







1-概述
Hbase与HDFS
HBase建立在Hadoop文件系统之上,利用了Hadoop的文件系统的容错能力
HBase提供对数据的随机实时读/写访问功能
HBase内部使用哈希表,并存储索引,可将在HDFS文件中的数据进行快速查找
使用场景:
瞬间写入量很大,常用数据库不好支撑或需要很高成本支山回
数据需要长久保存,且量会持久增长到比较大的场景
HBase不适用于有join,多级索引,表关系复杂的数据模型
CAP定理:
一致性(所有节点在同一时间具有相同的数据)
可用性(保证每个请求不管成功或者失败都有响应,但不保证获
取的数据为正确的数据)
分区容错性(系统中任意信息的丢失或失败不会影响系统的继续
运作,系统如果不能在某一个时限内达成数据一致性,就必须在
上面两个操作之间做出选择)
ACID定义:
原子性,一致性,隔离性,持久性
Hbase并不支持严格的ACID,而是支持到单个的行
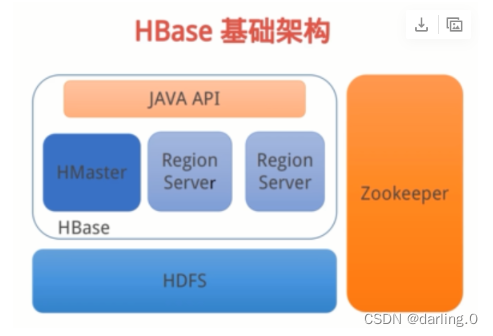
HMaster
◆HMaster是HBase主/从集群架构中的中央节点
+HMaster将region分配给RegionServer,协调RegionServer的负
载并维护集群的状态
+维护表和Region的元数据,不参与数据的输入/输出过程
RegionServer
+维护HMaster分配给他的region,处理对这些region的io请求
◆负责切分正在运行过程中变的过大的region
Zookeeper
+Zookeeper是集群的协调器
+HMaster启动将系统表加载到Zookeeper
+提供HBaseRegionServer状态信息
HBase建立在Hadoop文件系统之上,利用了Hadoop的文件系出后
的容错能力
HBase提供对数据的随机实时读/写访问功能
WWWZXtCom
HBase内部使用哈希表,并存储索引,可将在HDFS文件中的数据进
行快速查找
HBase建立在Hadoop文件系统之上,利用了Hadoop的文件系统的容错能力
HBase提供对数据的随机实时读/写访问功能
WWwZXitocom
HBase内部使用哈希表,并存储索引,可将在HDFS文件中的数据进行快速查找

















 1939
1939

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









