




 本文介绍了列式存储如何提高数据查询效率,特别是Hive中的ORC和Parquet格式。ORC文件采用行列式存储结合行组,提供多级索引,支持ACID事务,而Parquet同样采用列式存储,数据按行组和页划分,具备高效的压缩和编码。这两种格式优化了大数据扫描和分析的性能。
本文介绍了列式存储如何提高数据查询效率,特别是Hive中的ORC和Parquet格式。ORC文件采用行列式存储结合行组,提供多级索引,支持ACID事务,而Parquet同样采用列式存储,数据按行组和页划分,具备高效的压缩和编码。这两种格式优化了大数据扫描和分析的性能。
传统的行式数据库,数据按行存储,在没有使用索引的情况下,如果要查询一个字段,需要将整行的数据查找出来,再找到相应的字段,这样的操作是比较消耗I/O资源的。最初的解决方式是建立Hive索引。Hive建立索引是一项比较消耗集群资源的工作,并且需要时刻关注是否更新。数据如有更新,就需要对索引进行重建。数据有更新却没有及时重建或者忘了重建,则会引发使用过程的异常。正是建立Hive索引成本高,又极容易引发异常,所以在实际生产中,Hive索引很少被用到。那列式存储可以解决这个问题。
列式存储的数据则是按列进行存储,每一列存储一个字段的数据,在进行数据查询时就好比走索引查询,效率较高。但是如果需要读取所有的列,例如一个数据平台刚接入数据,需要对所有的字段进行校验过滤,在这种场景下列式存储需要花费比行式存储更多的资源,因为行式存储读取一条数据只需要一次I/O操作,而列式存储则需要花费多次,列数越多消耗的I/O资源越多
ORC格式
ORC存储的文件是一种带有模式描述的行列式存储文件。ORC有别于传统的数据存储文件,它会将数据先按行组进行切分,一个行组内部包含若干行,每一行组再按列进行存储,下图为简化图
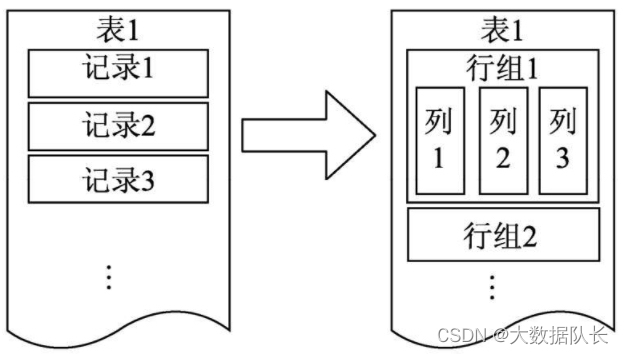
ORC 的行列式存储结构结合了行式和列式存储的优点,在有大数据量扫描读取时,可以按行组进行数据读取。如果要读取某个列的数据,则可以在读取行组的基础上,读取指定的列,而不需要读取行组内所有行的数据及一行内所有字段的数据
ORC 文件结构分为三部分:
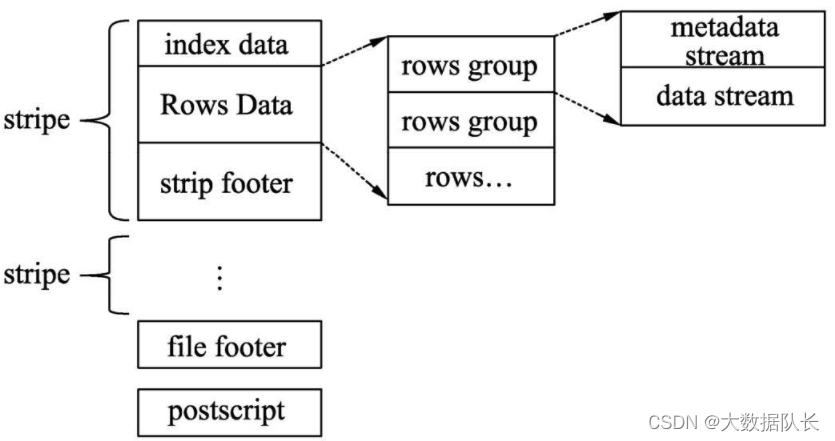
- 1.条带(stripe):ORC文件存储数据的地方
- 2.文件脚注(file footer):包含了文
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1099
1099

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









