










hadoop简介
1、hadoop适用场景
- 适合:大规模数据、流式数据(写一次,读多次);商用硬件
- 不适合:低延时的数据访问;大量的小文件;频繁修改文件(基本就是写一次)
2、hadoop架构
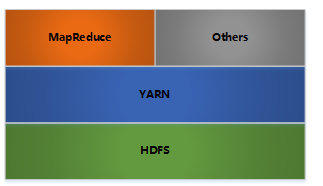
- hdfs:分布式文件存储;
- yarn:分布式资源管理;
- mapreduce:分布式计算;
- others:利用yarn的资源管理功能实现其他的数据处理方式。
3、hdfs
3.1、简介
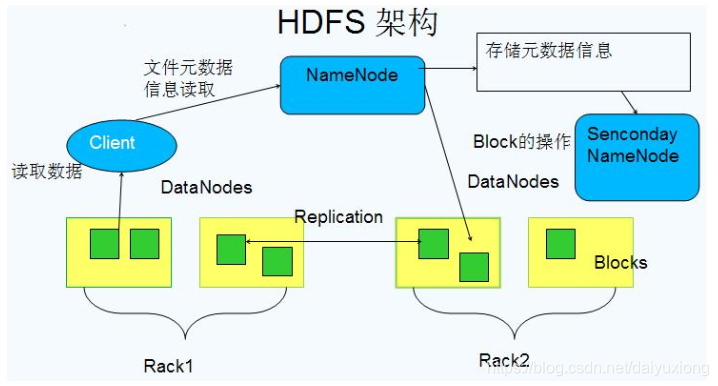
- 分布式文件系统
Block数据: - 基本存储单位,一般大小为64M。配置大的块主要是因为:1、减少搜寻时间,一般硬盘传输速率比寻道时间要快,大的块可以减少寻道事件;2、减少管理块的数据开销,每个块都需要在NameNode上有对应的记录;3、对数据块进行读写,减少建立网络的连接成本;
- 一个大文件会被拆分为一个个的块存储于不同的机器,如果一个文件小于Block的大小,那么实际占用的空间为其文件的大小;
- 基本的读写每次都是读写一个块;
- 每个块都会被复制到多台机器,默认复制3份。
NameNode
- 存储文件的metadata(元数据信息),运行时所有数据都保存到内存,整个hdfs可存储的文件数受限于NameNode的内存大小。
- 一个Block在NameNode中对应一条记录,如果是大量的小文件,则会消耗大量的内存。
- 数据会定时保存到本地磁盘,但是不保存block的位置信息,而是由DataNode注册时上报和运行时维护;
- NameNode失效则整个hdfs失效,所以要保证NameNode可用性。
Secondary NameNode
- 定时与NameNode进行同步,但是NameNode失效后仍然需要手动将其置为主机。
DataNode
- 保存具体的Block数据
- 负责数据的读写操作和复制操作
- DataNode启动时会向NameNode报告当前存储的数据块信息,后续也会定时报告修改信息
- DataNode之间会进行通信,复制数据块,保证数据的冗余性。
块
- 一般用户数据存储在hdfs文件。在一个文件系统中的文件将被划分为一个或多个段/或存在个人数据的节点。这些文件段被称为块。
- HDFS可以读取或写入的最小量被称为一个块。缺省的块大小为64MB,但它可以增加按需要在hdfs配置来改变。
HDFS的目标
- 故障检测和恢复:由于hdfs包括大量的普通硬件,部件故障频繁。因此hdfs具有快速和自动故障检测和恢复机制。
- 巨大的数据集:hdfs有数百个集群节点来管理其庞大的数据集的应用程序。
- 数据硬件:请求的任务,当计算发生不就得数据可以高效地完成。涉及巨大的数据集特别是它减少了网络通信量,增加了吞吐量。
4、hadoop可靠性
- DataNode可以失效,DataNode会定时发送心跳到NameNode,若一定时间内NameNode没有收到DataNode的心跳消息,则认为其失效。此时NameNode会将该节点的数据复制到另外的DataNode中
- 数据可以毁坏。无论是写入时还是硬盘本身的问题,只要数据有问题,都可以通过其他的复制节点读取,同时还会再复制一份到健康的节点中。
- NameNode不可靠
5、Hadoop YARN
5.1、YARN结构
- ResourceManager:全局资源管理和任务调度
- NodeManager:单个节点的资源管理和监控
- ApplicationMaster:单个作业的资源管理和人物监控
- Container:资源申请的单位和任务运行的容器
6、ResourceManager
- 负责全局的资源管理和任务调度。
6.1、资源管理
7、MapReduce
- 一种分布式的计算方式指定一个Map函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce函数,用来保证所有映射的键值对中每一个共享相同的键组。
8、IO
8.1、步骤
- 输入文件从hdfs进行读取
- 输出文件会存入本地磁盘
- Reducer和Mapper间的网络I/O,从Mapper节点得到Reducer的检索文件
- 使用Reducer实例从本地磁盘回读数据
- Reducer输出-回传到HDFS
8.2、串行化
- 传输、存储都需要
- Writable接口
- Avro框架:IDL
8.3、压缩
- 能够减少磁盘的占用空间和网络传输的量
8.4、完整性
- 磁盘和网络很容易出错,保证数据传输的完整性一般通过CRC32这种校验方法;
- 每次写数据到磁盘前都验证一下,同时保存校验码;
- 每次读取数据时,也验证校验码,避免磁盘问题。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









