





写在最前
本故事主要介绍在网页上部署模型的来龙去脉,你想问的问题,可能都可以在这里找到答案
在这个 AI 内容生成泛滥的时代,依然有一批人"傻傻"坚持原创,如果您能读到最后,还请点赞或收藏或关注支持下我呗,感谢 ( ̄︶ ̄)↗
能在网页上跑模型吗?
丹尼尔:嘿,蛋兄,你这是要去哪儿遛弯呢?
蛋先生:刚吃完饭,准备散下步消消食
丹尼尔:一起呗。蛋兄,我最近对 AI 有点着迷,突然冒出个念头,你说咱们能不能在网页上跑机器学习模型呢?
蛋先生:这个嘛,确实可以
为什么可以在网页上跑模型?
丹尼尔:这我就纳闷了,一个专门看网页的浏览器,怎么还能“兼职”跑模型呢?蛋兄,快给我讲讲呗
蛋先生:你想啊,一颗种子能不能发芽,得看它有没有适合生存的环境。模型也一样,得有个能跑的“土壤”——runtime,还得有足够的“阳光”和“水”——也就是算力和存储
丹尼尔:哦,我好像有点懂了。但我还是不明白,浏览器是怎么做到这一点的
蛋先生:自从浏览器有了 WebAssembly 之后,它的“胃口”可就大了去了!现在,很多用 C、C++、Rust 等编程语言写的应用,都能编译成 WASM 格式,在浏览器里跑。这样一来,浏览器就能处理更加复杂的计算任务了
丹尼尔:原来如此!也就是说,原来用 C++ 等写的模型 runtime,现在可以直接放进浏览器里,成了模型的“土壤”了!
蛋先生:对头!而且,浏览器的 WebGL、WebGPU 这些技术,还能让你的应用用上 GPU 资源,速度更上一层楼!否则,能跑,但很慢,也没啥意义
丹尼尔:哈哈,我总结一下啊,WebAssembly 让模型有了土壤,WebGL、WebGPU 让算力提升成为可能!
蛋先生:不错不错,总结得挺到位!
为什么要跑在浏览器呢?
蛋先生:那我问你,你为什么想把模型跑在浏览器上呢?
丹尼尔:额~,这~,就觉得挺酷的嘛!不过说实话,我还真没认真想过这个问题。蛋兄,你给说道说道?
蛋先生:来,咱们从请求链路说起。模型部署在浏览器上,是不是就不用请求服务器了?
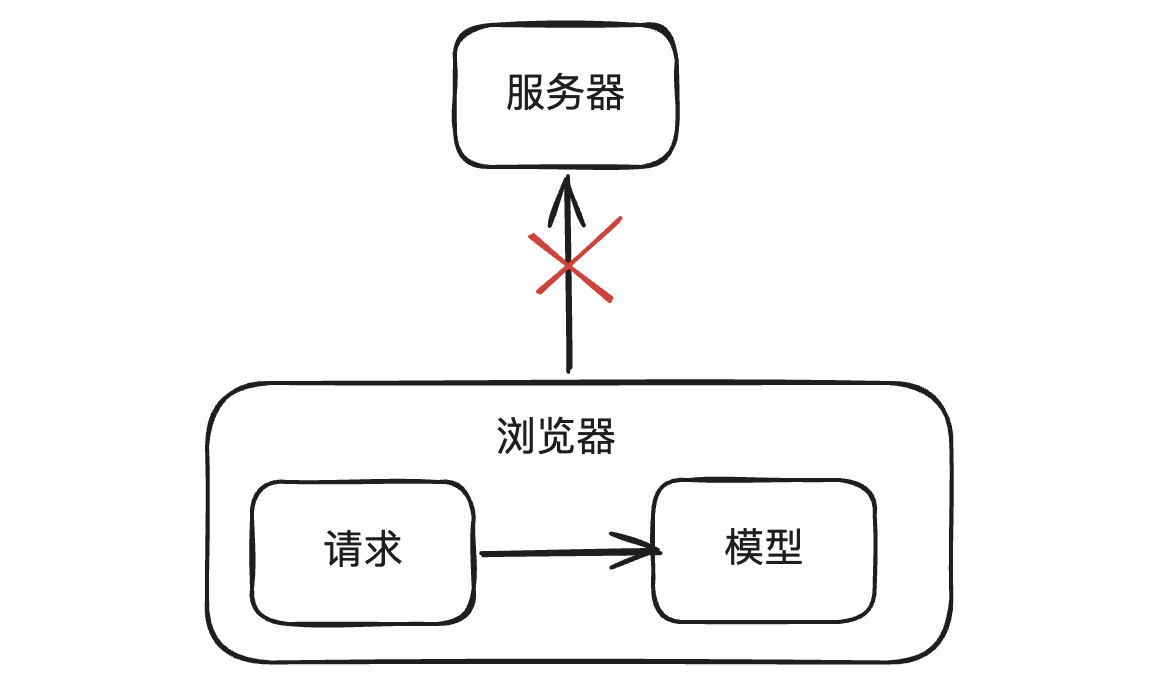
丹尼尔:那是肯定的
蛋先生:对于客户端,请求没有离开用户设备,这样是不是就可以更好地保护用户隐私了?
丹尼尔:是哦
蛋先生:计算是在浏览器本地进行的,距离用户更近,也没有网络请求的损耗,响应速度通常更快,这样是不是就可以提升用户体验了?
丹尼尔:是哦
蛋先生:还有,模型已经部署在浏览器了,只要应用本身支持离线访问,那是不是就可以离线使用了?
丹尼尔:是哦
蛋先生:对于服务端,因为把计算压力分摊出去了,是不是就可以减轻服务器的计算压力,降低运营成本呢?
丹尼尔:是哦
蛋先生:剩下的你自己琢磨琢磨吧
怎么跑在浏览器呢?
丹尼尔:好嘞,那具体要怎么实现呢?
蛋先生:主流的机器学习框架除了训练模型外,还能部署和推理模型。比如大名鼎鼎的 Tensorflow 就有 tensorflow.js,它可以将模型部署在浏览器端。不过今天我要给你说的是 onnxruntime-web
丹尼尔:onnxruntime-web?这名字听着有点新鲜啊!
蛋先生:onnxruntime-web,可以把这个拆成 onnx,onnxruntime 和 onnxruntime-web 来说
丹尼尔:您继续
蛋先生:onnx 就是个模型格式,就像你存音乐用的 mp3 格式一样,但它存的是机器学习模型;onnxruntime 呢,就是运行这些模型的“播放器”;而 onnxruntime-web,则是让这个“播放器”能在网页上跑起来的神奇工具
丹尼尔:哦,那模型都有哪些格式呢?用这个 onnx 有什么优势呢?
蛋先生:正所谓合久必分,分久必合
丹尼尔:这是要讲三国的节奏吗
蛋先生:各个机器学习框架都有自己的模型格式,在没有 onnx 之前,你得用 tf 来部署 tensorflow 的模型,用 pytorch 来部署 pytorch 的模型。可用户只想部署个模型而已,能不能把问题简单化呢?
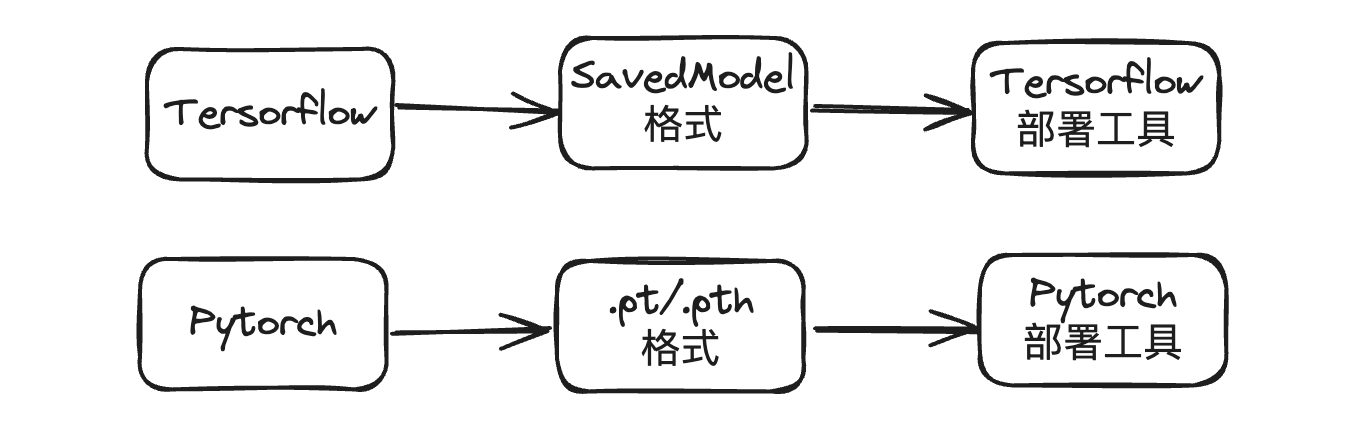
丹尼尔:确实
蛋先生:于是就有了 onnx 这个开放标准。各家的模型格式都能转换成这种标准格式,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 860
860

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









