




 本文深入剖析了ArrayList的内部结构、构造方法、主要方法及优缺点。详细介绍了ArrayList的序列化过程、扩容机制以及各种操作方法,帮助读者全面理解ArrayList的工作原理。
本文深入剖析了ArrayList的内部结构、构造方法、主要方法及优缺点。详细介绍了ArrayList的序列化过程、扩容机制以及各种操作方法,帮助读者全面理解ArrayList的工作原理。
注:本文所有方法和示例基于jdk1.8
简介
ArrayList是我们开发中非常常用的数据存储容器之一,其底层是数组实现的,我们可以在集合中存储任意类型的数据(包括null),ArrayList是线程不安全的,非常适合用于对元素进行查找,效率非常高。
1.属性
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
{
private static final long serialVersionUID = 8683452581122892189L;
/**
* 默认初始化容量
*/
private static final int DEFAULT_CAPACITY = 10;
/**
* 如果自定义容量为0,则会默认用它来初始化ArrayList。或者用于空数组替换。
*/
private static final Object[] EMPTY_ELEMENTDATA = {};
/**
* 如果没有自定义容量,则会使用它来初始化ArrayList。或者用于空数组比对。
*/
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
/**
* 存储ArrayList元素的数组缓冲区。
* ArrayList的容量是此数组缓冲区的长度。 任何如DEFAULTCAPACITY_EMPTY_ELEMENTDATA的
* 空ArrayList添加第一元素后,该容量将扩展为DEFAULT_CAPACITY。
* transient 在已经实现序列化的类中,不允许某变量序列化
*/
transient Object[] elementData;
/**
* 实际ArrayList集合大小
*/
private int size;
/**
* 可分配的最大容量
*/
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
扩展:什么是序列化
序列化是指:将对象转换成以字节序列的形式来表示,以便用于持久化和传输。
实现方法:实现Serializable接口。
然后用的时候拿出来进行反序列化即可又变成Java对象。
transient关键字解析
Java中transient关键字的作用,简单地说,就是让某些被修饰的成员属性变量不被序列化。
有了transient关键字声明,则这个变量不会参与序列化操作,即使所在类实现了Serializable接口,反序列化后该变量为空值。
那么问题来了:ArrayList中数组声明:
transient Object[] elementData;,事实上我们使用ArrayList在网络传输用的很正常,并没有出现空值。
原来:ArrayList在序列化的时候会调用writeObject()方法,将size和element写入ObjectOutputStream;反序列化时调用readObject(),从ObjectInputStream获取size和element,再恢复到elementData。
那为什么不直接用elementData来序列化,而采用上述的方式来实现序列化呢?
原因在于elementData是一个缓存数组,它通常会预留一些容量,等容量不足时再扩充容量,那么有些空间可能就没有实际存储元素,采用上诉的方式来实现序列化时,就可以保证只序列化实际存储的那些元素,而不是整个数组,从而节省空间和时间。
2.构造方法
2.1指定容量的ArrayList
/**
* 根据initialCapacity 初始化一个数组
*/
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
2.2不带参数初始化,默认容量为10:
/**
* 不带参数初始化,默认容量为10
*/
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
2.3通过集合做参数的形式初始化:如果集合为空,则初始化为空数组:
/**
* 通过集合做参数的形式初始化
*/
public ArrayList(Collection<? extends E> c) {
elementData = c.toArray();
if ((size = elementData.length) != 0) {
// c.toArray might (incorrectly) not return Object[] (see 6260652)
if (elementData.getClass() != Object[].class)
elementData = Arrays.copyOf(elementData, size, Object[].class);
} else {
// replace with empty array.
this.elementData = EMPTY_ELEMENTDATA;
}
}
3.主要方法
trimToSize()用来最小化实例存储,将容器大小调整为当前元素所占用的容量大小。
/**
* 这个方法用来最小化实例存储。
*/
public void trimToSize() {
modCount++;
if (size < elementData.length) {
elementData = (size == 0)
? EMPTY_ELEMENTDATA
: Arrays.copyOf(elementData, size);
}
}
通过调用Object的clone()方法来得到一个新的ArrayList对象,然后将elementData复制给该对象并返回
public Object clone() {
try {
ArrayList<?> v = (ArrayList<?>) super.clone();
v.elementData = Arrays.copyOf(elementData, size);
v.modCount = 0;
return v;
} catch (CloneNotSupportedException e) {
// this shouldn't happen, since we are Cloneable
throw new InternalError(e);
}
}
添加元素方法
/**
* 在数组末尾添加元素
*/
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
看到它首先调用了ensureCapacityInternal()方法.注意参数是size+1,这是个面试考点。
private void ensureCapacityInternal(int minCapacity) {
ensureExplicitCapacity(calculateCapacity(elementData, minCapacity));
}
这个方法里又嵌套调用了两个方法:计算容量+确保容量
计算容量:如果elementData是空,则返回默认容量10和size+1的最大值,否则返回size+1
private static int calculateCapacity(Object[] elementData, int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
return Math.max(DEFAULT_CAPACITY, minCapacity);
}
return minCapacity;
}
计算完容量后,进行确保容量可用:(modCount不用理它,它用来计算修改次数)
如果size+1 > elementData.length证明数组已经放满,则增加容量,调用grow()。
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
增加容量:默认1.5倍扩容。
-
获取当前数组长度=>oldCapacity
-
oldCapacity>>1 表示将oldCapacity右移一位(位运算),相当于除2。再加上1,相当于新容量扩容1.5倍。
-
如果
newCapacity>1=1,1<2所以如果不处理该情况,扩容将不能正确完成。 -
如果新容量比最大值还要大,则将新容量赋值为VM要求最大值。
5.将elementData拷贝到一个新的容量中。
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
size+1的问题
好了,那到这里可以说一下为什么要size+1。
size+1代表的含义是:
-
如果集合添加元素成功后,集合中的实际元素个数。
-
为了确保扩容不会出现错误。
假如不加一处理,如果默认size是0,则0+0>>1还是0。
如果size是1,则1+1>>1还是1。有人问:不是默认容量大小是10吗?事实上,jdk1.8版本以后,ArrayList的扩容放在add()方法中。之前放在构造方法中。我用的是1.8版本,所以默认ArrayList arrayList = new ArrayList();后,size应该是0.所以,size+1对扩容来讲很必要.
public static void main(String[] args) {
ArrayList arrayList = new ArrayList();
System.out.println(arrayList.size());
}
输出:0
add(int index, E element)
public void add(int index, E element) {
rangeCheckForAdd(index);
ensureCapacityInternal(size + 1); // Increments modCount!!
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
elementData[index] = element;
size++;
}
rangeCheckForAdd()是越界异常检测方法。ensureCapacityInternal()之前有讲,着重说一下System.arrayCopy方法:
public static void arraycopy(Object src, int srcPos, Object dest, int destPos, int length)
代码解释:
-
Object src : 原数组
-
int srcPos : 从元数据的起始位置开始
-
Object dest : 目标数组
-
int destPos : 目标数组的开始起始位置
-
int length : 要copy的数组的长度
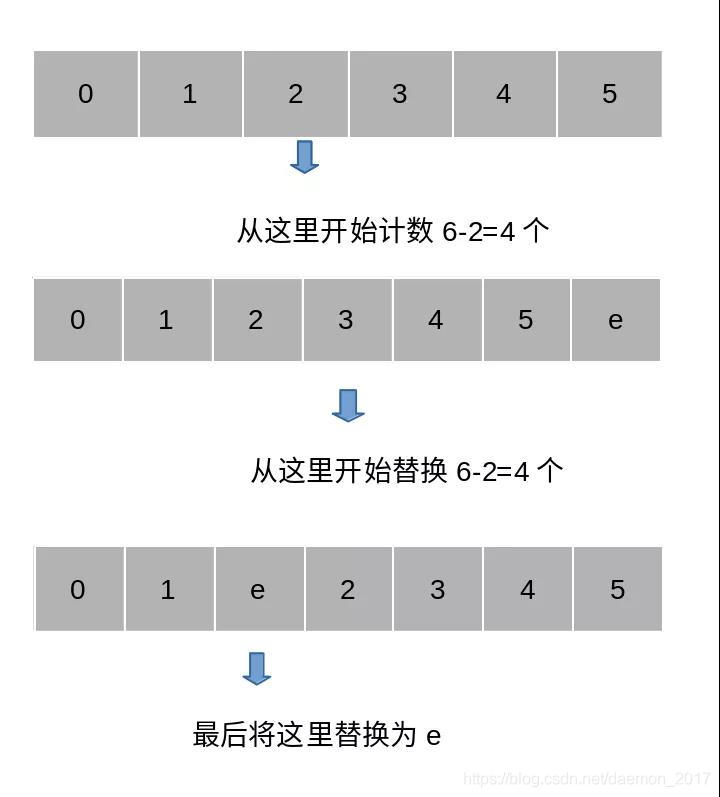
示例:size为6,我们调用add(2,element)方法,则会从index=2+1=3的位置开始,将数组元素替换为从index起始位置为index=2,长度为6-2=4的数据。
异常处理:
private void rangeCheckForAdd(int index) {
if (index > size || index < 0)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
ArrayList优缺点
优点:
-
因为其底层是数组,所以修改和查询效率高。
-
可自动扩容(1.5倍)。
缺点:
-
插入和删除效率不高。
线程不安全。

















 7279
7279

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









