file_hash}:" "$SPEED_FILE"; then
sed "s|^${file_hash}:.*|${file_hash}:${speed} ${zero_count} ${had_speed}|" "$SPEED_FILE" > "$tmp_file"
mv "$tmp_file" "$SPEED_FILE"
else
echo "${file_hash}:${speed} ${zero_count} ${had_speed}" >> "$SPEED_FILE"
fi
}
# Calculate download speed
calculate_speed() {
local current_size=$1
local file_hash=$2
if $DEBUG; then
echo "Debug: Starting speed calculation for $file_hash" >&2
fi
# 验证当前大小
if [[ ! "$current_size" =~ ^[0-9]+$ ]]; then
if $DEBUG; then
echo "Debug: Invalid current_size: $current_size" >&2
fi
echo "0"
return
fi
# 获取上次大小
local last_size=$(get_stored_size "$file_hash")
if $DEBUG; then
echo "Debug: calculate_speed - current_size=$current_size, last_size=$last_size" >&2
fi
# 计算大小差异
local size_diff=$((current_size - last_size))
if $DEBUG; then
echo "Debug: size_diff=$size_diff" >&2
fi
# 对第一次测量的特殊处理
if [ "$last_size" -eq 0 ] && [ "$current_size" -gt 0 ]; then
if $DEBUG; then
echo "Debug: First measurement, storing initial size" >&2
fi
update_stored_size "$file_hash" "$current_size"
echo "0"
return
fi
# 计算速度
if [ $size_diff -gt 0 ]; then
local speed_kb=$(echo "scale=0; ($size_diff/1024/$UPDATE_INTERVAL + 0.5)/1" | bc)
if $DEBUG; then
echo "Debug: Calculated speed=$speed_kb KB/s" >&2
fi
update_stored_speed_info "$file_hash" "$speed_kb" "0" "1"
update_stored_size "$file_hash" "$current_size"
echo "$speed_kb"
else
# 获取之前的速度信息
local speed_info=($(get_stored_speed_info "$file_hash"))
local last_speed=${speed_info[0]}
local zero_count=${speed_info[1]}
local had_speed=${speed_info[2]}
if [ "$had_speed" -eq 1 ]; then
zero_count=$((zero_count + 1))
if [ $zero_count -ge $ZERO_SPEED_THRESHOLD ]; then
update_stored_speed_info "$file_hash" "0" "$zero_count" "$had_speed"
echo "0"
else
update_stored_speed_info "$file_hash" "$last_speed" "$zero_count" "$had_speed"
echo "$last_speed"
fi
else
update_stored_speed_info "$file_hash" "0" "0" "0"
echo "0"
fi
update_stored_size "$file_hash" "$current_size"
fi
}
######################
# Display Functions
######################
# Format speed display
format_speed() {
local speed=$1
# 确保speed是数字
if [[ ! "$speed" =~ ^[0-9]+$ ]]; then
if $DEBUG; then
echo "Debug: Invalid speed value: $speed" >&2
fi
speed=0
fi
# 速度显示
if [ "$speed" -gt 0 ]; then
echo -e "${GREEN}${speed} KB/s${NC}"
else
echo -e "${RED}0 KB/s${NC}"
fi
}
# Format status with color
format_status() {
local status=$1
local current_size=$2
local total_size=$3
# Ensure valid integers
current_size=${current_size:-0}
total_size=${total_size:-0}
if [ "$total_size" -gt "0" ] 2>/dev/null && [ "$current_size" -ge "$total_size" ] 2>/dev/null; then
echo -e "${BLUE}下载完成${NC}"
elif [ "$status" = "活跃下载中" ]; then
echo -e "${GREEN}$status${NC}"
elif [ "$status" = "已暂停" ]; then
echo -e "${YELLOW}$status${NC}"
else
echo -e "$status"
fi
}
# Check download status
check_download_status() {
local file_hash=$1
local current_size=$2
local speed=$3
local total_size=$4
# Ensure valid integers
current_size=${current_size:-0}
speed=${speed:-0}
total_size=${total_size:-0}
if [ "$speed" -gt "0" ] 2>/dev/null; then
echo "活跃下载中"
elif [ "$total_size" -gt "0" ] 2>/dev/null && [ "$current_size" -ge "$total_size" ] 2>/dev/null; then
echo "下载完成"
else
echo "已暂停"
fi
}
# Format progress percentage
format_progress() {
local current_size=$1
local total_size=$2
# Ensure valid integers
current_size=${current_size:-0}
total_size=${total_size:-0}
# Validate input
if [ "$total_size" -eq 0 ] 2>/dev/null; then
echo "等待大小信息..."
return
fi
# Use awk for float calculation
local progress
progress=$(awk "BEGIN {printf \"%.2f\", ($current_size * 100) / $total_size}")
if [ $? -eq 0 ] && [ -n "$progress" ]; then
# Ensure progress doesn't exceed 100%
if (( $(echo "$progress > 100" | bc -l) )); then
echo "100.00%"
else
echo "$progress%"
fi
else
echo "计算中..."
fi
}
get_disk_usage() {
df / | awk 'NR==2 {print $5}' | sed 's/%//'
}
get_disk_details() {
local device=$1
local info=$(df -h | awk -v dev="$device" '$1==dev {print $2":"$3":"$4":"$5}')
if [ -z "$info" ]; then
echo "N/A:N/A:N/A:N/A"
return
fi
echo "$info"
}
######################
# Main Functions
######################
# Monitor downloads
monitor_downloads() {
local DOWNLOAD_DIR=$(get_download_dir)
if [ -z "$DOWNLOAD_DIR" ]; then
echo "未检测到下载任务"
return 1
fi
local CACHE_DIR="$DOWNLOAD_DIR/.cache/huggingface/download"
print_header "HuggingFace 下载监控"
# 显示磁盘使用情况
local root_disk_info=($(get_disk_details "/" | tr ':' ' '))
local vda3_disk_info=($(get_disk_details "/dev/vda3" | tr ':' ' '))
echo -e "${BLUE}系统磁盘使用情况${NC}"
echo -e "/ 分区:"
echo -e " 总大小: ${GREEN}${root_disk_info[0]}${NC}"
echo -e " 已使用: ${YELLOW}${root_disk_info[1]}${NC}"
echo -e " 可用: ${GREEN}${root_disk_info[2]}${NC}"
echo -e " 使用率: ${root_disk_info[3]}"
echo -e "\n/dev/vda3 分区:"
echo -e " 总大小: ${GREEN}${vda3_disk_info[0]}${NC}"
echo -e " 已使用: ${YELLOW}${vda3_disk_info[1]}${NC}"
echo -e " 可用: ${GREEN}${vda3_disk_info[2]}${NC}"
echo -e " 使用率: ${vda3_disk_info[3]}"
echo "监控目录: $DOWNLOAD_DIR"
print_separator
if [ ! -d "$CACHE_DIR" ]; then
echo "缓存目录不存在"
return 1
fi
local current_file=$(get_downloading_filename)
if [ ! -z "$current_file" ]; then
echo -e "正在下载: ${GREEN}$current_file${NC}"
print_separator
fi
# Monitor incomplete downloads
while read -r incomplete_file; do
[ -f "$incomplete_file" ] || continue
local file_size=$(stat -c %s "$incomplete_file" 2>/dev/null || echo "0")
local file_hash=$(basename "$incomplete_file" | cut -d'.' -f1)
local total_size=$(get_total_size "$file_hash" "$current_file")
local speed_kb=$(calculate_speed "$file_size" "$file_hash")
local human_size=$(format_size "$file_size")
local human_total_size=$(format_size "$total_size")
local status=$(check_download_status "$file_hash" "$file_size" "$speed_kb" "$total_size")
local progress=$(format_progress "$file_size" "$total_size")
echo "临时文件: $(basename "$incomplete_file")"
echo "当前大小: $human_size"
if $DEBUG; then
echo "Debug: Processing speed display for $file_hash" >&2
echo "Debug: Current file size: $file_size" >&2
fi
echo -n "下载速度: "
format_speed "$speed_kb" "$file_hash"
echo -e "状态: $(format_status "$status" "$file_size" "$total_size")"
echo "下载进度: $progress"
print_separator
done < <(find "$CACHE_DIR" -name "*.incomplete" 2>/dev/null)
# Show completed files
echo "已完成的文件:"
while read -r file; do
[ -f "$file" ] || continue
local size=$(stat -c %s "$file")
echo "$(basename "$file"): $(format_size $size)"
done < <(find "$DOWNLOAD_DIR" -maxdepth 1 -name "*.safetensors" 2>/dev/null)
print_separator
}
######################
# Main Program
######################
# Initialize temporary files
init_temp_files
# Main monitoring loop
while true; do
clear
date "+%Y-%m-%d %H:%M:%S"
echo
monitor_downloads
sleep $UPDATE_INTERVAL
done4. 上传 Pan 脚本:baidu_upload.sh
#!/bin/bash
# Baidu Pan Upload Script
# Version 0.12
# Created by Dave on 31Jan2025
# History:
# 0.1-0.11 Previous development stages
# 0.12 Simplified upload process based on BaiduPCS-Go documentation
# Color codes
RED='\033[0;31m'
GREEN='\033[0;32m'
YELLOW='\033[1;33m'
BLUE='\033[0;34m'
NC='\033[0m' # No Color
# Configuration
SCRIPT_DIR="$( cd "$( dirname "${BASH_SOURCE[0]}" )" && pwd )"
LOG_FILE="$SCRIPT_DIR/baidu_upload.log"
CONFIG_FILE="$SCRIPT_DIR/.upload_config"
# Default settings
MAX_RETRIES=3
RETRY_DELAY=30
UPLOAD_TIMEOUT=3600 # 1 hour timeout for uploads
AUTO_RETRY=true
UPLOAD_SPEED_LIMIT="" # Empty means no limit
# Logging function
log_message() {
local level="$1"
local message="$2"
local timestamp=$(date '+%Y-%m-%d %H:%M:%S')
# Log to file
echo "[$timestamp] [$level] $message" >> "$LOG_FILE"
# Colorized console output based on log level
case "$level" in
"INFO")
echo -e "${BLUE}[INFO]${NC} $message"
;;
"WARNING")
echo -e "${YELLOW}[WARNING]${NC} $message"
;;
"ERROR")
echo -e "${RED}[ERROR]${NC} $message"
;;
"SUCCESS")
echo -e "${GREEN}[SUCCESS]${NC} $message"
;;
*)
echo "$message"
;;
esac
}
# Pause function
pause() {
echo
read -p "按回车键继续..." key
}
# Load configuration
load_config() {
# Ensure config file exists
touch "$CONFIG_FILE"
# Source the config file
source "$CONFIG_FILE"
}
# Save configuration
save_config() {
# Ensure directory exists
mkdir -p "$(dirname "$CONFIG_FILE")"
# Write configuration
cat > "$CONFIG_FILE" << EOF
UPLOAD_SPEED_LIMIT="$UPLOAD_SPEED_LIMIT"
AUTO_RETRY=$AUTO_RETRY
EOF
}
# Check if a path should be skipped
should_skip_path() {
local path="$1"
local filename=$(basename "$path")
# Skip hidden files and directories
if [[ "$filename" == .* ]]; then
log_message "WARNING" "跳过隐藏项目: $path"
return 0
fi
# Skip .cache directories and their contents
if [[ "$path" == *"/.cache/"* ]]; then
log_message "WARNING" "跳过缓存目录: $path"
return 0
fi
return 1
}
# Verify file upload
verify_upload() {
local local_file="$1"
local remote_path="$2"
local max_verifications=3
local retry_count=0
while [ $retry_count -lt $max_verifications ]; do
log_message "INFO" "Verifying upload: $local_file (attempt $((retry_count + 1)))"
# Get local file size using stat with cross-platform compatibility
local local_size=$(stat -c %s "$local_file" 2>/dev/null || stat -f %z "$local_file" 2>/dev/null)
# Get remote file info
local remote_info=$(BaiduPCS-Go meta "$remote_path" 2>/dev/null)
local remote_size=$(echo "$remote_info" | grep -E "size:|大小:" | awk '{print $2}')
# Trim any potential whitespace
local_size=$(echo "$local_size" | tr -d ' ')
remote_size=$(echo "$remote_size" | tr -d ' ')
if [ "$local_size" = "$remote_size" ]; then
log_message "SUCCESS" "Verification successful - sizes match: $local_size bytes"
return 0
else
log_message "WARNING" "Size mismatch - Local: $local_size, Remote: $remote_size"
retry_count=$((retry_count + 1))
if [ $retry_count -lt $max_verifications ]; then
log_message "INFO" "Retrying verification in 5 seconds..."
sleep 5
fi
fi
done
log_message "ERROR" "Upload verification failed after $max_verifications attempts"
return 1
}
# Upload single file with retry
upload_single_file() {
local source="$1"
local target="$2"
local attempts=0
# Skip hidden or cache files
if should_skip_path "$source"; then
return 0
fi
# Validate input
if [ ! -f "$source" ]; then
log_message "ERROR" "源文件不存在: $source"
return 1
fi
while [ $attempts -lt $MAX_RETRIES ]; do
attempts=$((attempts + 1))
log_message "INFO" "Upload attempt $attempts of $MAX_RETRIES: $source -> $target"
# Prepare upload command
local upload_cmd=(
#"timeout" "$UPLOAD_TIMEOUT"
"BaiduPCS-Go" "upload"
#"--norapid" # Disable rapid upload for reliability
#"--retry" "3"
)
# Add speed limit if configured
if [ -n "$UPLOAD_SPEED_LIMIT" ]; then
upload_cmd+=("--limit" "$UPLOAD_SPEED_LIMIT")
fi
# Add source and target
upload_cmd+=("$source" "$target")
# Execute upload with progress monitoring
if "${upload_cmd[@]}" 2>&1 | while read -r line; do
log_message "INFO" "Progress: $line"
done; then
# Verify upload
local remote_file="$target/$(basename "$source")"
if verify_upload "$source" "$remote_file"; then
log_message "SUCCESS" "Upload successful: $source"
return 0
else
log_message "WARNING" "Upload verification failed"
fi
else
local exit_code=$?
log_message "ERROR" "Upload failed with exit code $exit_code"
fi
# If not the last attempt, wait before retrying
if [ $attempts -lt $MAX_RETRIES ]; then
log_message "INFO" "Retrying in $RETRY_DELAY seconds..."
sleep $RETRY_DELAY
fi
done
log_message "ERROR" "Failed to upload after $MAX_RETRIES attempts: $source"
return 1
}
# Upload directory contents recursively
upload_directory_contents() {
local source_dir="$1"
local target_dir="$2"
# Validate source directory
if [ ! -d "$source_dir" ]; then
log_message "ERROR" "源目录不存在: $source_dir"
return 1
fi
# Ensure target directory exists
BaiduPCS-Go mkdir "$target_dir" 2>/dev/null
# Find and upload all non-hidden files and directories
find "$source_dir" -type f | while read -r file; do
# Skip hidden files and .cache contents
if should_skip_path "$file"; then
continue
fi
# Determine relative path for upload
relative_path="${file#$source_dir/}"
target_path="$target_dir/$relative_path"
# Ensure target directory exists
target_file_dir=$(dirname "$target_path")
BaiduPCS-Go mkdir "$target_file_dir" 2>/dev/null
# Upload file
upload_single_file "$file" "$target_file_dir"
done
}
# Configure upload settings
configure_upload() {
while true; do
clear
echo "=== 百度网盘上传配置 ==="
echo "1. 设置上传速度限制"
echo "2. 配置自动重试 (当前: $AUTO_RETRY)"
echo "0. 返回"
echo "======================="
read -p "请选择操作 [0-2]: " choice
case $choice in
1)
read -p "输入上传速度限制 (例如: 1024K, 1M, 留空表示无限制): " speed_limit
UPLOAD_SPEED_LIMIT="$speed_limit"
save_config
log_message "INFO" "上传速度限制设置为: ${UPLOAD_SPEED_LIMIT:-无限制}"
pause
;;
2)
if [ "$AUTO_RETRY" = true ]; then
AUTO_RETRY=false
log_message "INFO" "已关闭自动重试"
else
AUTO_RETRY=true
log_message "INFO" "已启用自动重试"
fi
save_config
pause
;;
0)
return
;;
*)
log_message "ERROR" "无效的选择"
pause
;;
esac
done
}
# Main upload function
main_upload() {
# Validate arguments
if [ "$#" -lt 2 ]; then
log_message "ERROR" "使用方法: $0 <源文件/目录> <目标目录>"
exit 1
fi
local SOURCE="$1"
local TARGET="$2"
# Load configuration
load_config
# Validate source path
if [ ! -e "$SOURCE" ]; then
log_message "ERROR" "源路径不存在: $SOURCE"
return 1
fi
# Check if source is a hidden directory
if should_skip_path "$SOURCE"; then
return 0
fi
log_message "INFO" "开始上传过程"
log_message "INFO" "源: $SOURCE"
log_message "INFO" "目标目录: $TARGET"
# Create target directory if it doesn't exist
BaiduPCS-Go mkdir "$TARGET" 2>/dev/null
# Perform upload based on source type
if [ -d "$SOURCE" ]; then
upload_directory_contents "$SOURCE" "$TARGET"
else
upload_single_file "$SOURCE" "$TARGET"
fi
}
# Main script entry point
if [[ "${BASH_SOURCE[0]}" == "${0}" ]]; then
# Script is being run directly
case "$1" in
--config)
configure_upload
;;
*)
# Perform upload
main_upload "$@"
;;
esac
fi总结:
能用,还有些错误。
运行时,不要关闭终端。
没挣过钱,就限流了。


















 1207
1207

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









