



 本文探讨了欠拟合和过拟合的原因及其对模型泛化能力的影响。通过实例展示了如何利用三阶段多项式创建样本,并通过线性函数和不同训练量的拟合,说明模型选择对于提升泛化能力的重要性。
本文探讨了欠拟合和过拟合的原因及其对模型泛化能力的影响。通过实例展示了如何利用三阶段多项式创建样本,并通过线性函数和不同训练量的拟合,说明模型选择对于提升泛化能力的重要性。
欠拟合和过拟合的概念比较好理解,造成欠拟合和过拟合的因素有多种多样的,两者的共性都是具有较差的泛化能力。本次通过模型选择的方法来显示泛化能力。
- 使用三阶段多项式来创造样本
import gluonbook as gb
from mxnet import autograd,nd,gluon
from mxnet.gluon import data as gdata,loss as gloss,nn
%matplotlib inline
#生成数据集
n_train,n_test,true_w,true_b = 100,100,[1.2,-3.4,5.6],5
features = nd.random.normal(scale = 1,shape = (n_train + n_test,1))
plot_features = nd.concat(features,nd.power(features,2),nd.power(features,3))
labels = true_w[0] * plot_features[:,0] + true_w[1] * plot_features[:,1] + true_w[2] * plot_features[:,2] + true_b
labels += nd.random.normal(scale = 0.1,shape = labels.shape)
#定义、训练和测试模型
#定义作图函数
def semilogy(x_vals,y_vals,x_label,y_label,x2_vals = None,y2_vals = None,legend = None,figsize = (3.5,2.5)):
gb.set_figsize(figsize)
gb.plt.xlabel(x_label)
gb.plt.ylabel(y_label)
gb.plt.semilogy(x_vals,y_vals)
if x2_vals and y2_vals:
gb.plt.semilogy(x2_vals,y2_vals)
gb.plt.legend(legend)
num_epochs,loss = 100,gloss.L2Loss()
def fit_and_plot(train_features,test_features,train_labels,test_labels):
net = nn.Sequential()
net.add(nn.Dense(1))
net.initialize()
batch_size = min(10,train_labels.shape[0])
train_iter = gdata.DataLoader(gdata.ArrayDataset(train_features,train_labels),batch_size,shuffle = True)
trainer = gluon.Trainer(net.collect_params(),'sgd',{'learning_rate':0.01})
train_ls,test_ls = [],[]
for epoch in range(num_epochs):
for X,y in train_iter:
with autograd.record():
l = loss(net(X),y)
l.backward()
trainer.step(batch_size) #以batch_size为大小进行sgd迭代,得到w,b值
train_ls.append(loss(net(train_features),train_labels).mean().asscalar())
test_ls.append(loss(net(test_features),test_labels).mean().asscalar())
print('final epoch :train loss',train_ls[-1],'test loss:',test_ls[-1])
semilogy(range(1,num_epochs + 1),train_ls,'epochs','loss',range(1,num_epochs+1),test_ls,['train','test'])
print('weight:',net[0].weight.data().asnumpy(),'\nbias:',net[0].bias.data().asnumpy()) #提取net[0]层的weights和bias
fit_and_plot(plot_features[:n_train,:],plot_features[n_train:,:],labels[:n_train],labels[n_train:])
结果:
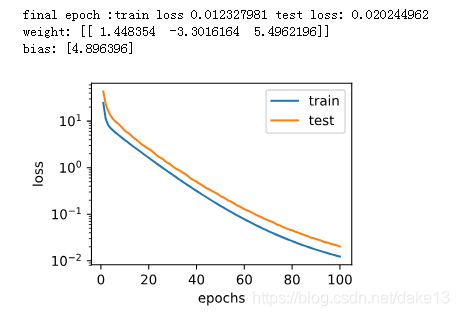
- 使用线性函数来拟合
#试试 线性拟合
fit_and_plot(features[:n_train,:],features[n_train:,:],labels[:n_train],labels[n_train:])
#该模型的训练误差在最初的几次迭代后会快速降低并很难继续降低,即使完成最后的迭代其loss依旧很高,欠拟合。
结果:
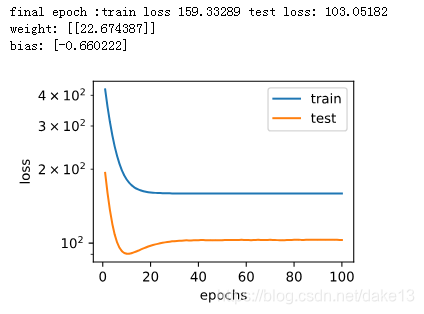
- 当训练量不足时候
# 训练量不足时候,只是用两个样本点
fit_and_plot(plot_features[:2,:],plot_features[n_train:,:],labels[:2],labels[n_train:])
#从图中看到,训练损失比较小,而测试损失比较大,这是典型的过拟合情况,其原因是当训练量比较小时(只有两个样本),取用三阶多项式过于复杂,噪音影响较大,产生过拟合现象
结果:
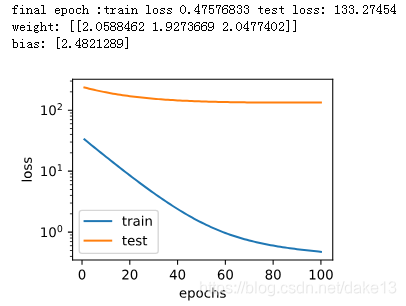
小计:
1)nd.concat(x, y, dim=0),nd.concat(x, y, dim=1) :(当dim不输入时,按照dim = 1处理)

注意与pd.concat的不同:df1、df2、df3等是以一个list传入,默认axis = 0
pd.concat([df1,df2,df3],axis = 0,ignore_index = True) #最后一个参数ignore_index为对行号进行操作


















 638
638

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









