Application/App
指的是用户编写的Spark应用程序/代码,包含了Driver功能代码和分布在集群中多个节点上运行的Executor代码。
提示:当对RDD操作代码都是运行在Executor中代码
使用不同语言,编写代码不一样:
Java/Scala语言:编译以后Class文件
Python语言:脚本文件
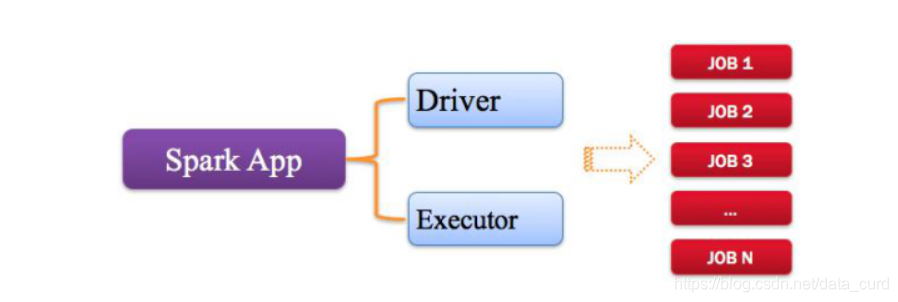
Spark应用程序,由一个或多个作业JOB组成(因为代码中可能会调用多次Action)
每个Job就是RDD执行一个Action函数:没有返回值,或者返回值不是RDD
Driver
Spark中的Driver即运行Application的Main()函数并且创建SparkContext,其中创建SparkContext的目的是为了准备Spark应用程序的运行环境。
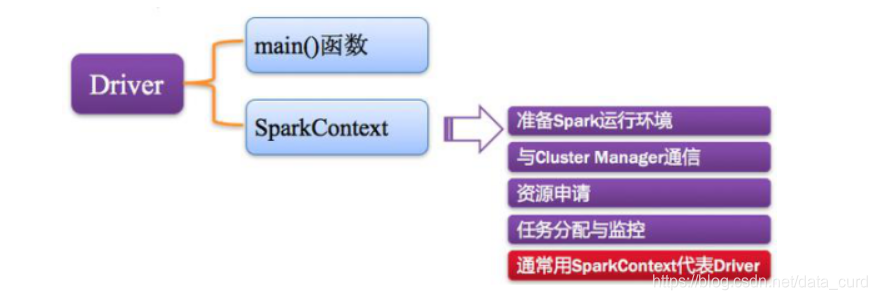
在Spark中由SparkContext负责和ClusterManager通信,进行资源的申请、任务的分配和监控等;
SparkContext向RM或Master申请资源,运行Executor进程(线程池)。
当Executor部分运行完毕后,Driver负责将SparkContext关闭。
Cluster Manager
指的是在集群上获取资源的外部服务,常用的有:
1)Standa





 本文深入解析Spark的重要术语,包括Application/App、Driver、Cluster Manager、Worker和Executor。重点阐述RDD及其依赖,如Narrow Dependency和Shuffle Dependency,以及DAG、DAGScheduler、TaskScheduler、Job、Stage和TaskSet的概念。每个Job由DAG图表示,Action操作触发Job,Stage和Task定义了计算任务的执行流程。
本文深入解析Spark的重要术语,包括Application/App、Driver、Cluster Manager、Worker和Executor。重点阐述RDD及其依赖,如Narrow Dependency和Shuffle Dependency,以及DAG、DAGScheduler、TaskScheduler、Job、Stage和TaskSet的概念。每个Job由DAG图表示,Action操作触发Job,Stage和Task定义了计算任务的执行流程。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 575
575

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









