




 本文详细解析了RocketMQ中负载均衡算法的实现原理,重点介绍了范围平均算法与轮询平均算法,展示了不同算法如何实现消息队列的均衡分配。
本文详细解析了RocketMQ中负载均衡算法的实现原理,重点介绍了范围平均算法与轮询平均算法,展示了不同算法如何实现消息队列的均衡分配。
负载均衡算法是消息系统中不可缺少的算法策略,看过Rocketmq的消费者负载均衡实现后,发现在设计和实现上非常巧妙,所以今天我们将它记录下来,和大家一起分享,也希望对大家有些帮助。
|什么是负载均衡技术呢?
负载均衡,英文名称为Load Balance,其含义就是指将负载(工作任务)进行平衡、分摊到多个操作单元上进行运行,例如FTP服务器、Web服务器、企业核心应用服务器和其它主要任务服务器等,从而协同完成工作任务。
我们可以简单理解成,在计算机领域负载均衡技术是为了最大化让计算机资源分配更加合理,最终目的是为了资源合理利用。
在Rocketmq中,有两个地方需要使用到负载均衡技术:
1、生产者发送消息
为了让消息均衡发送到broker中的queue中
2、消费者消费消息(本文着重分析的内容)
为了让消息均衡分配给不同的消费线程
上文分析过Rocketmq消费者消息流程,其中消息过程中最重要的一步就是通过负载均衡算法获取到当前消费者需要准备拉取消息的目标MessageQueue,如下图第2步。

Rocketmq消费者消费负载均衡实现在消费者客户端实现。位于
org.apache.rocketmq.client.consumer.rebalance包,包括按最近机房,范围平均,轮训平均等负载算法实现,默认使用平均算法(AllocateMessageQueueAveragely)。
本文将主要分析averagely和averagelyByCircle算法,为了说明这两种分配算法的分配规则,现在对 16 个队列,进行编号,用 q0~q15 表示, 消费者用 c0~c2 表示。
1、averagely-范围平均算法
AllocateMessageQueueAveragely分配算法的队列负载机制如下:
c0:q0 q1 q2 q3 q4 q5
c1: q6 q7 q8 q9 q10
c2: q11 q12 q13 q14 q15
其算法的特点是用总数除以消费者个数,余数按消费者顺序分配给消费者,故 c0 会多 分配一个队列,而且队列分配是连续的
范围平均算法实现如下:
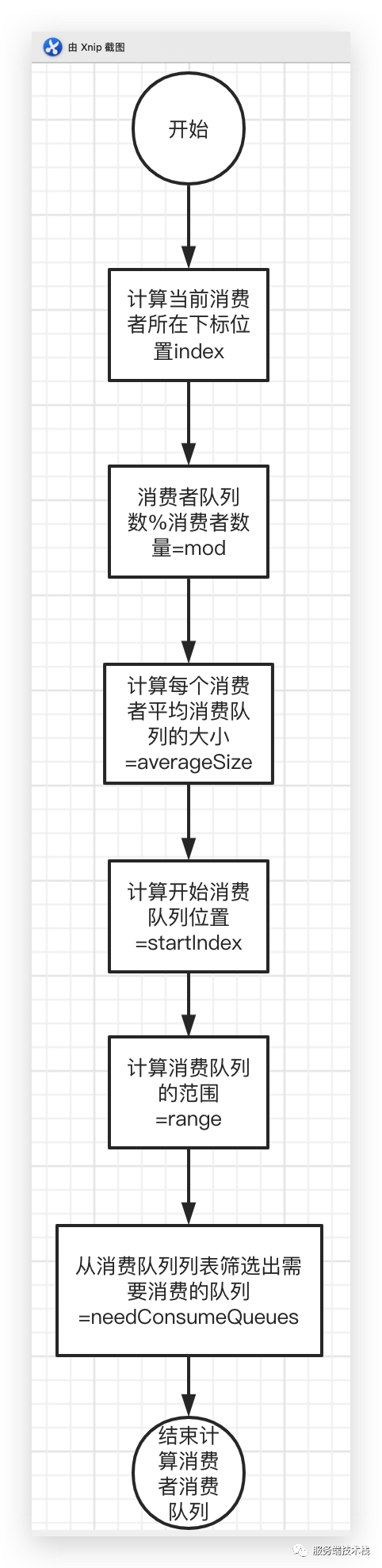
//消费者数量List<String> cidAll = new ArrayList<>();cidAll.add("126");cidAll.add("127");cidAll.add("128");cidAll.add("129");cidAll.add("130");String currentCID = "130";int index = cidAll.indexOf(currentCID);//消息队列数量List<String> mqAll = new ArrayList<>();mqAll.add("1");mqAll.add("2");mqAll.add("3");mqAll.add("4");List<String> needConsumeQueues = new ArrayList<>();// 消息队列%消费者 消息队列数是否能够正好整数倍分配完整int mod = mqAll.size() % cidAll.size();//平均每个消费者消费的队列大小int averageSize = 0;//计算当前消费者需要消费的队列大小//如果需要消费的队列数 小于 消费者数量 则每个(编号小于队列编号的)消费者需要消费1个队列if (mqAll.size() <= cidAll.size()) {averageSize = 1;} else {//如果队列不能被正好整数被分配完,并且当前消费者属于需要比整数个消费多一个if (mod > 0 && index < mod) {averageSize = mqAll.size() / cidAll.size() + 1;} else {//如果队列不能被正好整数被分配完,并且当前消费者不需要比整数个消费多一个(当前消费者消费队列数不加1),刚好消费整数个averageSize = mqAll.size() / cidAll.size();}}// int averageSize =// mqAll.size() <= cidAll.size() ? 1 : (mod > 0 && index < mod ? mqAll.size() / cidAll.size()// + 1 : mqAll.size() / cidAll.size());//计算消费者需要开始消费的队列下标。int startIndex;//消费者不能正好整数倍消费完成,并且需要多消费一个队列的情况下 比如是第3个消费者 平均大小是1 则开始位置是2*1=2if (mod > 0 && index < mod) {//计算当前消费者的 需要消费队列大小startIndex = index * averageSize;} else {// 总共3个队列 2个消费者 mod = 1 则第2个消费者的开始位置为 1*1 + 1 = 2// 总共5个队列 3个消费者 mod = 2 则第2个消费者的开始位置为 2*1 + 1 = 3startIndex = index * averageSize + mod;}//startIndex = (mod > 0 && index < mod) ? index * averageSize : index * averageSize + mod;//消费队列的范围 总共3个队列 2个消费者 mode = 1 则第2个消费者的开始位置为 1*1 + 1 = 2//如果消费者需要消费的数量不会加1 则消费范围为averageSize, 但是也可能存在一个消费者//范围比较 存在一种情况 消费者数量比队列数量多的情况 则存在部分消费者消费不到队列情况,// 则会使得 averageSize=1 但是 (mqAll.size() - startIndex) =0的情况 这样就范围就是0了。int range = Math.min(averageSize, mqAll.size() - startIndex);for (int i = 0; i < range; i++) {//按范围获取队列,保证连续性质 比如5个消息队列 3个消费者 第2个消费者从第2个消息队列needConsumeQueues.add(mqAll.get((startIndex + i) % mqAll.size()));}
流程图如下:
2、averagelyByCircle-轮询平均算法
AllocateMessageQueueAveragelyByCircle分配算法的队列负载机制如下:
c0:q0 q3 q6 q9 q12 q15
c1: q1 q4 q7 q10 q13
c2: q2 q5 q8 q11 q14
该分配算法的特点就是轮流一个一个分配。
算法核心实现:
@Overridepublic List<MessageQueue> allocate(String consumerGroup, String currentCID, List<MessageQueue> mqAll,List<String> cidAll) {if (currentCID == null || currentCID.length() < 1) {throw new IllegalArgumentException("currentCID is empty");}if (mqAll == null || mqAll.isEmpty()) {throw new IllegalArgumentException("mqAll is null or mqAll empty");}if (cidAll == null || cidAll.isEmpty()) {throw new IllegalArgumentException("cidAll is null or cidAll empty");}List<MessageQueue> result = new ArrayList<MessageQueue>();if (!cidAll.contains(currentCID)) {log.info("[BUG] ConsumerGroup: {} The consumerId: {} not in cidAll: {}",consumerGroup,currentCID,cidAll);return result;}int index = cidAll.indexOf(currentCID);for (int i = index; i < mqAll.size(); i++) {//队列索引号与消费者总数取模 非常巧妙的实现轮询负载算法功能if (i % cidAll.size() == index) {result.add(mqAll.get(i));}}return result;}
温馨提示:如果 topic 的队列个数小于消费者的个数,那有些消费者无法分配到消息。在 RocketMQ 中一个 topic 的队列数直接决定了最大消费者的个数,但 topic 队列个数的 增加对 RocketMQ 的性能不会产生影响。在实际过程中,对主题进行扩容(增加队列个数)或者对消费者进行扩容、缩容是一件非 常寻常的事情,那如果新增一个消费者,该消费者消费哪些队列呢?这就涉及到消息消费队 列的重新分配,即消费队列重平衡机制。
在 RocketMQ 客户端中会每隔 20s 去查询当前 topic 的所有队列、消费者的个数,运用队列负载算法进行重新分配,然后与上一次的分配结果进行对比,如果发生了变化,则进行队列重新分配;如果没有发生变化,则忽略。例如采取的分配算法如下图所示,现在增加一个消费者 c3,那队列的分布情况是怎样的呢?
假如采用平均分配算法,重分配前的队列分配情况如下:
c0:q0 q1 q2 q3 q4 q5
c1: q6 q7 q8 q9 q10
c2: q11 q12 q13 q14 q15
根据新的分配算法,其队列最终的情况如下:
c0:q0 q1 q2 q3
c1: q4 q5 q6 q7
c2: q8 q9 q10 q11
c3: q12 q13 q14 q15
上述整个过程无需应用程序干预,由 RocketMQ 完成。大概的做法就是将原先分配给自己但这次不属于的队列进行丢弃,新分配的队列则创建新的拉取任务。(源码确实是如此实现的)
负载重平衡源码实现:
private boolean updateProcessQueueTableInRebalance(final String topic, final Set<MessageQueue> mqSet,final boolean isOrder) {boolean changed = false;Iterator<Entry<MessageQueue, ProcessQueue>> it = this.processQueueTable.entrySet().iterator();while (it.hasNext()) {Entry<MessageQueue, ProcessQueue> next = it.next();MessageQueue mq = next.getKey();ProcessQueue pq = next.getValue();if (mq.getTopic().equals(topic)) {//新分配的队列不包括原来分配的队列,需要移除原来的队列if (!mqSet.contains(mq)) {pq.setDropped(true);if (this.removeUnnecessaryMessageQueue(mq, pq)) {//移除当前消费者不需要的拉取队列it.remove();changed = true;log.info("doRebalance, {}, remove unnecessary mq, {}", consumerGroup, mq);}} else if (pq.isPullExpired()) {switch (this.consumeType()) {case CONSUME_ACTIVELY:break;case CONSUME_PASSIVELY:pq.setDropped(true);if (this.removeUnnecessaryMessageQueue(mq, pq)) {it.remove();changed = true;log.error("[BUG]doRebalance, {}, remove unnecessary mq, {}, because pull is pause, so try to fixed it",consumerGroup, mq);}break;default:break;}}}}List<PullRequest> pullRequestList = new ArrayList<PullRequest>();for (MessageQueue mq : mqSet) {if (!this.processQueueTable.containsKey(mq)) {if (isOrder && !this.lock(mq)) {log.warn("doRebalance, {}, add a new mq failed, {}, because lock failed", consumerGroup, mq);continue;}this.removeDirtyOffset(mq);ProcessQueue pq = new ProcessQueue();long nextOffset = this.computePullFromWhere(mq);if (nextOffset >= 0) {//判断消费队列是否已经存在ProcessQueue pre = this.processQueueTable.putIfAbsent(mq, pq);if (pre != null) {log.info("doRebalance, {}, mq already exists, {}", consumerGroup, mq);} else {log.info("doRebalance, {}, add a new mq, {}", consumerGroup, mq);PullRequest pullRequest = new PullRequest();pullRequest.setConsumerGroup(consumerGroup);pullRequest.setNextOffset(nextOffset);pullRequest.setMessageQueue(mq);pullRequest.setProcessQueue(pq);//将新分配的队列加入到拉取请求队列中pullRequestList.add(pullRequest);changed = true;}} else {log.warn("doRebalance, {}, add new mq failed, {}", consumerGroup, mq);}}}//为新消费队列加入到拉取请求队列,后续通过线程池拉取消息this.dispatchPullRequest(pullRequestList);return changed;}
Rocketmq消费者的负载均衡实现就分析到这了,后续继续深入学习Rocketmq。


















 1315
1315

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











