




 本文探讨了在线学习的概念,对比了GD与SGD算法,介绍了OGD算法及其优势。深入讨论了稀疏解的重要性,特别是在高维特征向量及大数据集中的应用。通过L1正则化、简单截断法、梯度截断法、FOBOS、RDA和FTRL算法,详细分析了获取稀疏解的不同策略。
本文探讨了在线学习的概念,对比了GD与SGD算法,介绍了OGD算法及其优势。深入讨论了稀疏解的重要性,特别是在高维特征向量及大数据集中的应用。通过L1正则化、简单截断法、梯度截断法、FOBOS、RDA和FTRL算法,详细分析了获取稀疏解的不同策略。
在线学习
由于数据量比较大,可能已经超出了内存的大小,此时无法将数据全部装入到内存中参与计算,主要有两种方法处理大数据问题:
1.在很多机器上并行批学习(本文不涉及)
2.利用流式的在线学习
GD算法
- GD算法

- SGD算法

与SGD比较,GD需要每次扫描所有的样本以计算一个全局梯度,SGD则每次只针对一个观测到的样本进行更新。通常情况下SGD可以更快的逼近最优值,而且SGD每次更新只需要一个样本,使得它很适合进行增量或者在线计算(也就是所谓的Online learning)。 - OGD
Online Learning强调学习的实时性,流式的,每次训练不用全部样本,而是根据训练好的模型,每来一个样本更新一次模型,这种方法叫做OGD(Online Gradient Descent)
在线梯度下降只知道当前一个数据所得到的有偏差的梯度,对别的项的减少程度是未知的,可能会走点弯路。其优势在于每步是需要看一下当前的一个数据,代价很小。
稀疏解
迭代和选取模型的时候我们经常希望得到更加稀疏的模型,这不仅仅起到了特征选择的作用,也降低了预测计算的复杂度。在实际使用LR的时候我们会使用L1或者L2正则,避免模型过拟合和增加模型的鲁棒性。在GD算法下,L1正则化通常能得到更加稀疏的解;可是在SGD算法下模型迭代并不是沿着全局梯度下降,而是沿着某个样本的梯度进行下降,这样即使是L1正则也不一定能得到稀疏解。
TG算法
1.L1正则化法
由于L1正则项在0处不可导,往往会造成平滑的凸优化问题变成非平滑的凸优化问题,因此可以采用次梯度(Subgradient)来计算L1正则项的梯度。权重更新方式为:
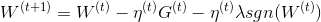
其中
λ
≥
0
\lambda\ge0
λ≥0是一个标量,为L1正则化的参数;
s
g
n
(
x
)
sgn(x)
sgn(x)为符号函数;
η
(
t
)
\eta^{(t)}
η(t)称为学习率;
G
(
t
)
=
∇
W
l
(
W
(
t
)
,
Z
(
t
)
)
G^{(t)}=\nabla_Wl(W^{(t)},Z^{(t)})
G(t)=∇Wl(W(t),Z(t))代表第
t
t
t次迭代中损失函数的梯度。
次梯度方法不能得到稀疏解,为0的结果太少了。
次梯度概念参考:https://blog.youkuaiyun.com/qq_32742009/article/details/81704139
2.简单截断法
既然L1正则化在Online模式下也不能产生更好的稀疏性,而稀疏性对于高维特征向量以及大数据集又特别的重要,我们应该如何处理呢?
简单粗暴的方法是设置一个阀值,当W的某纬度的系数小于这个阀值的时候,将其直接设置为0。这样我们就得到了简单截断法。权重更新方式如下:
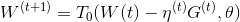
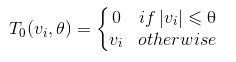
θ
\theta
θ是一个正数
3.梯度截断法
简单截断法法简单且易于理解,但是在实际训练过程中的某一步,W的某个特征系数可能是因为该特征训练不足引起的,简单的截断过于简单粗暴(too aggresive),会造成该特征的缺失。那么我们有没有其他的方法,使得权重的归零和截断处理稍微温柔一些呢?对,这就是梯度截断法,简单截断法和梯度截断法对特征权重的处理映射图对比如下:
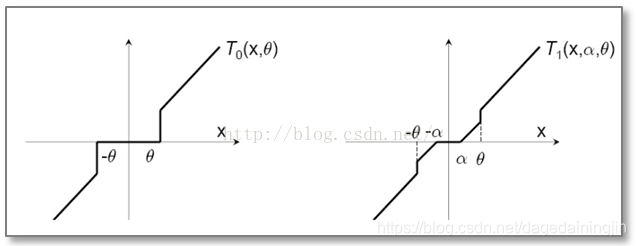
梯度截断法的迭代公式如下:
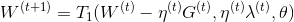
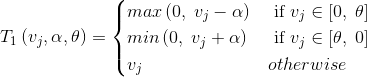
梯度截断法满足适当条件可退化为简单截断法或L1正则化法
FOBOS算法
FOBOS(Forward-Backward Splitting)算法把正则化的梯度下降问题分成一个经验损失梯度下降迭代和一个最优化问题。其中第二个最优化问题有两项:第一项2范数那项表示不能离loss损失迭代结果太远,第二项是正则化项,用来限定模型复杂度、抑制过拟合和做稀疏化等。
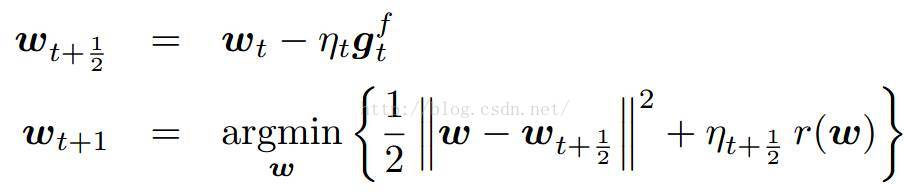
L1-FOBOS是TG在特定条件下的特殊形式
RDA算法
之前的算法都是在SGD的基础上,属于梯度下降类型的方法,这类型的方法的优点是精度比较高,并且TG、FOBOS也能在稀疏性上得到提升。但是RDA却从另一个方面进行在线求解,并且有效提升了特征权重的稀疏性。(对梯度的重新构造)
在RDA中,特征权重的更新策略包含一个梯度对
W
W
W的积分平均值,正则项和一个辅助的严格凸函数。具体为:

其中
⟨
G
(
t
)
,
W
⟩
\langle G^{(t)},W\rangle
⟨G(t),W⟩表示梯度
G
G
G对
W
W
W的积分平均值,包含了之前所有梯度的平均值;
Ψ
(
W
)
\Psi(W)
Ψ(W)为正则化项,
β
(
t
)
t
h
(
W
)
\frac{\beta^{(t)}}{t}h(W)
tβ(t)h(W)表示一个非负且非自减序列,是一个严格的凸函数。
L1-FOBOS的“截断阈值”为
Θ
(
1
t
)
λ
\Theta(\frac{1}{\sqrt{t}})\lambda
Θ(t1)λ,随着
t
t
t的增加,这个阈值会逐渐降低。相比较而言,L1-RDA的“截断阈值”为
λ
\lambda
λ,是一个常数,并不随着
t
t
t而变化,因此可以认为L1-RDA比L1-FOBOS在截断判定上更加aggressive,这种性质使得L1-RDA更容易产生稀疏性;RDA中判定对象是梯度的累加平均值,不同于TG或L1-FOBOS中针对单次梯度计算的结果进行判定,避免了某些维度由于训练不足导致截断的问题。
参考:https://www.cnblogs.com/luctw/p/4757943.html
FTRL算法
有实验证明,L1-FOBOS这一类基于梯度下降的方法有较高的精度,但是L1-RDA却能在损失一定精度的情况下产生更好的稀疏性。如何能把这两者的优点同时体现出来的呢?这就是FTRL
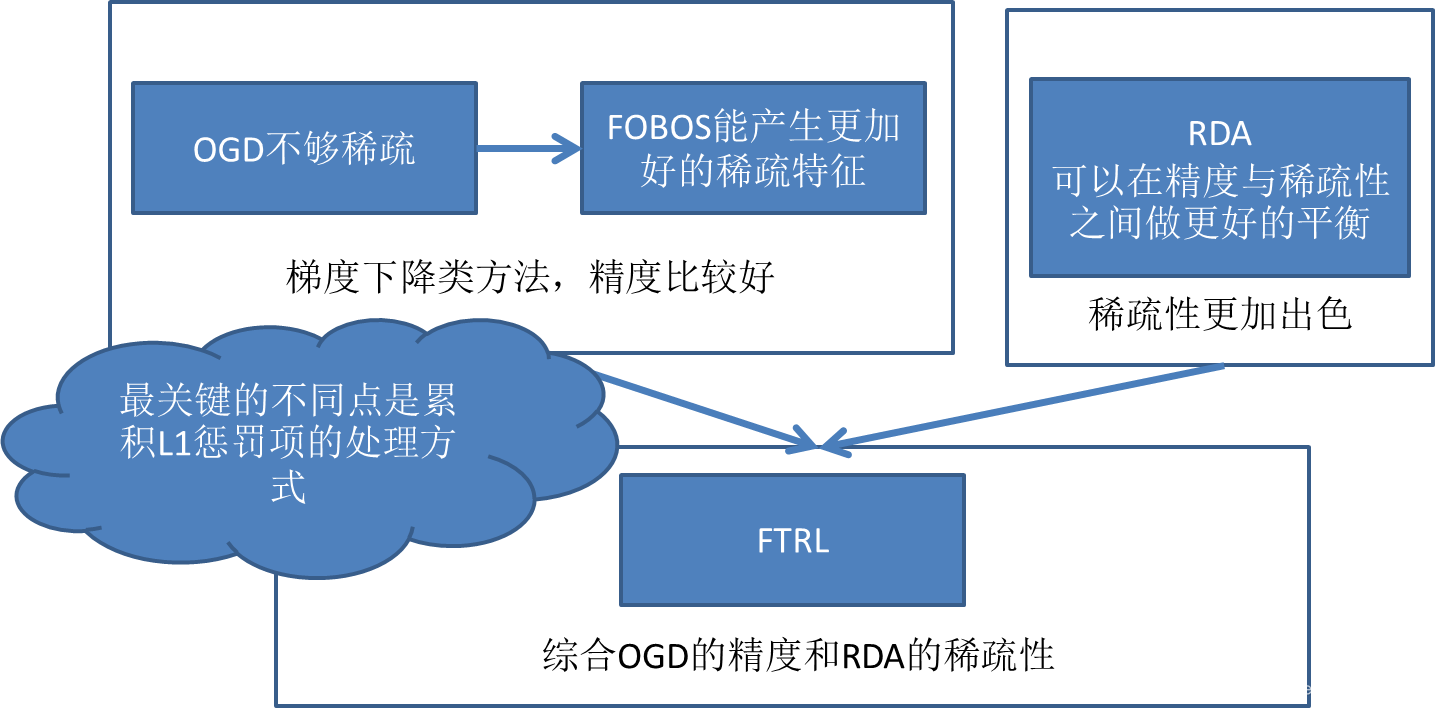
参考:https://blog.youkuaiyun.com/dengxing1234/article/details/73277251

















 1276
1276

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









