




 文章探讨了Attention机制从早期在计算机视觉的应用到在NLP领域的广泛使用,特别是在Transformer架构中的关键作用。Transformer通过自注意力和多头注意力解决了模型复杂性和计算效率问题。VisualTransformer(ViT)将Transformer引入CV,通过将图像分割为patch并结合位置嵌入进行处理。尽管ViT在大规模数据集上表现优秀,但在中小型数据集上可能不及卷积网络,因为它缺乏CNN的局部性和平移不变性先验知识。
文章探讨了Attention机制从早期在计算机视觉的应用到在NLP领域的广泛使用,特别是在Transformer架构中的关键作用。Transformer通过自注意力和多头注意力解决了模型复杂性和计算效率问题。VisualTransformer(ViT)将Transformer引入CV,通过将图像分割为patch并结合位置嵌入进行处理。尽管ViT在大规模数据集上表现优秀,但在中小型数据集上可能不及卷积网络,因为它缺乏CNN的局部性和平移不变性先验知识。
Attention和Visual Transformer
Attention和Transformer
Attention机制在相当早的时间就已经被提出了,最先是在计算机视觉领域进行使用,但是始终没有火起来。Attention机制真正进入主流视野源自Google Mind在2014年的一篇论文"Recurrent models of visual attention"。在该文当中,首次在RNN上使用了Attention进行图像分类 。
然而,Attention真正得到广泛应用是在NLP领域,大量的方法在RNN/CNN模型上使用Attention机制进行各种任务。在2017年,Google的《Attention is all you need》中首次使用自注意力机制和多头注意力机制进行翻译任务,并提出了Transformer架构,取得了十分优异的性能,成为NLP领域的大爆点。
在2021年,Google Research发布了论文《AN IMAGE IS WORTH 16X16 WORDS:
TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE》,将在NLP领域取得巨大成功的Transformer引入计算机视觉领域,并提出了Visual Transformer架构,其性能接近或超过了此前传统的卷积网络。
为什么需要Attention
在Attention真正得到应用的时候(其实现在也是),神经网络的发展面临着两个问题:
- 计算能力的不足。随着模型的深度和宽度的不断增加,模型需要记住的“知识”越来越多。模型整体会变得愈发复杂,其训练和推理都会对计算能力提出很高的要求。
- 优化算法的限制。池化、BatchNorm和LayerNorm等操作可以让模型的优化变得相对简单容易,但对于高度复杂的模型,目前的优化算法或多或少存在难以优化的问题。比如,在RNN中存在的长程梯度消失问题。在进行机器翻译的时候,将长句子转换为长向量会使得模型变得很难优化,在训练过程中会出现信息损失的问题。
Attention解决以上两个问题的想法是,将模型当中的信息进行权重区分,对重要的部分进行重点关注,而忽略不是那么重要的部分。以一个翻译的例子来说,给出这样一句话
To be or not to be, that is the question.
在进行翻译的时候,对于that这个词的含义,我们显然回去更关注千年的To be or not to be,而不是is或者the。又或者,我们在看一幅图片的时候

我们显然会首先关注照片中的香蕉,进而认为这是一幅香蕉的照片。而非重点关注香蕉下面的桌子,或者后面的背景。
Attention机制的核心思想就是这样。
Attention机制
Attention的实现基于Key-Value的模型。模型的输入作为Query,与Key、Value进行计算后得到一个Attention的结果。比较抽象的图如下面所示
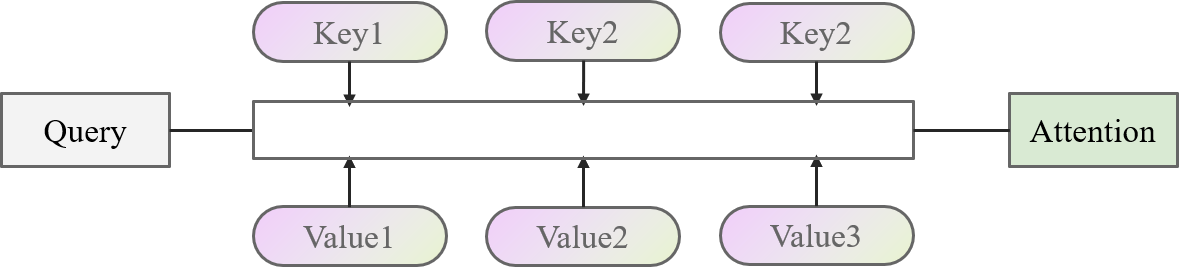
举个简单的例子来说,现在要去图书馆学习深度学习相关的知识,深度学习作为(Query)。在图书馆中,有很多类别(Key)的图书(Value),包括PyTorch与Python、数理统计、微积分、计算机组成原理、数据库等等。这些类别的图书与学习的目标有些很符合(数理统计、PyTorch),有些相关性很小(数据库、计算机组成原理)。那么,一种高效的学习方法就是重点去学习相关性很大的书籍,便可以计算深度学习(Query)和类别(Key)之间的相关性,让后根据相关性的大小学习这些书(Value),最后加起来得到学习到的知识(Attention)。
Attention的核心思想,用“加权求和”四个字就可以概括。大道至简,大爱无疆,大音希声,大象无形。加的权就是Query和Key的相关度(或者交相似性),求得和就是各个Value之间的求和。
基于此,我们再去理解一下上面的图,将上面的图展开一点。
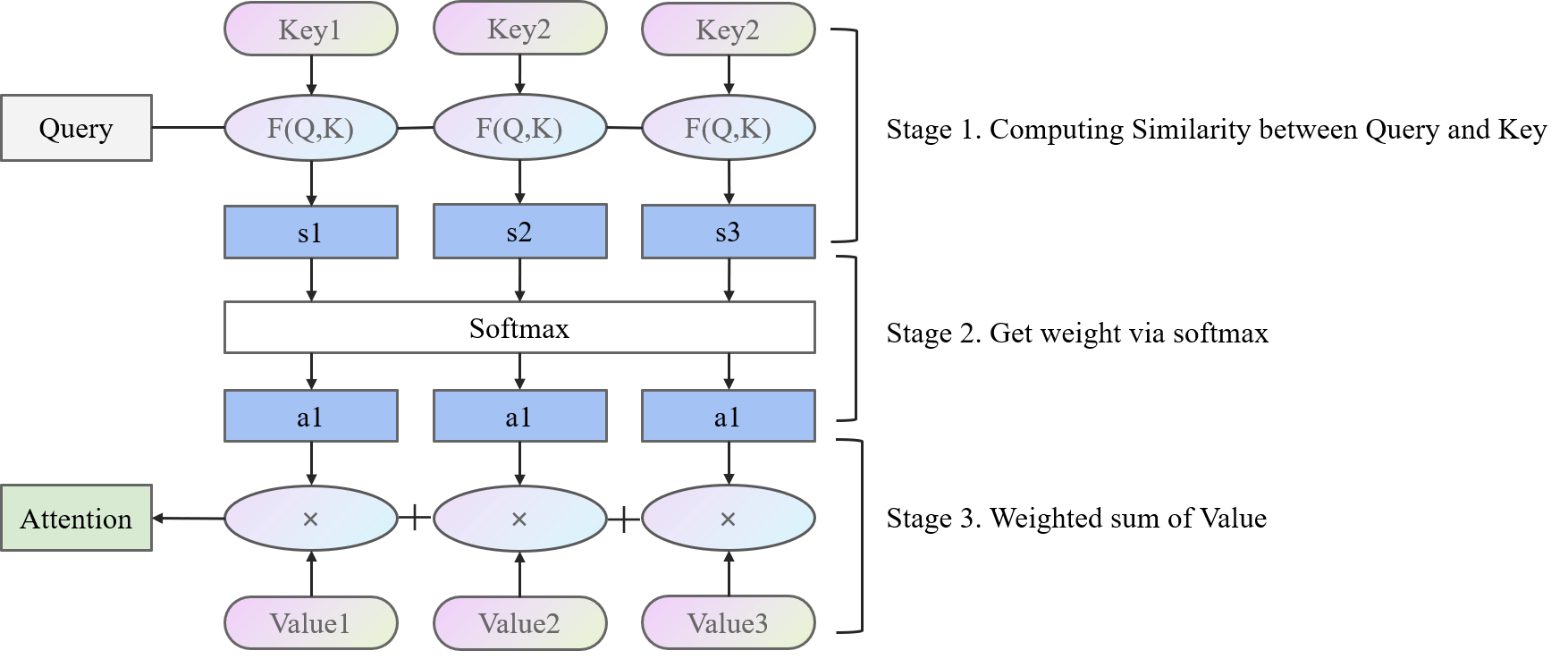
在计算Attention的时候
- 第一阶段用F(Q,K)计算Query和各个Key的相似度
- 第二阶段用softmax操作将相似度变成可以使用的权重
- 第三阶段用对应的权重乘以对应的Value,加起来得到Attention结果。
在《Attention is all you need》这篇文章中,作者给出了一种 Scaled Dot-Product Attention的计算方式。
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K ⊤ d k ) V {\rm Attention}(Q,K,V)=softmax\left( \frac{QK^{\top}}{\sqrt{d_{k}}} \right)V Attention(Q,K,V)=softmax(dk
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 458
458




 到【灌水乐园】发言
到【灌水乐园】发言









