






前言
ChatGLM 和 LLaMA 中使用的旋转位置编码(RoPE),原版论文中大段大段的公式推导实在是太绕了,看了脑壳疼。这篇文章我用能理解能记住的方式梳理一下。
我个人觉得关于 RoPE 的核心问题有两个:
-
首先,为什么 LLM 普遍采用这种编码方式而不是其他的
-
其次,工程上的实现方式和论文公式是否严格一致。
如果静下心来读一读,这两个问题都能解答。
1、溯源“位置编码”
(1)什么是位置编码(Position Encoding)

(2)位置编码(Position Encoding)的优势
由于位置向量是通过三角函数直接计算得到,Position Encoding 相比于 Position Embedding,不需要额外的模型参数,而且具备良好的长度外推性。
想要什么长度位置,就代入公式就能算出来,帮助 LLM 们摆脱了序列长度限制。继承自这一派的位置编码方法,都有这些特点(包括 RoPE)。
(3)绝对位置编码 -> 相对位置编码

2、旋转位置编码
(1)相对位置编码的一般原理

(2)旋转位置编码(RoPE)的首要特征

(3)具体计算流程
原版论文中有大段的公式推导,并且套了一个“复变函数”的壳,特别费脑子。这里直接介绍一下实操做法,其实还是挺容易懂的。
a. 语义向量复数化

维度可以进行任意位置的两两组合时,不需要严格执行奇偶交替。简便做法是取前半部分全部为实部分,后半部分全部为虚部。
b. 计算各维度的基准旋角
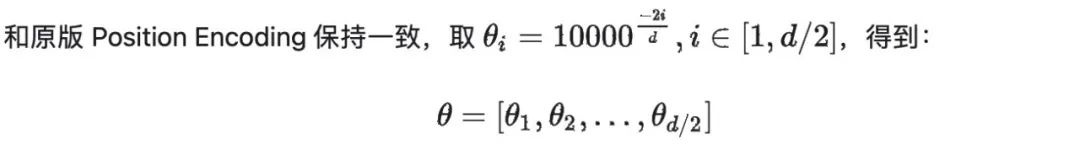
c. 对语义向量根据绝对位置进行旋转

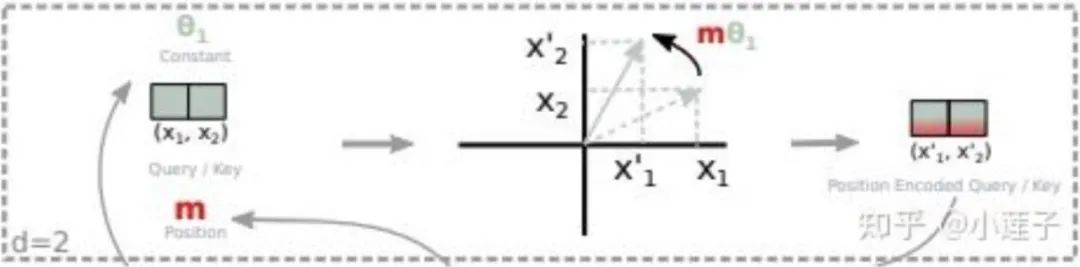
这就是“旋转位置编码”这个名字的由来。
d. 复用原始 self-attention 流程

3、RoPE的快速计算方法
(1) "旋转"的矩阵解法

也可以按论文中那样,写成矩阵乘法的形式:
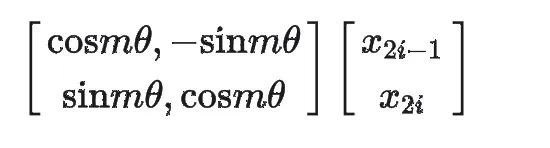
这样一来,“旋转”的规程就变为,先构造旋角矩阵,再和复数矩阵相乘。
(2)HuggingFace的LLama实现
在实际的代码中,语义向量是 [batch_size, seq_length, head_num, head_dim] 四维的,我们只关注最后一维即可。
def rotate_half(x):
x1 = x[..., : x.shape[-1] // 2] # 实部, 对应x_2i-1
x2 = x[..., x.shape[-1] // 2 :] # 虚部, 对应x_2i
return torch.cat((-x2, x1), dim=-1)
首先,使用 rotate_half() 进行语义向量复数化。将前半部分划为实部,后办部分划为虚部。
这里的负号,对应和角公式中的负号。计算旋角 mΦ 的过程此处省略。
def apply_rotary_pos_emb(q, k, cos, sin, position_ids=None, unsqueeze_dim=1):
cos = cos.unsqueeze(unsqueeze_dim)
sin = sin.unsqueeze(unsqueeze_dim)
q_embed = (q * cos) + (rotate_half(q) * sin)
k_embed = (k * cos) + (rotate_half(k) * sin)
return q_embed, k_embed
将 rotate_half() 代入到 apply_rotary_pos_emb(),以 q=【x1,x2】为例:
q_embed = [x1, x2] * cos + [-x2, x1] * sin = [x1 * cos - x2 * sin, x2 * cos + x1 * sin]
和上面的推导完全一致。self-attention 的流程无需改动,用 q_embed 替换 q,用 k_embed 替换 k,即可。
最后
为了助力朋友们跳槽面试、升职加薪、职业困境,提高自己的技术,本文给大家整了一套涵盖AI大模型所有技术栈的快速学习方法和笔记。目前已经收到了七八个网友的反馈,说是面试问到了很多这里面的知识点。
由于文章篇幅有限,不能将全部的面试题+答案解析展示出来,有需要完整面试题资料的朋友,可以扫描下方二维码免费领取哦!!! 👇👇👇👇

面试题展示
1、请解释一下BERT模型的原理和应用场景。
答案:BERT(Bidirectional Encoder Representations from Transformers)是一种预训练的语言模型,通过双向Transformer编码器来学习文本的表示。它在自然语言处理任务中取得了很好的效果,如文本分类、命名实体识别等。
2、什么是序列到序列模型(Seq2Seq),并举例说明其在自然语言处理中的应用。
答案:Seq2Seq模型是一种将一个序列映射到另一个序列的模型,常用于机器翻译、对话生成等任务。例如,将英文句子翻译成法文句子。
3、请解释一下Transformer模型的原理和优势。
答案:Transformer是一种基于自注意力机制的模型,用于处理序列数据。它的优势在于能够并行计算,减少了训练时间,并且在很多自然语言处理任务中表现出色。
4、什么是注意力机制(Attention Mechanism),并举例说明其在深度学习中的应用。
答案:注意力机制是一种机制,用于给予模型对不同部分输入的不同权重。在深度学习中,注意力机制常用于提升模型在处理长序列数据时的性能,如机器翻译、文本摘要等任务。
5、请解释一下卷积神经网络(CNN)在计算机视觉中的应用,并说明其优势。
答案:CNN是一种专门用于处理图像数据的神经网络结构,通过卷积层和池化层提取图像特征。它在计算机视觉任务中广泛应用,如图像分类、目标检测等,并且具有参数共享和平移不变性等优势。
6、请解释一下生成对抗网络(GAN)的原理和应用。
答案:GAN是一种由生成器和判别器组成的对抗性网络结构,用于生成逼真的数据样本。它在图像生成、图像修复等任务中取得了很好的效果。
7、请解释一下强化学习(Reinforcement Learning)的原理和应用。
答案:强化学习是一种通过与环境交互学习最优策略的机器学习方法。它在游戏领域、机器人控制等领域有广泛的应用。
8、请解释一下自监督学习(Self-Supervised Learning)的原理和优势。
答案:自监督学习是一种无需人工标注标签的学习方法,通过模型自动生成标签进行训练。它在数据标注困难的情况下有很大的优势。
9、解释一下迁移学习(Transfer Learning)的原理和应用。
答案:迁移学习是一种将在一个任务上学到的知识迁移到另一个任务上的学习方法。它在数据稀缺或新任务数据量较小时有很好的效果。
10、请解释一下模型蒸馏(Model Distillation)的原理和应用。
答案:模型蒸馏是一种通过训练一个小模型来近似一个大模型的方法。它可以减少模型的计算和存储开销,并在移动端部署时有很大的优势。
11、请解释一下LSTM(Long Short-Term Memory)模型的原理和应用场景。
答案:LSTM是一种特殊的循环神经网络结构,用于处理序列数据。它通过门控单元来学习长期依赖关系,常用于语言建模、时间序列预测等任务。
12、请解释一下BERT模型的原理和应用场景。
答案:BERT(Bidirectional Encoder Representations from Transformers)是一种预训练的语言模型,通过双向Transformer编码器来学习文本的表示。它在自然语言处理任务中取得了很好的效果,如文本分类、命名实体识别等。
13、什么是注意力机制(Attention Mechanism),并举例说明其在深度学习中的应用。
答案:注意力机制是一种机制,用于给予模型对不同部分输入的不同权重。在深度学习中,注意力机制常用于提升模型在处理长序列数据时的性能,如机器翻译、文本摘要等任务。
14、请解释一下生成对抗网络(GAN)的原理和应用。
答案:GAN是一种由生成器和判别器组成的对抗性网络结构,用于生成逼真的数据样本。它在图像生成、图像修复等任务中取得了很好的效果。
15、请解释一下卷积神经网络(CNN)在计算机视觉中的应用,并说明其优势。
答案:CNN是一种专门用于处理图像数据的神经网络结构,通过卷积层和池化层提取图像特征。它在计算机视觉任务中广泛应用,如图像分类、目标检测等,并且具有参数共享和平移不变性等优势。
16、请解释一下强化学习(Reinforcement Learning)的原理和应用。
答案:强化学习是一种通过与环境交互学习最优策略的机器学习方法。它在游戏领域、机器人控制等领域有广泛的应用。
17、请解释一下自监督学习(Self-Supervised Learning)的原理和优势。
答案:自监督学习是一种无需人工标注标签的学习方法,通过模型自动生成标签进行训练。它在数据标注困难的情况下有很大的优势。
18、请解释一下迁移学习(Transfer Learning)的原理和应用。
答案:迁移学习是一种将在一个任务上学到的知识迁移到另一个任务上的学习方法。它在数据稀缺或新任务数据量较小时有很好的效果。
19、请解释一下模型蒸馏(Model Distillation)的原理和应用。
答案:模型蒸馏是一种通过训练一个小模型来近似一个大模型的方法。它可以减少模型的计算和存储开销,并在移动端部署时有很大的优势。
20、请解释一下BERT中的Masked Language Model(MLM)任务及其作用。
答案:MLM是BERT预训练任务之一,通过在输入文本中随机mask掉一部分词汇,让模型预测这些被mask掉的词汇。
由于文章篇幅有限,不能将全部的面试题+答案解析展示出来,有需要完整面试题资料的朋友,可以扫描下方二维码免费领取哦!!! 👇👇👇👇




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









