



 本文记录了一次使用Scrapy框架爬取豆瓣Top250电影数据的经历,作者在初次尝试时遇到了AttributeError错误,原因是错误地从requests库中导入了Request类,而非Scrapy。通过将导入语句更正为from scrapy import Request,问题得以解决。
本文记录了一次使用Scrapy框架爬取豆瓣Top250电影数据的经历,作者在初次尝试时遇到了AttributeError错误,原因是错误地从requests库中导入了Request类,而非Scrapy。通过将导入语句更正为from scrapy import Request,问题得以解决。
首次学习scrapy框架来爬取豆瓣Top250,在写完代码执行时,报了AttributeError: ‘Request’ object has no attribute ‘meta’ 还有AttributeError: ‘Request’ object has no attribute ‘dont_filter’ .
执行的代码
# -*- coding: utf-8 -*-
from requests import Request
from scrapy.spiders import Spider
from scrapyspider.items import DoubanMovieItem
class DoubanMovieTop250Spider(Spider):
name = "douban250"
start_urls = ["https://movie.douban.com/top250"]
headers ={
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36'
}
def start_requests(self):
# url = "https://movie.douban.com/top250"
url = 'https://movie.douban.com/top250'
yield Request(url, headers = self.headers)
def parse(self, response):
item = DoubanMovieItem()
movies = response.xpath('//ol[@class="grid_view"]/li')
for movie in movies:
item['ranking'] = movie.xpath(
'.//div[@class="pic"]/em/text()').extract()[0]
item['movie_name'] = movie.xpath(
'.//div[@class="hd"]/a/span[1]/text()').extract()[0]
item['score'] = movie.xpath(
'.//div[@class="star"]/span[@class="rating_num"]/text()'
).extract()[0]
item['score_number'] = movie.xpath(
'.//div[@class="star"]/span/text()').re(u'(\d+)人评价')[0]
yield item
跑完代码cmd出现下面的错误情况:
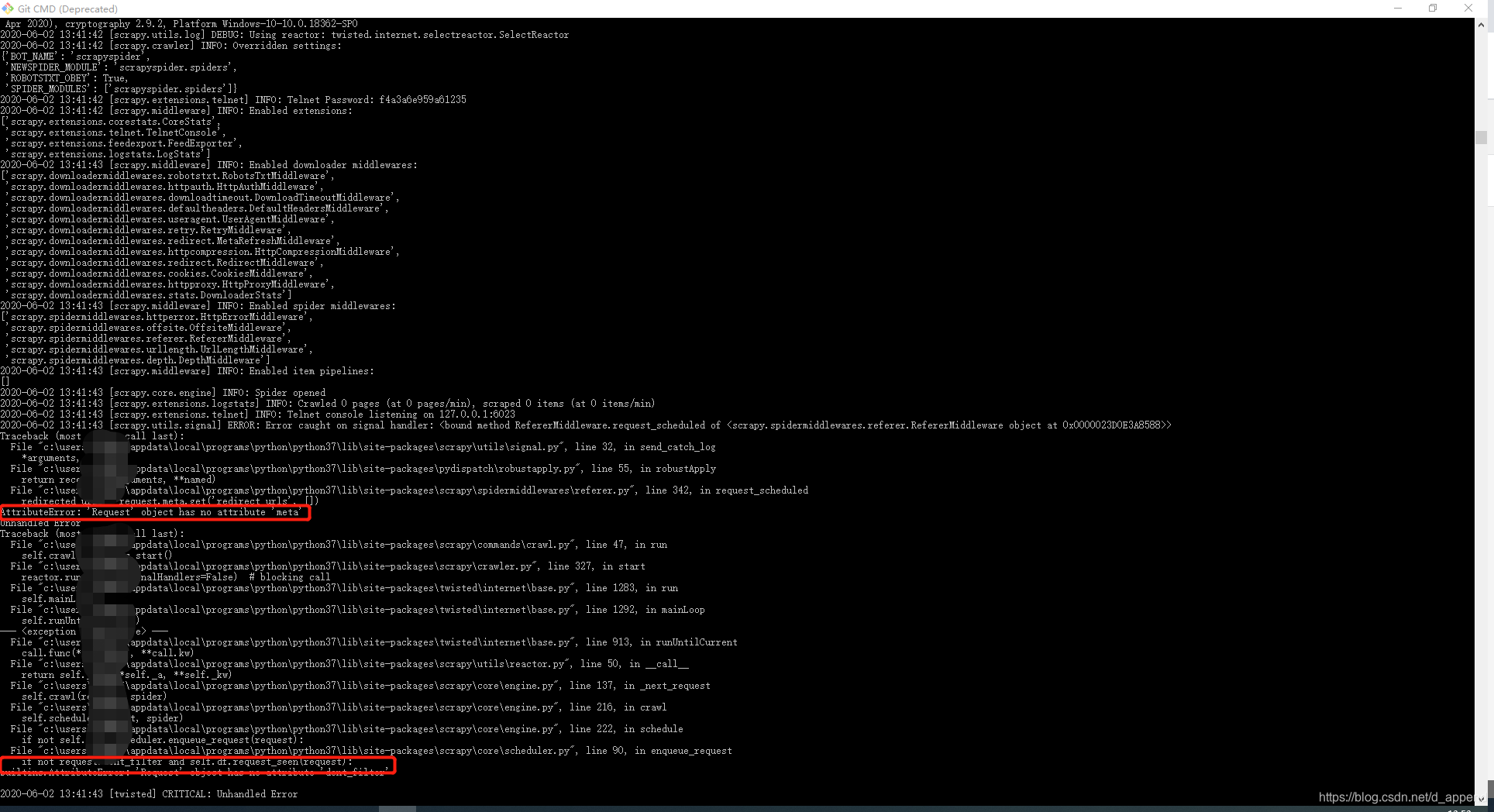
后来经过一番查找才发现原来是因为自己导包错误的问题…
from requests import Request
应该改为
from scrapy import Request
修改完的代码:
from scrapy import Request
from scrapy.spiders import Spider
from scrapyspider.items import DoubanMovieItem
class DoubanMovieTop250Spider(Spider):
name = "douban250"
start_urls = ["https://movie.douban.com/top250"]
headers ={
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36'
}
def start_requests(self):
# url = "https://movie.douban.com/top250"
url = 'https://movie.douban.com/top250'
yield Request(url, headers = self.headers)
def parse(self, response):
item = DoubanMovieItem()
movies = response.xpath('//ol[@class="grid_view"]/li')
for movie in movies:
item['ranking'] = movie.xpath(
'.//div[@class="pic"]/em/text()').extract()[0]
item['movie_name'] = movie.xpath(
'.//div[@class="hd"]/a/span[1]/text()').extract()[0]
item['score'] = movie.xpath(
'.//div[@class="star"]/span[@class="rating_num"]/text()'
).extract()[0]
item['score_number'] = movie.xpath(
'.//div[@class="star"]/span/text()').re(u'(\d+)人评价')[0]
yield item
执行完的成功,cmd是这样的:
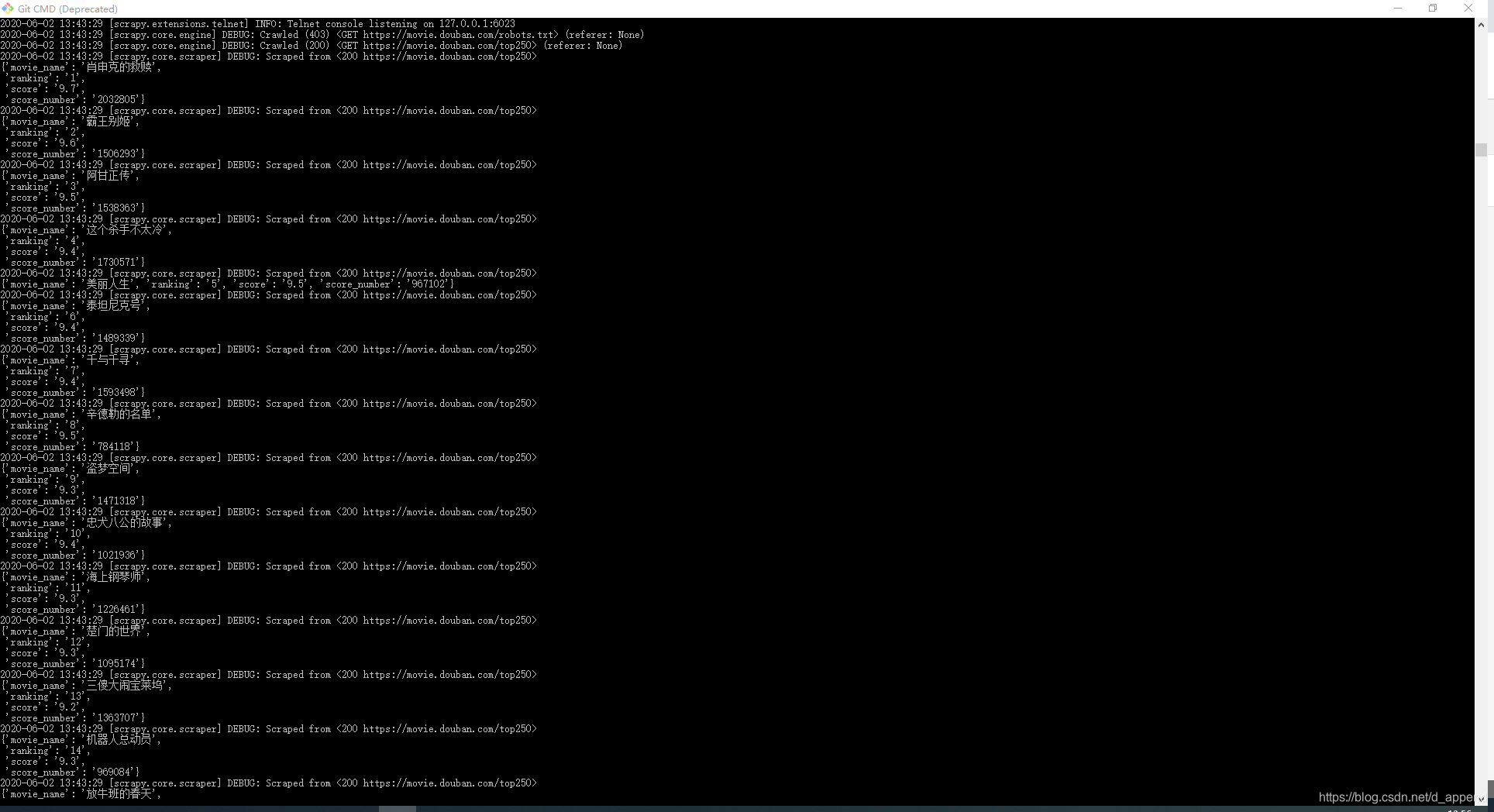
第一次用爬虫框架爬取数据马马虎虎… 记录一下

















 5521
5521

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









