




 本文对比Redis与Memcached,深入探讨Redis的特性及其在缓存优化中的优势。介绍Redis的数据结构、功能特性及安装配置过程。
本文对比Redis与Memcached,深入探讨Redis的特性及其在缓存优化中的优势。介绍Redis的数据结构、功能特性及安装配置过程。
常识:
磁盘:
1,寻址:ms
2,带宽:G/M
内存:
1,寻址:ns
2,带宽:很大
秒>毫秒>微秒>纳秒 磁盘比内存在寻址上慢了10W倍
I/O buffer:成本问题
磁盘有磁道,磁道有若干扇区,而一扇区是512Byte,这使得带来一个成本问题:索引效率变得非常有问题:
因此,操作系统做了优化规定,无论你读多少,都是最少4k从磁盘拿,而也可以依据上层应用的需要取4k的整数倍来进行读取,进而提高IO的效率。例如如果是存储视频文件,那每次寻址读4k便又显得有些少了,此时需要适当提高大小。
数据在内存和磁盘存储大小不同?
内存中一份数据存在多个引用,一份数据可以得到复用,而磁盘可没有指针的概念,就得需要原样拷贝若干份。
传统型关系数据库
必须给出schema类型来预先在磁盘中确定好一行的宽度,倾向于行级存储,这样便于后续的同行修改无需变动其他地方。
但传统型关系数据库数据库会存在问题:
表很大,性能下降?
如果表有索引,增删改变慢,维护成本变高。
查询速度呢?
1,1个或少量查询依然很快
2,并发大的时候会受硬盘带宽影响速度
人间氪金数据库
SAP HANA
一个内存级别的关系型数据库
拥有2T的内存
但造价不菲,超级公司专用。
折中方案缓存
依托于计算机体系2个基础设施
1,冯诺依曼体系的硬件
2,以太网,tcp/ip的网络
因此使得我们不得不只能用缓存的方案。
通过以下网站我们可以大致了解到目前市面上各种数据库的排名:
https://db-engines.com/en/ranking
Redis初识
这里给出一个大概的数值,redis可以达到秒级10w操作,传统IO型数据库达到秒级千操作就差不多了。。 可见两者相差比较多。
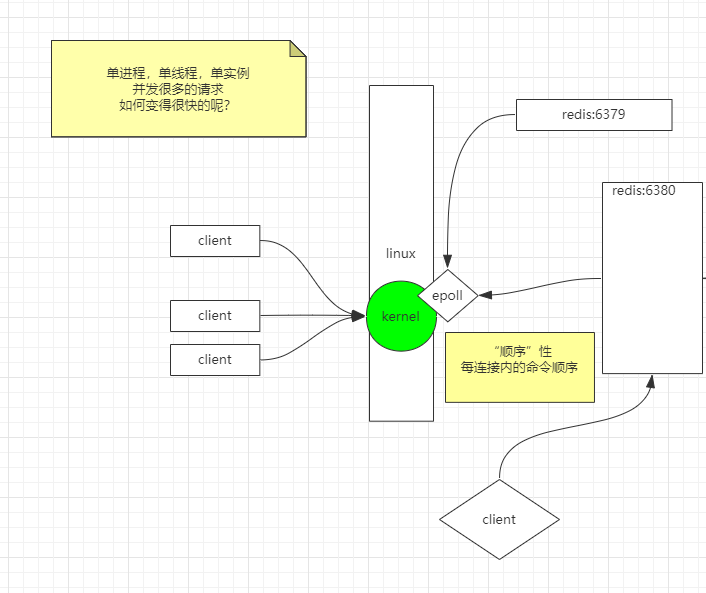
而本次的缓存选用的主角,就是redis。
值得一提的是,redis面对多用户操作请求是使用的单进程单线程进行实现的,借助了epoll(参考我写的IO发展史了解epoll)来实现,这样,保证了单连接的所有指令是顺序化的。
首先看一下redis官方有如下描述:
Redis 是一个开源(BSD许可)的,内存中的数据结构存储系统,它可以用作数据库、缓存和消息中间件。
它支持多种类型的数据结构,如 字符串(strings), 散列(hashes), 列表(lists), 集合(sets), 有序集合(sorted sets) 与范围查询, bitmaps, hyperloglogs 和 地理空间(geospatial) 索引半径查询。
Redis 内置了 复制(replication),LUA脚本(Lua scripting), LRU驱动事件(LRU eviction),事务(transactions) 和不同级别的 磁盘持久化(persistence), 并通过 Redis哨兵(Sentinel)和自动 分区(Cluster)提供高可用性(high availability)。
Redis和Memcached
常用的缓存我们知道有redis,memcached。。。两者都是k,v形式的,为什么后续redis慢慢逐渐取代memcached?
主要的,就是memcached没有数据类型的概念,value就是单纯的字符串。而redis的value确是非常的丰富的。
实际上字符串其实也能代表很复杂的数据结构,例如json字符串,从这个角度看,好像类型有无跟我们开发人员的关系不是很大。
那两者差距出在哪里呢?如下图
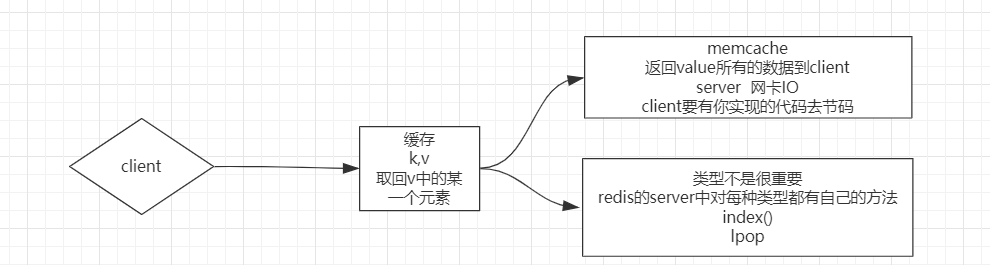
图上是一个client去分别连接memcache和redis的情况
memcache会全盘返回value值,由客户端进行对value进行解析处理成可用的数据类型。
redis则因自身server含有各种针对不同类型的函数,因此可完成在server端的处理,直接返回结果数据,将处理在server端进行。带来的好处就是,更加友好方便的调用类型自带API操作,而无需自己手动再进行处理,更重要的是一次传输的数据量将变得更少。
沿用大数据的一句话就是:redis做到了计算向数据移动。
安装Redis
搭建环境,我选用的是centos6.5进行搭建,选用的redis版本是5.0.5。
安装redis我们可以通过官网下载包,然后通过ftp工具将安装包传输进虚拟机,也可以直接使用wget命令直接进行安装
因此,第一步,首先进行对wget的安装。
yum install wget
接下来使用wget进行下载
wget http://download.redis.io/releases/redis-5.0.5.tar.gz对redis进行解压
tar xf redis-5.0.5.tar.gz
接下来移动到解压的文件夹里面,因为redis是用c进行编写的,所以需要在linux上执行make install这一系列的命令来完成安装
关于make
本质上,make命令是linux自带的,用于编译各种语言的命令,但需要给他一个编译规范,因此Makefile就是那个规范文件,因此此命令也需要在有Makefile
的目录里执行才可以,而make命令会去隐式调用Makefile文件,无图无真相,看一下Makefile的内容:
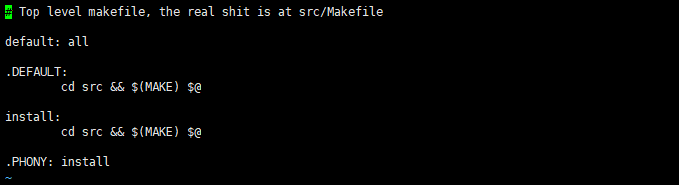
可以看到,它实际是调用了src/Makefile ,那才是实际的脚本逻辑。
我们在去看一看这个真正的Makefile:
可以看到内容是非常的多了。。
继续我们的安装,执行make命令。
make
执行该命令时可能会报错,那么可能是你缺少gcc的环境,因为redis是用c编写的,你想要编译的话,自然需要c的编译环境。
yum install gcc然后需要去除掉先前生成的垃圾编译文件
make distclean
此时移动到src中,发现多了许多的可执行文件。。
除了单纯的make命令,还有一个make install命令,make命令负责了编译生成可执行文件,而make install则其实就是把可执行文件从当前源码中抽离出,拷贝到某个目录下。
因此,这里我们可以执行:
make install PREFIX=/usr/local/redis5
接下来就是配置redis的环境变量
vi /etc/profile
加入一行:export REDIS_HOME=/usr/local/redis5
并在export PATH后面追加上REDIS_HOME:

保持退出,执行刷新系统环境变量:
. /etc/profile此时,发现通过输入redis-cli可以直接联想出内容,说明环境变量已经配置完毕。
还差最后一步了,把redis配置成服务的样子!
回到刚刚的源码包目录下,移动到utils目录里,执行里面的脚本文件:
./install_server.sh 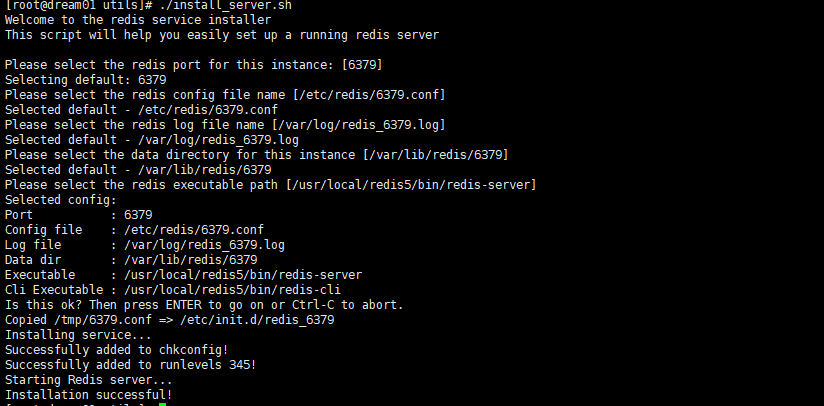
如图,会让你输入本次注册服务的reids的端口号,配置文件路径,日志文件路径等等,由此可见,一个redis可以有多个实例,不同端口就好了。。。
这里我们因为是第一个,所以一路回车,让它默认就好了。。而如果想多个,步骤一模一样,端口变一下就好了。。
根据提示,我们也可以看出一些信息:把该服务设置成了开启启动,并在6379端口启动了该服务。
通过 ps -ef | grep redis可以看到,该redis进程确实已经启动了。

至此,我们的redis就算搭建完成了。

















 127
127

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









