




距离上次年终盘点已经过去半年,随着年初 DeepSeek 带来的浪潮逐渐退去,似乎 AI 再一次进入了瓶颈期,对于 RAG 来说,也有类似的现象,从近半年来的学术论文列表相关主题也可以感受出来,虽然依旧是热门选题,但新颖的工作乏善可陈,RAGFlow 在近几个月的迭代,也以小步快走为主,没有发布特别显著的特性。这是意味着厚积薄发,还是从此进入平稳增长? 我们有必要在此时做个中期盘点。
我们曾反复提及,RAG 自出生以来始终伴随着争议性的话题,例如 2023 微调之争,2024 长上下文之争等等。进入 2025 之后,RAG 的话题似乎不那么多了,取之而来的是 Agent ,自然也就出现了有 Agent 不需要 RAG 的言论。作为从业者,我们自然知道这样的言论更多是市场吸睛的策略,也充分理解这样言论的出发点。但是站在使用者或者非从业人员的视角来看,确实有被混淆的效果,例如宁可把 RAG 也穿上 Agentic 的外套成为 Agentic RAG ,夸张的市场咨询机构甚至给出的 Agentic RAG 的市场规模是 RAG 的若干倍的预测【参考 1】。因此,这也是本期盘点的动机之一。事实上,全网最早能搜到 Agentic RAG 的时间点,也刚好是 RAGFlow 在一年前推出“Agent”的前后脚,这也使得 RAGFlow 时常被作为 Agentic RAG 的代表被放到各类学术论文里做对比。因此本文盘点的开始,就从 RAG 和 Agent 说起。在展开之前,我们先定义 Agent :它既包含 Workflow,也包含智能体。在截至到当前版本(v0.19)的 RAGFlow 中,虽然 Agent 字样已经存在了一年,但它仍然只停留在 Workflow 的层面,还没有真正的全面引入 Agent 机制。而在 RAGFlow 中,我们不会将两者割裂,这跟 24 年底 Anthropic 的知名博客文章【参考 2】提到将两者分开的提法不同,我们始终坚持两者必须合二为一的设计策略。
“反思驱动:Agent 赋能 RAG 推理的关键”
Agent 通过人工或模型驱动的反思循环,解决 RAG 推理难题,实现智能跃升,二者密不可分
自 2024 年底至 2025 年初的系列活动中,我们曾经多次给出了 2025 的 RAG 主打关键词:推理、记忆、多模态。其中,前两者跟 Agent 都有着密切的联系,在年初我们的第一篇文章中,就对推理进行了实现路径上的较全面总结。在近期的一篇综述中【参考 3】,进一步将推理和 RAG 进行了全面的总结和整理,我们做了一些删减和改写后如下图所示:
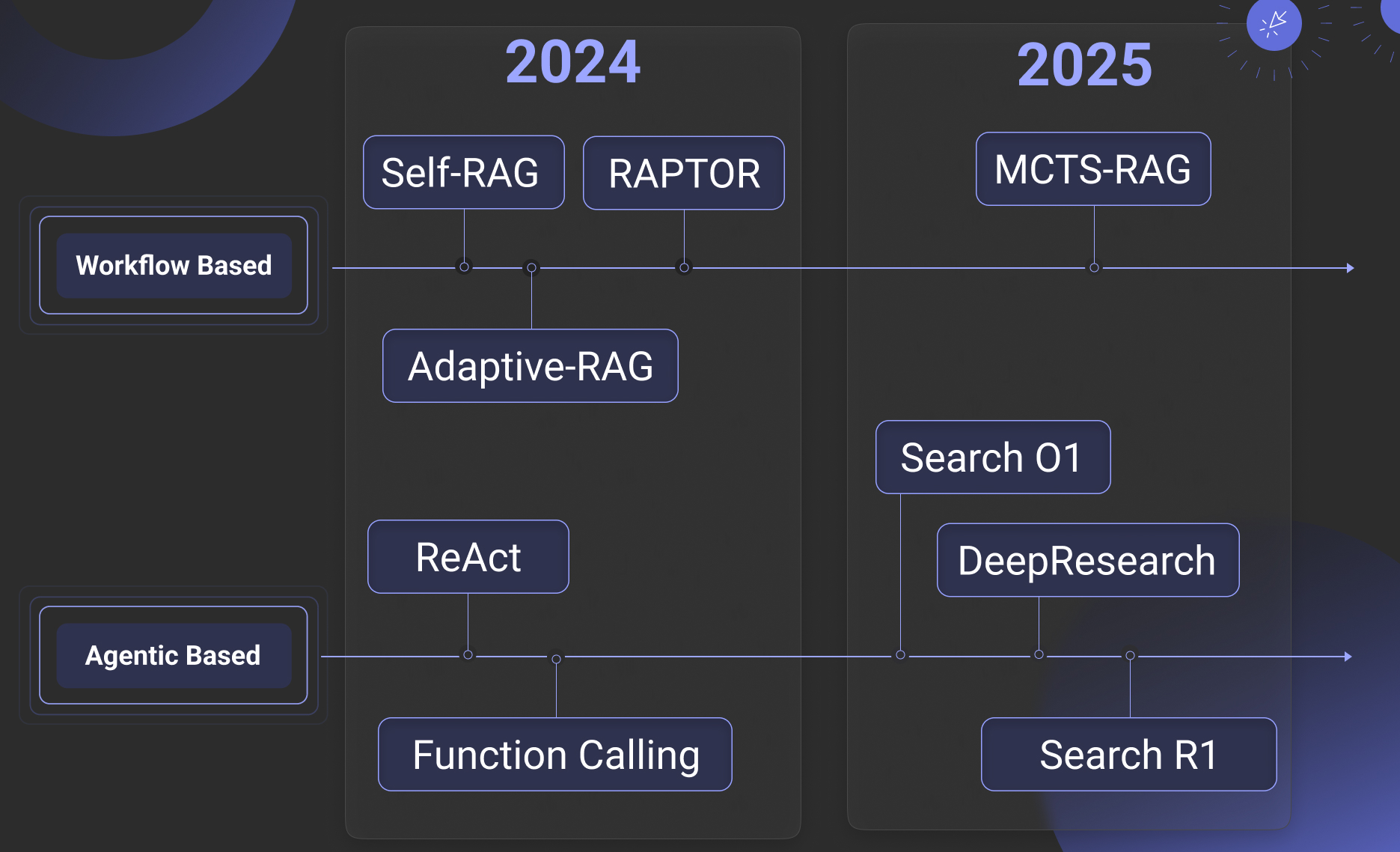
可以看出来,作者把去年的系列工作也都纳入到了推理框架之下,其中 RAGFlow 在一年前实现的 Self-RAG,RAPTOR,Adaptive-RAG 等,这些在原文中被归纳为“预定义式的”推理,在我们看来,这也可以用所谓 Workflow Based 来定义分类,因此,去年我们公号提及的 Agentic RAG,实际上是一种借助于 Workflow ,由人工来定义 RAG 和 Agent 交互的方式,通过循环,路由等确定性算子,实现 Agent 的关键环节之一 —— 反思,解决对话过程中意图不明、长上下文等推理过程中遇到的难题。而 Agentic Based 方案,就是由模型来决定如何反思,这包括以 Search O1,各类开源 DeepResearch 实现,以及 Search R1 为代表的各类方案。这里边又进一步分为两类:一类是依靠 Prompt (也就是 LLM 自身)来进行反思,就是箭头上边的这些工作;另一类则是依赖训练(通常是强化学习),针对特定领域学习到可以生成适合的思维链和反思终止条件,但并非 Search R1 这类工作天然就更加高大上,它们的本质是让通用 LLM 在面对特定数据时给出的思维链和反思终止条件更加合适, 但同样依赖于以 Prompt 为基座的 Agent 框架来正常工作。
“记忆之基:RAG 支撑 Agent 的记忆体系”
RAG 构建 Agent 长期记忆库,通过索引/遗忘/巩固实现任务状态跟踪与上下文加速,与短期记忆协同形成完整架构
不管是用哪种方式实现的推理,可以看出,在 RAG 层面之外 Agent 所能做的工作很少,但是为何就可以让普通的 RAG 更加智能而甚至无需专用推理大模型呢?这其实就是 Agent 自身的价值:如果将 LLM 模拟为人,那么 Agent 是用来驱动人更多在观察中反复总结和思考的工具,而非只依靠缺乏观察的单轮思考(俗称“拍脑袋”)。从这个角度来看,RAG 和 Agent,或者说 Agentic RAG 的关系过于密切,乃至于 RAG 框架如 RAGFlow,推出完整的 Agent(不止是 Workflow)是顺其自然的事情,这也是下个版本 RAGFlow 的主要功能。
2025 年时常被称为 Agent 元年,解锁了众多眼花缭乱的场景,但 Agent 框架本身相比于 2024 年并没发生显著的变化。Agent 的火热,主要是由于 LLM 的 In Context Learning 能力的增强,其次在于 Tools 生态的完善,然后在于类似多 Agent 这样的噱头解锁新场景。故而除了 LLM 本身的进化以外,Agent 的核心所能体现出的技术层面的工作非常有限,而为数不多者,就包含所谓的 “Memory 记忆”。 如果说 2024 年 OpenAI 收购 Rockset 是为了更好的 RAG,2025 年投资 Supabase 则是为了给 Agent 提供更便捷的 Tools 和部分记忆管理。站在 Agent 的视角,RAG 和诸多 Data Infra 的地位似乎等同——它们都只是 Agent 在 Context 中所需要调用的若干 Tools。然而,由于 RAG 和 Memory 天然之间存在着紧密关系,使得 RAG 和其他的 Data Infra 又有那么一些不同。
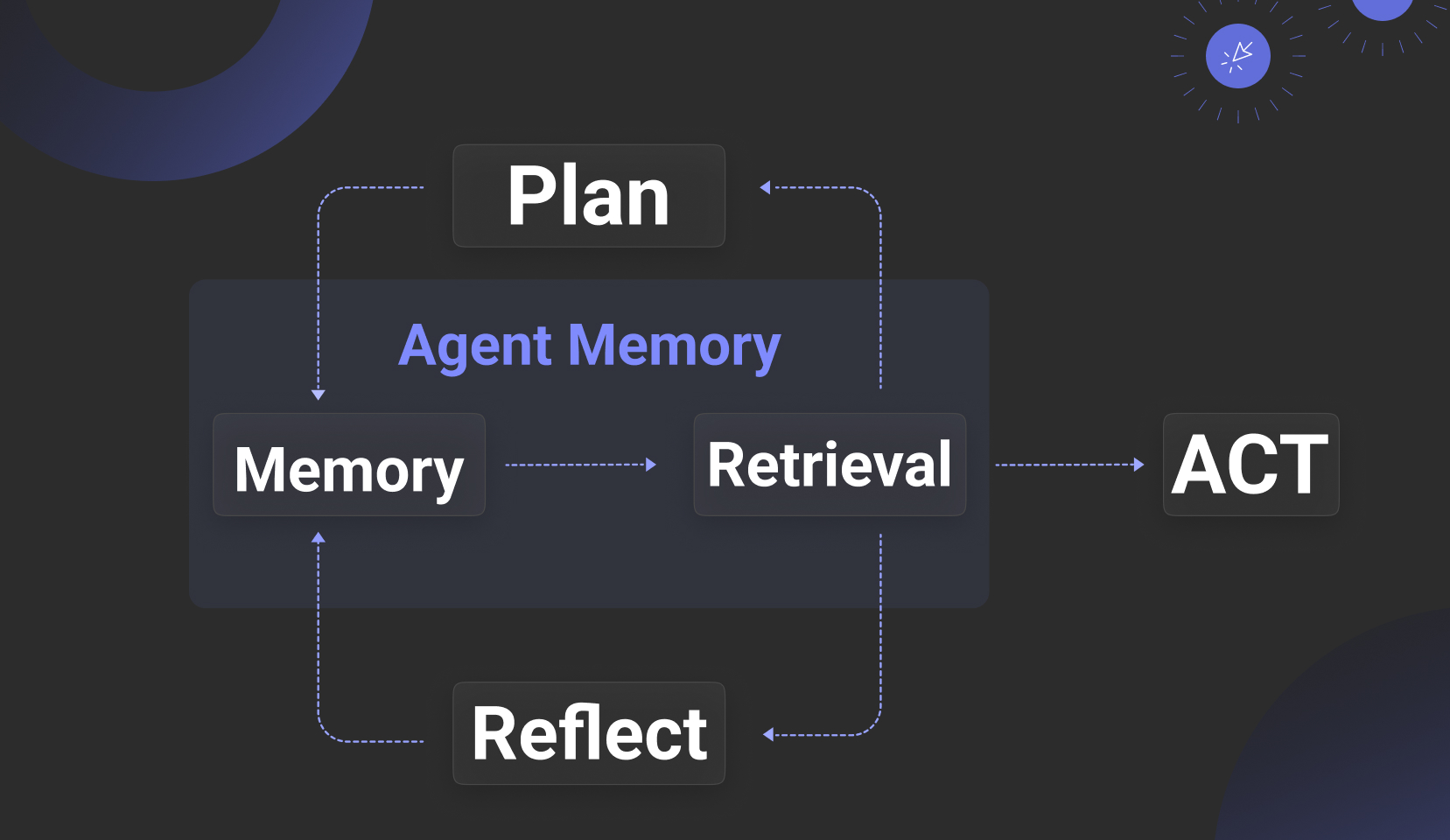
可以说,跟 Agent 在一起,才有 Memory 的意义,因此,一个天然而直接的问题就是 Memory 和 RAG 有什么区别。【参考 4 】对 Memory 做了详细的总结,大体上把 Memory 分为 Contextual 和 Parametric 两大类,而后者通常跟 KV Cache 和模型相关,我们在下文会有所提及。因此通常来说,所谓的 Agent Memory 都是指上下文记忆,它为 Agent 带来两方面的价值:
其一是保存任务管理的元数据:例如对于一个 Agentic Reasoning 来说,如果我们需要引入 Planning 的确定性,例如加入人工反馈,那这就意味着 Plan 不完全是由 LLM 单方面决定,而是需要有地方保存,从而使得 Agent 从一个无状态的应用成为一个有状态应用。此外,如果需要对 Agentic Reasoning 过程中的任务分解进行跟踪,我们同样需要一个地方保存这些任务相关的元数据。
其二是上下文管理,除了上下文保持之外,Memory 还可以起到缓存和加速 LLM 结果,以及提供个性化回答所需要的个性化数据。

从接口上来说, Memory 需要提供的,在图上可以看到有4类:除了 Updating 很容易理解之外,其他 3 点分别解释如下:Indexing,说明 Memory 需要提供搜索能力(而不只是查询),事实上,前述的 2 个 Agent 价值,后者的上下文管理在很多场景下需要的是搜索,特别是实时搜索能力,例如 Session 数据被插入到短期记忆,然后提供跟某个主题相关的搜索能力从而加强后续对话的上下文等等;Forgetting 代表遗忘,这是 Memory 被用来设计模拟人类的操作,遗忘是为了更好地聚焦,从技术上来讲,是因为数据量少往往意味着搜索精确度更有保障;Consolidation,字面意思是巩固,这也是 Memory 被用来设计模拟人类的操作,它代表对保存到 Memory 的数据进行摘要和笔记,从技术实现来说,它跟 RAG 中的 GraphRAG 很有关联或者可以就是一件事:通过让 LLM 对 Memory 内容进行整理成知识图谱从而让这些内容在召回时提供更多辅助素材。
下边这张图,概括了 Memory 和 RAG 的真实关系。可以看到,RAG 实际上就是 Memory 长期记忆的一部分,而 Memory 还包含短期记忆,短期记忆通常存放的是 Agent 的 Session 对话和个性化信息,这些信息经常以原始数据的方式保存,而高价值的部分通过 Consolidation 接口被保存到另一部分长期记忆中。
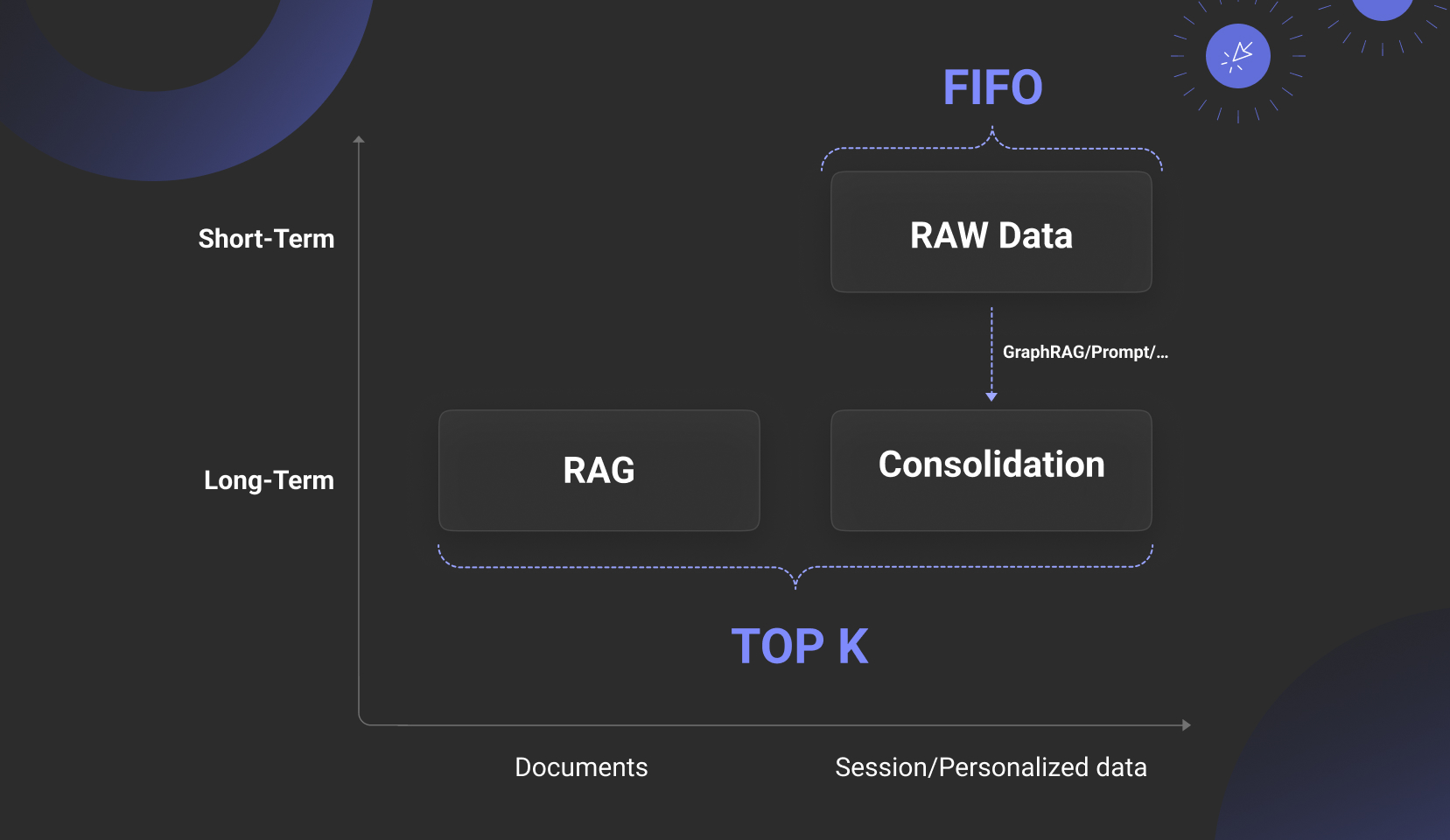
因此,没有好的 RAG 支撑的 Memory 肯定是空中楼阁,而除去这层关系之外,Memory 所剩的层面就非常薄了。至于 Parametric Memory (参数化记忆),这看起来似乎更加贴近“记忆”的本性,但从核心原理上,技术并没有什么高下之分:参数化记忆是以 KV Cache 为载体以 Attention 运算为依托的重量级实现,它跟 LLM 的推理引擎密切绑定,其实质是一种稠密注意力实现机制。而以 RAG 为依托的长期记忆,它的本质也是给 LLM 在无限上下文提供过滤和辅助推理的素材,本质也是一种注意力机制,只是这是一种稀疏注意力。如果把 KV Cache 也用稀疏注意力实现,会带来什么后果?我们下文来讨论这个问题。
“RAG 2025:技术高原期的挑战突围”
长文本推理依赖分层索引,多模态数据遭遇存储膨胀瓶颈,基础设施滞后制约创新落地
谈完了 RAG 和 Agent 的关系让我们再回到 RAG 本身。2025 年虽然有关 RAG 的论文仍保持一定的频率,但思想和系统上的创新确实乏善可陈。那么 RAG 技术本身,是否已经来到了分水岭?RAG 的核心是信息检索,而这确实是一个发展非常成熟的领域,可是 RAG 又在传统信息检索的场景外引入了更多的需求,一个是提问的多样化,一个是多模态数据。
先来看第一方面:提问的多样化,这在信息检索领域是永恒的话题——如何弥补提问和答案之间的语义鸿沟。方法有很多,例如 2024 年的热门工作 GraphRAG,Contextual Retrieval,RAPTOR,乃至于 RAGFlow 推出的借助于人工领域专家的自动标签库等等。这些工作,本质上就是一种稀疏注意力——复杂提问,涉及到的上下文就会更长,因此需要在很长的上下文当中寻找跟答案有关的注意力。可以说,对于简单提问,只要有好的 Chunking 和有效地多路召回,解决手段已经固定;但是对于复杂提问,仍然没有非常有效的实现。所以,就有人提出,既然弥补语义鸿沟,主要依赖 LLM 产生额外的数据,那么为何不索性直接把知识注入 LLM 的工作记忆,从而规避这种奇技淫巧——这种路线,最早来自于 CAG【参考 5】,意思就是用 KV Cache 保存经过 LLM 转化成 KV 的全量数据。进一步的工作,为避免稠密注意力带来的巨大带宽和计算需求,出现了以 KV 数据为依托结合数据库技术从而实现稀疏注意力的方案,比如 RetrievalAttention【参考 6】 及其后续改进 RetroInfer 【参考 7】,以及 AlayaDB 【参考 8】,这些工作,进一步将 KV Cache 数据分布在 2 个区域,一个仍在 KV Cache 中,更多地则保存到向量索引或者向量数据库中,在生成过程中——相当于 LLM 推理过程中的 Decoder 阶段,根据当前 Context 的 Q 来召回向量索引中的 V,从而加载这些 V 到 KV Cache,完成最后的 Attention 计算,如下图所示。
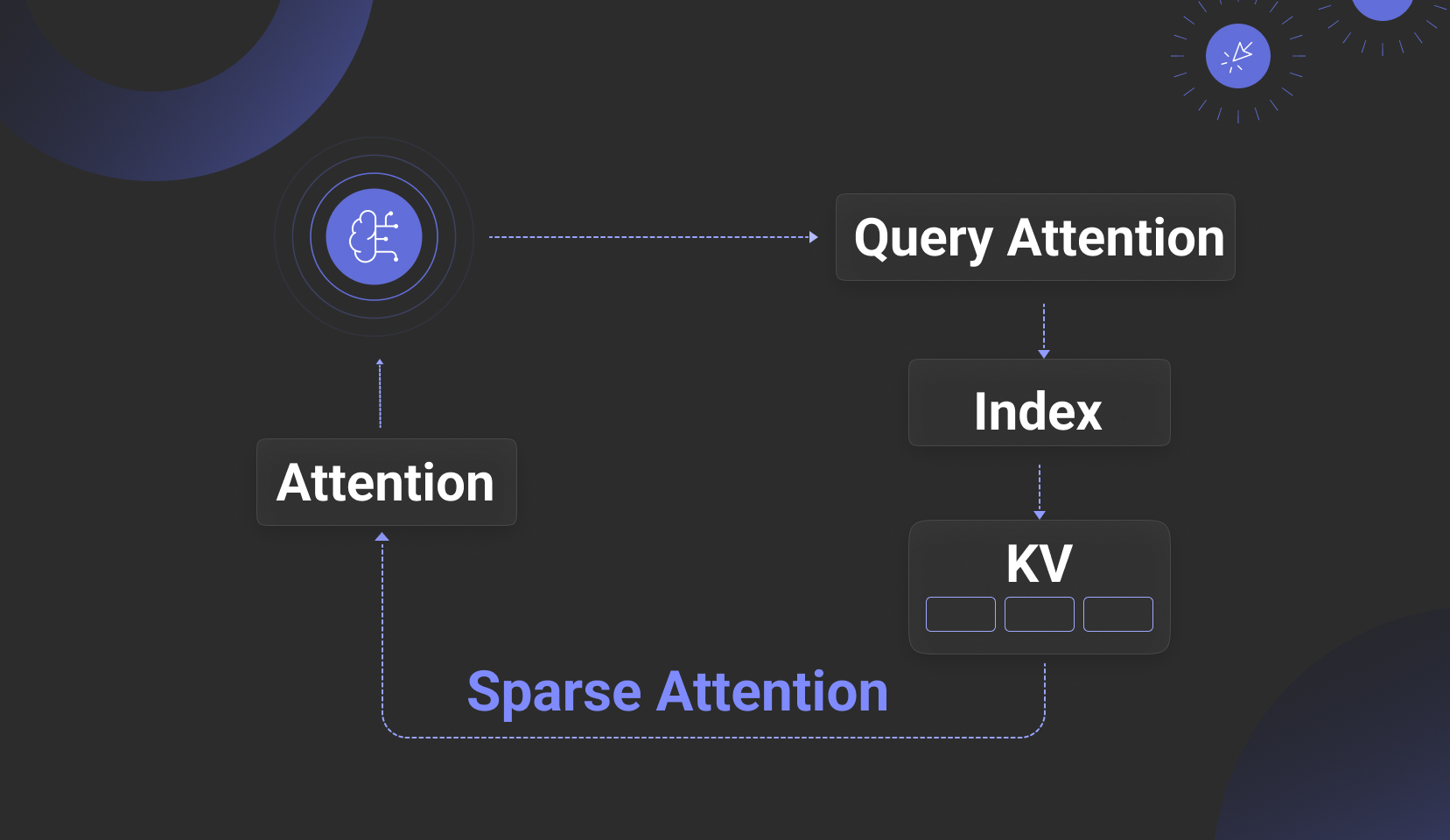
听起来这种技术可以解决很多当前 RAG 的痛点,但它仍然面临问题,因为这类方案的提出,更多都是为了解决 LLM 推理的成本问题——传统基于 Prefill/Decoder 分离的推理方案,属于稠密注意力实现,效果好而成本高,依赖大规模的 GPU 显存;而这类稀疏注意力方案,借助于普通 CPU 内存甚至硬盘和稀疏注意力(其实就是 ANN 向量搜索)来降低推理成本。因此这类方案需要跟 LLM 推理引擎强绑定,这需要修改推理引擎,使得接口不仅仅是纯文本,还包含向量数据,所以这就把 LLM 的使用限制在仅能采用开源 LLM 的前提之下;此外,由于是在 Decoder 阶段频繁调用,这意味着这类方案跟 LLM 推理引擎必须物理上部署在一起以降低网络延迟,故而这就把场景限制在仅支持私有化部署上。另一方面,这种推理搜索一体的 “Attention Engine”,它也未必能缓解 RAG 的问题,特别是长文档,在长上下文 LLM 中,冗长的上下文会导致模型下降,中间的重要细节会被跳过、曲解或者忽略,在特定细节的准确性方面,传统 RAG 的手段依然有优势。
所以,我们需要对 “Attention Engine” 方案保持关注,但同时,真正落地的,还是在 LLM 之外的 RAG,如何更好地解决长文本上的辅助推理问题。Attention Engine 也好, Search Engine 也罢,它们目前的擅长点并不完全重叠——前者在较少的数据上快速推理,后者在海量数据上快速定位,两者更多仍是配合关系,但 RAG 的内涵,总是在不断变化和扩大的。
目前,除了 GraphRAG,RAPTOR 这些可以处理跨 Chunk 的手段之外 ,在更长文本的召回和推理上目前并没有形成工程落地意义很强的做法,总结起来路线大约有如下:
-
RAG 不做 Chunking,仅做简要召回,然后整个文档都丢到上下文里回答。这种在文档较少时可以,文档数量较大时,很难保证召回的文档是合适的,毕竟缺乏对文档整体全局信息的理解。
-
文档内 Chunking 在索引阶段形成包含目录结构的树状结构,同时提供文档级召回,召回的文档的同时在文档内部按照树状结构进行遍历,形成文档内的 Agentic RAG。
-
各 Chunking 之间做好重叠(overlap),文档内 Chunking 实现分层次索引,实现粗细粒度组合的召回策略。
这些策略都不难想象,也都各有问题。作为工具提供者,RAGFlow 也会后续提供类似功能。
再来看第二方面,多模态数据。在去年底的回顾中,我们曾认为 2025 年 RAG 本身的一个热点就是“MM-RAG”,亦即为多模态 RAG。然而到了年中,我们并没有发现这样的趋势流行起来。这里边的主要原因,还是因为配套的 Infra 并不成熟。我们曾提及,MM-RAG 的配套模型中,延迟交互模型仍然占据主导地位,这意味着 Embedding 模型的输出是 Tensor,又称多向量,如下图中,一张图片采用 1024 个向量来表示,平均每个向量采用 128 维浮点数表示。截止目前,已有不止一家向量数据库提供了对 Tensor 的支持,但却很少有完整的让 Tensor 能够应用的方案,这是因为 Tensor 带来的数据膨胀会多达 2 个数量级,因此,除了原生对 Tensor 类型的支持,还需要有整体的解决方案来降低 Tensor 存储膨胀。这包含:数据库层面可以引入二值量化,也就是用 1 bit 表示向量的一个维度,这可以让存储空间只占用原始尺寸的 1/32,那么在向量索引层面,就需要支持这种二值量化的多向量索引,或者说 Tensor 索引。同时,在 Reranker 阶段,为降低二值量化带来的精度损失,可以选择根据二值量化再恢复成浮点数,再重新计算最终的相似度,这样可以让精度损失尽可能最小化。
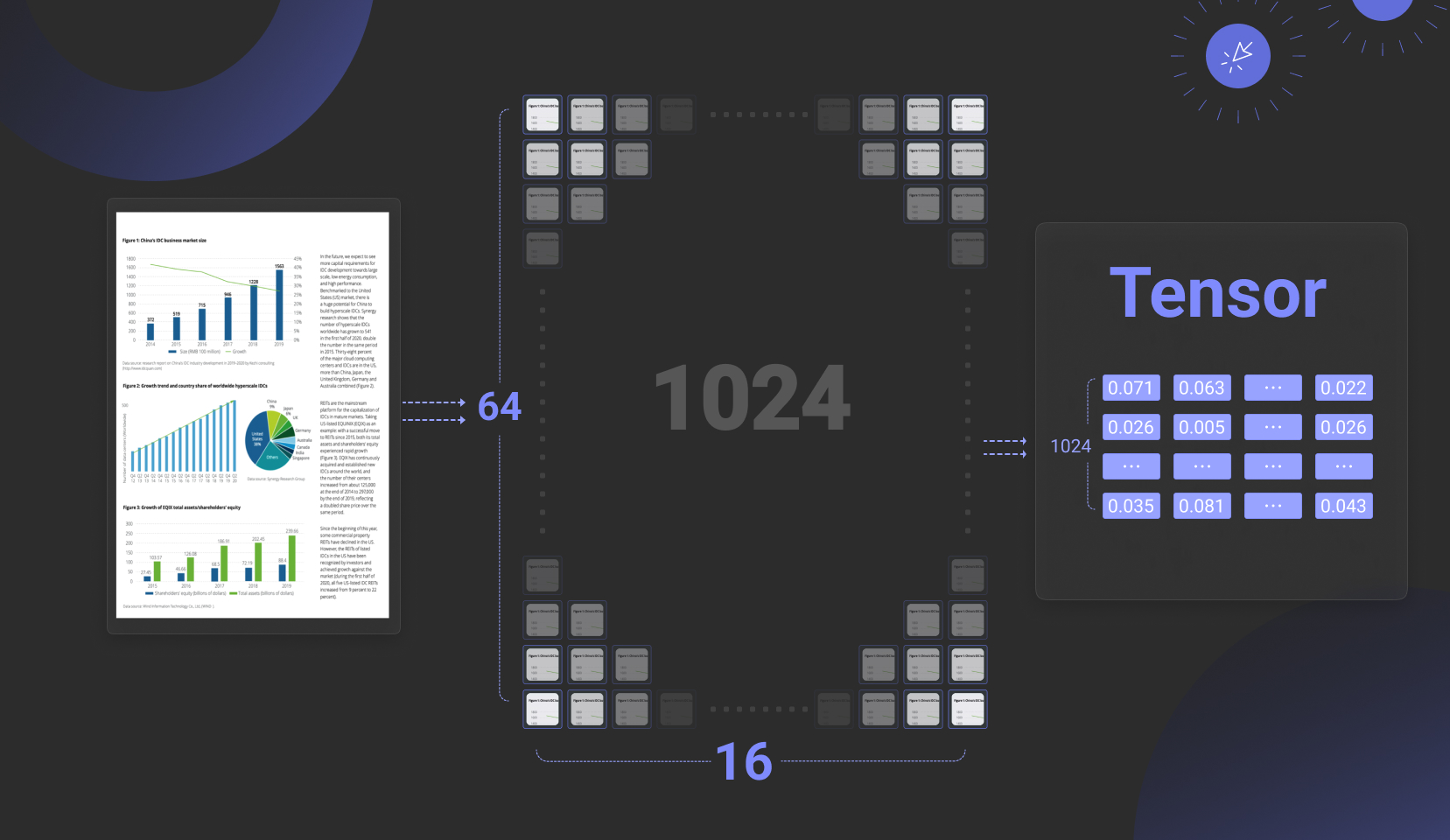
在模型层面,同样需要努力降低 Tensor 存储膨胀带来的开销。这包括通过 MRL 学习(套娃)进一步降低 Tensor 内每个向量的维度,例如降低到 64 维,就可以降低一半的存储开销,当然代价是召回精度略有下降;这还包括引入 Token/Patch 合并的操作,来降低 Tensor 内向量的数量,例如将 1024 个 Patch 降低到 128 个 Patch。在模型层面的工作,目前对于文本排序有一些工作,但是对于多模态 RAG 的需求,还需要更多的工作出现。因此,多模态 RAG 还在等待配套基础设施的成熟。
END
综上盘点,我们可以看到,RAG 本身确实在 25 年进步不显著,于此同时,RAG 和 Agent 的关系却更加密切,无论是作为 Agent Memory 的支撑,还是搭配 Agent 解锁 DeepResearch。站在 Agent 的视角,或许可以把 RAG 看作是各种 Tools 中的一个,但是由于 RAG 接管了非结构化数据,接管了 Memory 管理,这使得它是 Agent 各种 Tools 最基础和最重要的之一,我们完全可以说没有 RAG 就没有 Agent 在企业端地真正应用。因此 RAG 作为单独一层的价值,比过去更加突出,因此,这些内容,将是 RAGFlow 下一个版本的主要特性。至于 RAG 在发展中所面临的系列问题,我们还是把它留给时间,毕竟,RAG 本身只是一种架构的简称,它的内涵,需要 Infra 和模型的共同迭代演进。欢迎持续关注和Star RAGFlow: https://github.com/infiniflow/ragflow

参考文献
-
https://market.us/report/agentic-retrieval-augmented-generation-market/
-
https://www.anthropic.com/engineering/building-effective-agents
-
Reasoning RAG via System 1 or System 2: A Survey on Reasoning Agentic Retrieval-Augmented Generation for Industry Challenges https://arxiv.org/abs/2506.10408
-
Rethinking Memory in AI: Taxonomy, Operations, Topics and Future Directions https://arxiv.org/abs/2505.00675
-
Don't Do RAG: When Cache-Augmented Generation is All You Need for Knowledge Tasks https://arxiv.org/abs/2412.15605
-
RetrievalAttention: Accelerating Long-Context LLM Inference via Vector Retrieval https://arxiv.org/abs/2409.10516
-
RetroInfer: A Vector-Storage Approach for Scalable Long-Context LLM Inference https://arxiv.org/abs/2505.02922
-
AlayaDB: The Data Foundation for Efficient and Effective Long-context LLM Inference https://arxiv.org/abs/2504.10326

















 1555
1555

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









