




总结
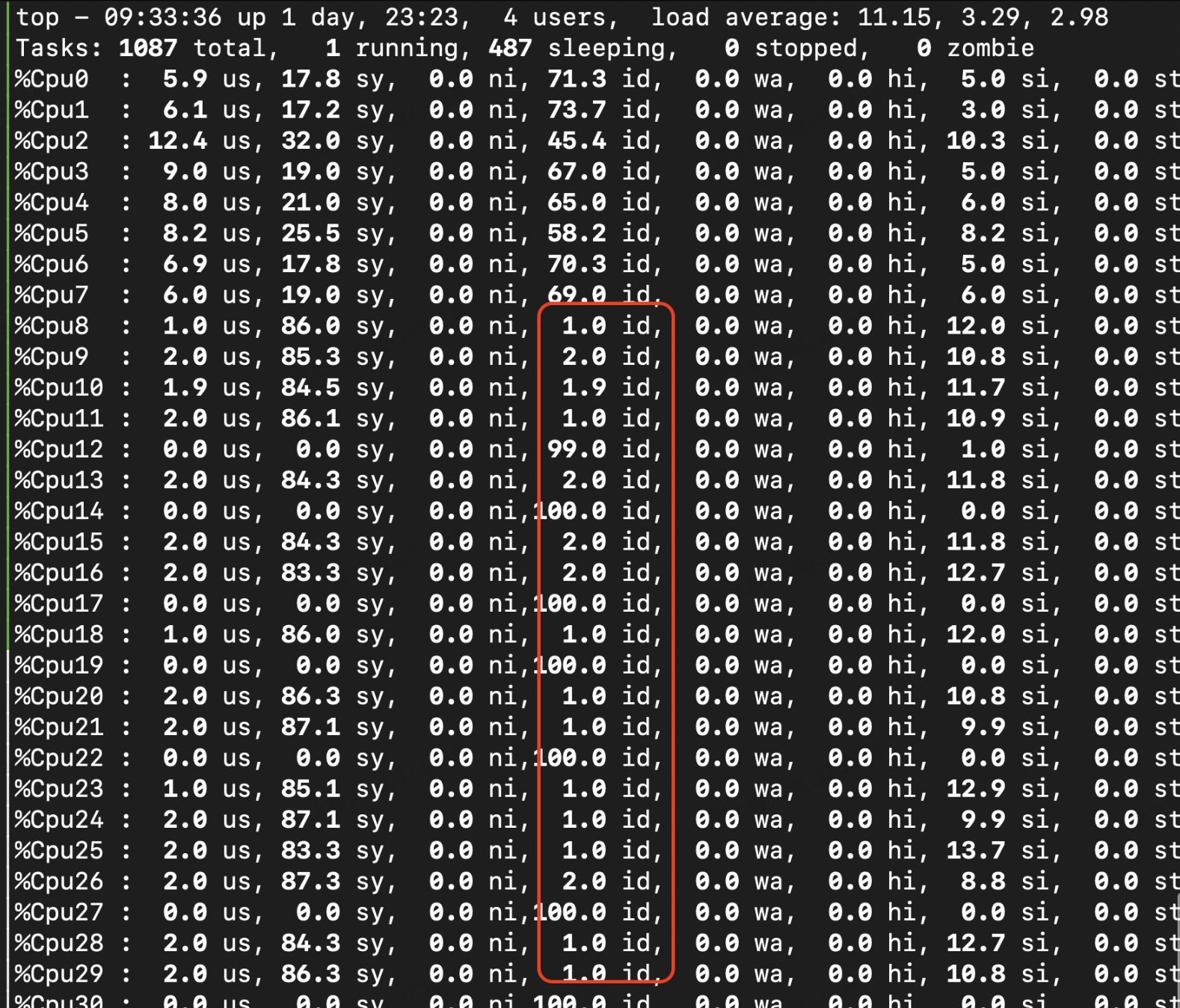
在Intel上测试nginx发现了一个比较奇怪的现象,服务端压测时候,负载总是无法压上去,反而客户端随着核数增加,负载几乎100%,并且主要集中在sys上。
# 服务端测试命令:
taskset -c 0-7 /usr/local/nginx/sbin/nginx -c /usr/local/nginx/conf/nginx.conf
# 客户端测试命令: 使用lo网口
# 短链接
taskset -c 8-31 /home/nginx-test/httpress-1.1.0/bin/Release/httpress -n 1000000 -c 200 -t 16 http://127.0.0.1:10000/index.html
分析
从当前跟随核数的特征以及top显示的结果上看,问题大概率出现在抢锁的问题上。通过perf采样,可以证实:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UkZMMRs1-1654587488940)(https://user-images.githubusercontent.com/17999499/167791493-36ab3ab2-ac2d-4094-98b8-3d1ca5c57415.png)]
__inet_check_established函数主要实现如下:
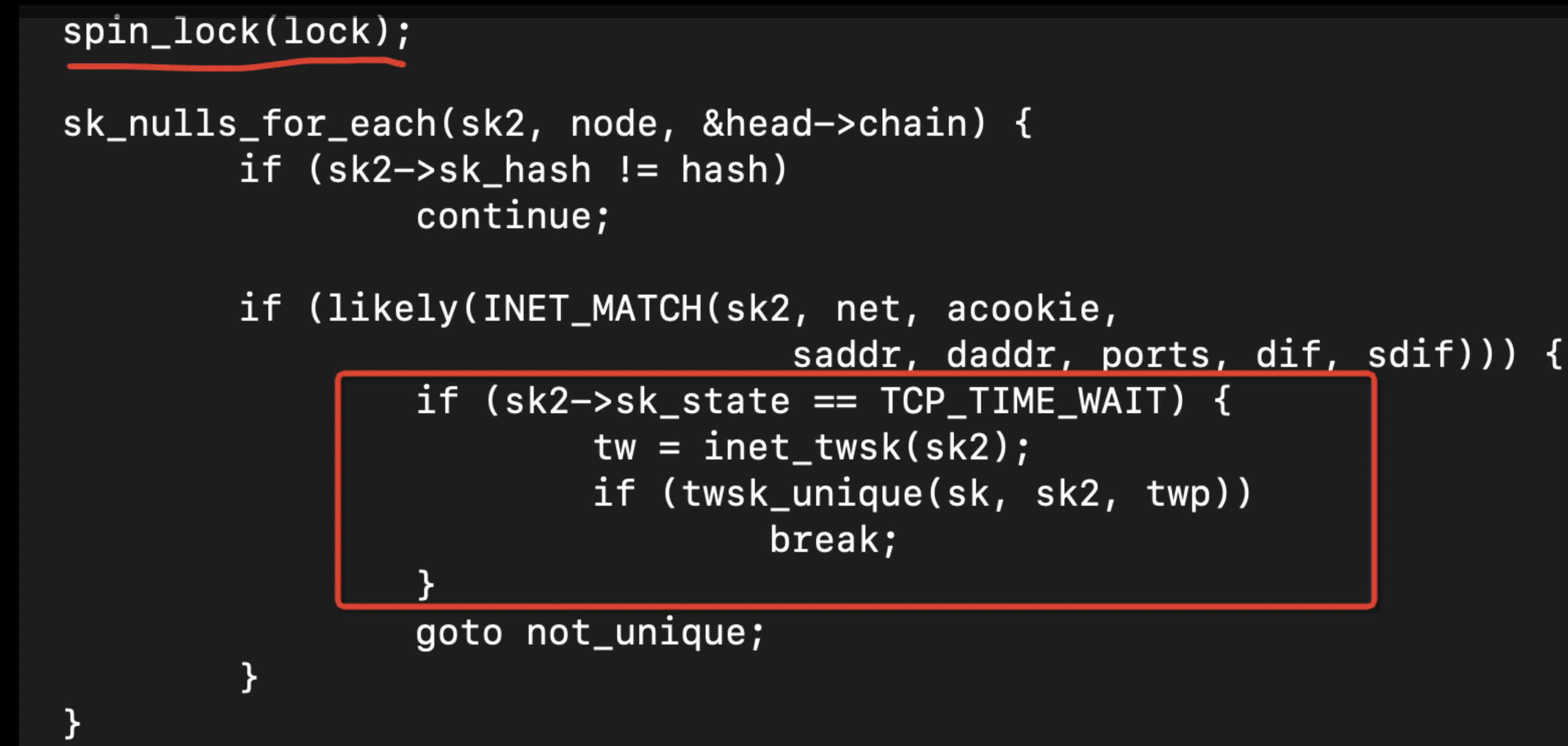
从这个函数代码大概可以分析出这个函数的主要用途是 判断当前的socket状态是否是TCP_TIME_WAIT的状态,如果是的话,就需要通过twsk_unique获得一个端口:
int tcp_twsk_unique(struct sock *sk, struct sock *sktw, void *twp)
{
const struct inet_timewait_sock *tw = inet_twsk(sktw);
const struct tcp_timewait_sock *tcptw = tcp_twsk(sktw);
struct tcp_sock *tp = tcp_sk(sk);
int reuse = sock_net(sk)->ipv4.sysctl_tcp_tw_reuse;
if (reuse == 2) {
/* Still does not detect *everything* that goes through
* lo, since we require a loopback src or dst address
* or direct binding to 'lo' interface.
*/
bool loopback = false;
if (tw->tw_bound_dev_if == LOOPBACK_IFINDEX)
loopback = true;
#if IS_ENABLED(CONFIG_IPV6)
if (tw->tw_family == AF_INET6) {
if (ipv6_addr_loopback(&tw->tw_v6_daddr) ||
ipv6_addr_v4mapped_loopback(&tw->tw_v6_daddr) ||
ipv6_addr_loopback(&tw->tw_v6_rcv_saddr) ||
ipv6_addr_v4mapped_loopback(&tw->tw_v6_rcv_saddr))
loopback = true;
} else
#endif
twsk_unique接口中,会根据tcp_tw_reuse配置来判断如何分配端口。
如果长时间找不到可以复用的端口,那么lock的时间就会变得很长,导致了锁冲突的产生。
但是很神奇的是,查看系统tcp_tw_reuse的配置,已经明确是打开了复用:

tcp_tw_reuse分析
既然tcp_tw_reuse配置已经打开,那为什么从热点上看,还有大量的连接在做hash_connect呢?
那么是否是有可能在这样大流量下的短链接本来就需要足够的端口来使用,资源已经严重不足了?
查看一下端口的使用情况以及限制:

不知道什么原因,对于系统对本地端口数量进行了限制,修改这个端口限制从40000-65535 到 0-65535后,性能提升了 100%
但是发现尽管性能提升了,但是客户端还是在大量的hash_connect抢锁, 所以似乎还有其它的问题导致了端口没有完全复用起来。
使用netstat | grep TIME_WAIT确定一下数量:

发现基本上已经达到极限了, 主要还是由于当前的吞吐量太高 ,已经端口复用已经无法承载了。


















 3791
3791

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











