




文章目录
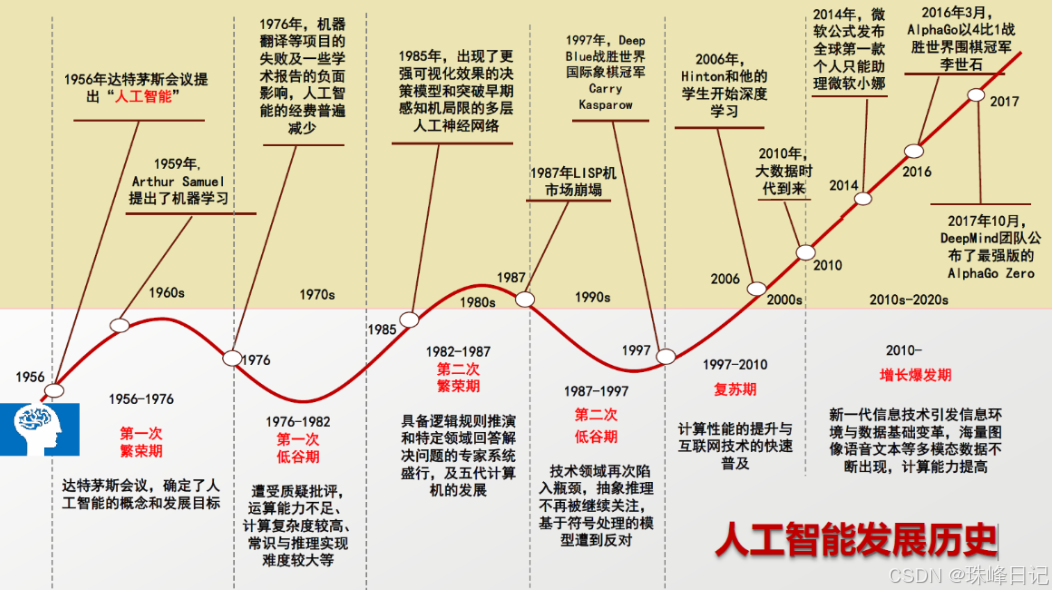
深度学习模型的发展历程演进可划分为五个关键阶段,每一阶段均伴随着理论上的重大突破与技术层面的革新,逐步揭开人工智能世界的神秘面纱。

启蒙时期与早期模型
M - P模型
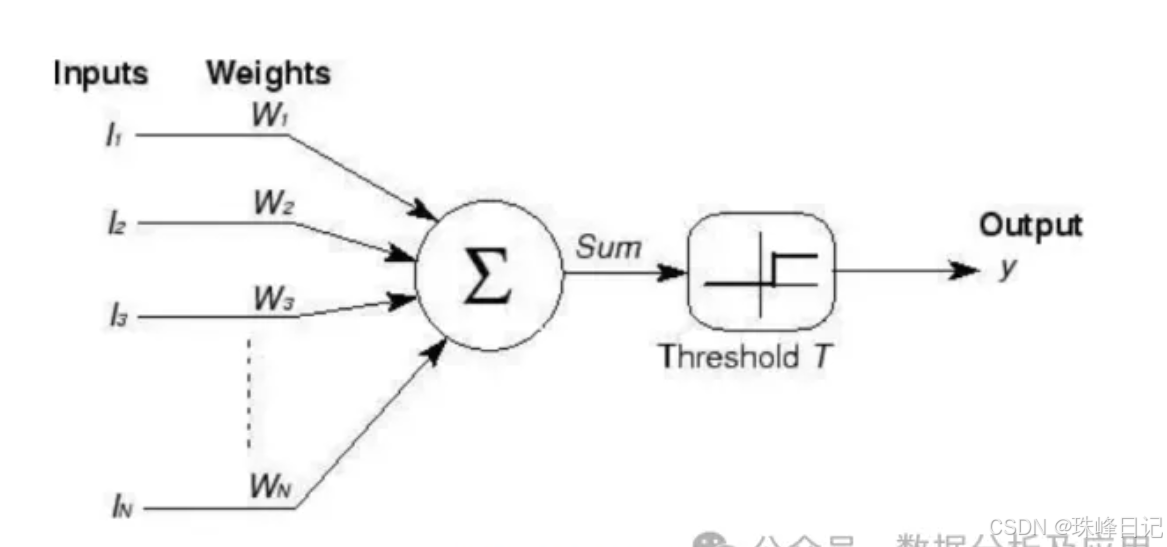
在20世纪40年代,计算机科学与人工智能尚处于萌芽阶段,一切都充满了未知与探索。心理学家Warren McCulloch和数学家Walter Pitts提出的M - P模型,宛如一颗闪耀的启明星,照亮了神经网络研究的前行道路。
M - P模型旨在模仿生物神经元的运作机制。我们知道,生物神经元犹如一个个微小但功能强大的信息处理器。它们从众多其他神经元接收信号,这些信号通过神经元之间的连接——突触传递过来。每个突触都具有特定的强度,这个强度决定了信号传递的效果。当神经元接收到的信号总和超过某个特定阈值时,神经元就会被激活,进而产生一个输出信号,传递给与之相连的其他神经元。
M - P模型正是基于这样的生物原理构建。它将神经元抽象为一个简单的数学模型,模型接收多个输入信号,每个输入信号都被赋予一个权重,这个权重就类似于生物突触的强度。这些输入信号与各自的权重相乘后进行累加。例如,假设有三个输入信号x1、x2、x3,对应的权重分别为w1、w2、w3,那么累加的结果s = x1 * w1 + x2 * w2 + x3 * w3 。随后,这个累加结果会与一个预设的阈值θ进行比较。如果s大于等于θ,神经元就会被激活,输出一个固定值,通常设为1;反之,如果s小于θ,神经元则不会被激活,输出值为0 。这个激活过程通过简单的逻辑运算模拟,比如可以用阶跃函数来表示。
尽管M - P模型如今看来十分基础和简单,其仅能处理极为简单的逻辑运算,如与、或、非等,但在当时,它的出现具有非凡的意义。它首次以数学模型的形式阐述了神经元的工作方式,为后续神经网络研究搭建了最基础的框架,宛如为一栋宏伟的大厦奠定了第一块基石,开启了人们对神经网络探索的大门,激励着无数科研人员在这个全新的领域不断钻研与创新。
Hebb学习规则
1949年,心理学家Donald Hebb提出了具有深远影响的Hebb学习规则,这是一种无监督学习规则。无监督学习意味着不需要人为标记数据的类别,模型能自主从数据中挖掘规律。
Hebb学习规则的神奇之处在于,它能让神经网络自动提取训练集的统计特性。举个例子,假设有一堆水果图片作为训练集,里面有苹果、橙子、香蕉等。Hebb学习规则能让神经网络从这些图片中发现苹果的一些共同特征(比如大致的形状、颜色范围)、橙子的特征以及香蕉的特征等。通过不断学习,网络就能依据这些统计特征,把输入的水果图片按照相似性程度分成苹果类、橙子类、香蕉类等若干类别。这是不是和我们人类观察和认识世界的过程很像呢?我们在生活中,也是在不知不觉地根据事物的各种统计特征来进行分类。比如,我们看到天上飞的,有尖尖的嘴、羽毛和翅膀,能大致判断这是鸟类;看到在水里游的,有鳞片、鳍,就知道这大概率是鱼类。
从技术原理来讲,Hebb学习规则非常简洁,它只依据神经元连接间的激活水平来改变权值。当两个相连的神经元同时处于活跃状态,也就是它们的激活水平都很高时,它们之间连接的权值就会增强,就好像它们之间的“联系纽带”变得更牢固了;反之,如果两个神经元很少同时活跃,它们之间连接的权值就可能减弱。这种基于神经元激活同步性来调整连接强度的方式,为后续神经网络学习算法的设计开辟了新的方向,让神经网络具备了自主学习和分类的基础能力 。
感知器时代
感知器模型
到了20世纪50年代至60年代,Frank Rosenblatt提出了感知器模型。感知器是一种特别简单的神经网络结构。比如说,我们要做一个能区分苹果和橙子的小系统,感知器就可以派上用场。它主要处理那种能简单分成两类的问题。但是呢,它有个很大的局限性,它只能处理线性可分的问题。什么叫线性可分呢?简单来说,就是如果把苹果和橙子的数据在一个图上表示出来,能用一条直线把代表苹果的数据点和代表橙子的数据点分开,那感知器就能处理。可要是数据分布得乱七八糟,这条直线怎么都画不出来,感知器就没办法了。因为这个局限性,当时神经网络的研究就遇到了瓶颈,发展不下去,陷入了停滞状态。
连接主义与反向传播算法的提出
连接主义
20世纪60年代末至70年代,虽然神经网络研究整体上不太顺利,处于低谷期,但连接主义这个概念却在慢慢发展。连接主义强调的是,神经网络的功能主要靠神经元之间的连接以及它们相互之间的作用。就好像一个交响乐团,每个乐器就像一个神经元,单独一个乐器演奏可能不好听,但是当它们通过各种连接(也就是演奏时的配合),就能演奏出美妙的音乐。连接主义让大家更关注神经元之间是怎么协同工作的,这对理解和设计神经网络很有帮助。
反向传播算法
1986年,David Rumelhart、Geoffrey Hinton和Ron Williams等科学家提出了误差反向传播(Backpropagation)算法。这个算法可太重要了!我们训练神经网络的时候,希望它能给出正确的结果。比如我们教神经网络认猫和狗,训练之后它可能还是会认错。那怎么办呢?反向传播算法就来解决这个问题。它能让神经网络知道自己错在哪里,然后通过调整神经元之间连接的权重,也就是前面说的Hebb学习规则里提到的连接强度,来让自己的错误越来越小。这个过程就好像你考试没考好,老师帮你分析错题,你知道自己哪里错了,然后下次考试的时候就会注意,成绩就可能提高。反向传播算法的出现,让多层神经网络的训练变得可行,一下子让神经网络的研究又热了起来,就像给快要熄灭的火添了一把柴。
深度学习时代的来临
在感知机时代,神经网络因为受到计算机算力的限制,表现不太好,所以被很多人质疑。但是后来,计算机的计算能力变得越来越强,能处理的数据也越来越多,算法也有了很大的改进,这些突破就像三把钥匙,打开了深度学习时代的大门。
多层感知器(MLP)
在反向传播算法的推动下,多层感知器(MLP)出现了,它成为多层神经网络的典型代表。MLP有多个隐藏层,这就好比一个人要经过很多层思考才能得出复杂的结论。它能够学习复杂的非线性映射关系。比如说在自然语言处理(NLP)这个领域,我们要理解一句话的意思,这句话里词与词之间的关系很复杂,不是简单的线性关系。MLP就能对语义共现关系进行建模,成功地捕捉到那些复杂的语义依赖。比如说“苹果从树上掉下来”和“苹果很好吃”,这两句话里“苹果”这个词的含义在不同语境下是有细微差别的,MLP就能通过学习这些复杂关系来更好地理解。
随着计算能力提升与大数据普及,基于多层神经网络的深度学习逐渐成为神经网络研究的热点领域。下面给大家看一段示例代码,通过这段代码能看到怎么用MLP识别图片(不过要注意哦,在实际处理图像数据时,MLP通常不是最好的选择,卷积神经网络(CNN)会更厉害,这里只是为了简单展示,才用MLP):
import keras
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Flatten
from keras.utils import to_categorical
# 设置参数
batch_size = 128
num_classes = 10
epochs = 12
# 加载MNIST数据集
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# 数据预处理
x_train = x_train.reshape(60000, 784)
x_test = x_test.reshape(10000, 784)
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
y_train = to_categorical(y_train, num_classes)
y_test = to_categorical(y_test, num_classes)
# 构建MLP模型
model = Sequential()
model.add(Dense(512, activation='relu', input_shape=(784,)))
model.add(Dense(512, activation='relu'))
model.add(Dense(num_classes, activation='softmax'))
# 编译模型
model.compile(loss=keras.losses.categorical_crossentropy,
optimizer=keras.optimizers.Adadelta(),
metrics=['accuracy'])
# 训练模型
model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
verbose=1,
validation_data=(x_test, y_test))
# 评估模型
score = model.evaluate(x_test, y_test, verbose=0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
在这段代码里,首先我们从mnist这个数据集里加载了训练和测试用的图片数据,然后对这些数据进行了处理,让它们能符合MLP模型的输入要求。接着构建了MLP模型,这个模型有多个全连接层(Dense层),中间用relu函数来激活神经元,最后用softmax函数来输出分类结果。然后编译模型,告诉它用什么方法来计算损失和优化,最后进行训练和评估,看看模型在测试数据上的表现怎么样。
卷积神经网络(CNN)与循环神经网络(RNN)
在深度学习时代,卷积神经网络(CNN)和循环神经网络(RNN)等模型特别受欢迎,应用也很广泛。CNN特别擅长处理图像数据。我们看一张图片,它是由很多像素组成的,CNN就像一个很会找规律的小侦探,它通过一些卷积核在图片上滑动,能找到图片里不同的特征,比如边缘、颜色块这些。所以在图像识别任务中,像识别交通标志、人脸识别这些,CNN表现得非常好。
而RNN则擅长处理像文本和语音这样的序列数据。比如说一句话,每个词都是有顺序的,不能随便打乱,RNN就能记住前面出现过的信息,然后结合当前的信息来理解整个序列的意思。在语音识别中,它能把连续的语音信号转化成正确的文字。
随着研究不断深入,神经网络模型持续发展创新。比如说生成对抗网络(GAN),它就像两个互相竞争的艺术家,一个负责生成作品(比如生成图像),另一个负责判断这个作品是不是真的(是不是符合真实数据的特征),通过这种对抗的方式,最后能生成非常逼真的图像和视频。长短时记忆网络(LSTM)解决了传统RNN在处理长序列时的梯度问题。想象一下,你读一篇很长的文章,读到后面可能就忘了前面的内容,传统RNN也有类似问题,而LSTM就能很好地记住长时间的信息。注意力机制(Attention Mechanism)就像我们看文章时,会重点关注某些重要的句子和词汇,它能让模型对输入数据中的重要信息更加关注,提高模型的效果。图神经网络(GNN)则是用来处理图结构数据的,比如社交网络里人与人之间的关系,就可以用图来表示,GNN能对这种复杂的关系进行分析和处理。
大模型时代
大模型基于缩放定律,简单来讲,就好像我们盖房子,模型参数就像房子的材料,预训练数据规模就像盖房子的场地。当我们有越来越多的材料,场地也越来越大的时候,盖出来的房子(也就是模型)就会越来越厉害。随着深度学习模型参数和预训练数据规模不断扩大,模型的能力和完成各种任务的效果就会持续提升,甚至会出现一些小规模模型没有的独特“超能力”,我们把这叫做“涌现能力”。
在大模型时代,最有影响力的模型基座就是Transformer和Diffusion Model。基于Transformer的ChatGPT特别有名,它就像一个超级智能的聊天伙伴,你可以和它聊各种话题,它能理解你的意思,然后给出非常准确和有趣的回答,这让大家看到了人工智能技术巨大的潜力。基于Diffusion Model的Sora大模型也很厉害,它让人工智能进入了多模态时代,比如说它能根据文字描述生成对应的图像,或者把图像转化成文字描述,把不同类型的数据联系起来。
Transformer
Transformer最初是为自然语言处理任务设计的。它的核心思想是通过自注意力机制来捕捉输入序列中的依赖关系。打个比方,你看一句话“小明去超市买了苹果和香蕉”,自注意力机制能让模型知道“买”这个动作和“苹果”“香蕉”是有关系的,而不是孤立地处理每个词。和传统的循环神经网络(RNN)相比,Transformer的优势很明显,它能同时处理整个序列,就像我们看一幅画可以一下子看到全貌,而不是像RNN那样一个部分一个部分地看。这样就大大提高了计算效率。而且它提取特征的能力很强,基于Transformer架构产生了很多像BERT、GPT这样的模型,这些模型在海量数据上进行训练后,就像一个知识渊博的学者,有很强的通用表示能力,能为各种下游任务,比如文本分类、机器翻译等,提供很好的解决方案。下面给大家看一段简单的代码来展示Transformer的基本结构和原理(但要知道,实际的Transformer模型,像GPT或BERT,要复杂得多,而且还需要很多预处理步骤,比如把文字分成一个个小单元、给句子填充合适的长度、设置掩码等等):
import torch
import torch.nn as nn
import torch.optim as optim
class Transformer(nn.Module):
def __init__(self, d_model, nhead, num_encoder_layers, num_decoder_layers, dim_feedforward=2048):
super(Transformer, self).__init__()
self.model_type = 'Transformer'
# encoder layers
self.src_mask = None
self.pos_encoder = PositionalEncoding(d_model, max_len=5000)
encoder_layers = nn.TransformerEncoderLayer(d_model, nhead, dim_feedforward)
self.transformer_encoder = nn.TransformerEncoder(encoder_layers, num_encoder_layers)
# decoder layers
decoder_layers = nn.TransformerDecoderLayer(d_model, nhead, dim_feedforward)
self.transformer_decoder = nn.TransformerDecoder(decoder_layers, num_decoder_layers)
# decoder
self.decoder = nn.Linear(d_model, d_model)
self.init_weights()
def init_weights(self):
initrange = 0.1
self.decoder.weight.data.uniform_(-initrange, initrange)
def forward(self, src, tgt, teacher_forcing_ratio=0.5):
batch_size = tgt.size(0)
tgt_len = tgt.size(1)
tgt_vocab_size = self.decoder.out_features
# forward pass through encoder
src = self.pos_encoder(src)
output = self.transformer_encoder(src)
# prepare decoder input with teacher forcing
target_input = tgt[:, :-1].contiguous()
target_input = target_input.view(batch_size * tgt_len, -1)
target_input = torch.autograd.Variable(target_input)
# forward pass through decoder
output2 = self.transformer_decoder(target_input, output)
output2 = output2.view(batch_size, tgt_len, -1)
# generate predictions
prediction = self.decoder(output2)
prediction = prediction.view(batch_size * tgt_len, tgt_vocab_size)
return prediction[:, -1], prediction
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_len=5000):
super(PositionalEncoding, self).__init__()
# Compute the positional encodings once in log space.
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len).unsqueeze(1).float()
div_term = torch.exp(torch.arange(0, d_model, 2).float() *
-(torch.log(torch.tensor(10000.0)) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
def forward(self, x):
x = x + self.pe[:, :x.size(1)]
return x
# 超参数
d_model = 512
nhead = 8
num_encoder_layers = 6
num_decoder_layers = 6
dim_feedforward = 2048
# 实例化模型
model = Transformer(d_model, nhead, num_encoder_layers, num_decoder_layers, dim_feedforward)
# 随机生成数据
src = torch.randn(10, 32, 512)
tgt = torch.randn(10, 32, 512)
# 前向传播
prediction, predictions = model(src, tgt)
在这段代码里,首先定义了Transformer类,它包含了编码器和解码器部分。编码器通过位置编码(PositionalEncoding)给输入数据加上位置信息,然后经过多层TransformerEncoderLayer进行特征提取。解码器也是类似结构,它会根据编码器的输出和目标数据来生成预测。最后通过线性层(decoder)得到最终的预测结果。代码里还定义了位置编码类,它能让模型知道输入数据中每个元素的位置。通过设置一些超参数,比如d_model表示输入特征的维度,nhead表示多头注意力的头数等,然后实例化模型,再用随机生成的数据进行前向传播,看看模型是怎么工作的。
Diffusion Model
Diffusion Model是一种基于扩散过程的生成模型。这个过程有点像把一幅画慢慢弄脏,然后再把它清理干净。它先是逐步向数据中添加噪声,让数据变得越来越乱,然后再通过学习怎么从这些噪声中恢复出原始数据,这样就能对数据的分布有很好的理解和建模。
正向扩散过程:想象有一幅清晰的图像,我们开始对它逐步添加噪声,就像往一幅干净的画上随意洒点小墨点,而且随着时间推移,洒的墨点越来越多,图像就变得越来越模糊,直到最后几乎看不出原来的样子,变成了一团随机的噪声。这个过程就是从清晰的原始数据(图像)逐渐向随机噪声状态演变的过程,被称为正向扩散过程。
反向扩散过程:然后,我们要尝试从这团噪声中把原来的图像还原出来,这就像是一个逆向的、去除噪声的过程。我们通过学习和分析噪声的特点以及图像的一些先验知识,一点一点地把噪声去掉,让图像逐渐恢复清晰,最终变回我们最初的那幅清晰图像。这个从噪声中恢复原始数据的过程就是扩散模型的核心,它通过不断地学习如何逆转正向扩散过程,来生成新的、类似原始数据的样本。
小结
当下,大模型时代的神经网络模型通常具有更高计算复杂度和更大参数规模。这主要得益于计算机硬件的不断进步,现在的电脑处理器越来越快,内存也越来越大,就像给模型提供了一个更强大的“工作间”。同时,算法的不断优化也很重要,就像有了更高效的工作流程。大规模数据的收集与处理也为这些模型的训练提供了有力支撑,大量的数据就像丰富的原材料,让模型能学习到更多的知识。
然而,大模型也面临很多挑战:首先是高质量数据资源短缺,就好比做饭没有好食材,模型训练出来的效果也会受影响。计算资源消耗巨大,训练一个大模型可能需要非常多的电脑和很长的时间,成本很高。还有模型泛化能力有待提升,也就是说模型在新的、没见过的数据上表现可能不好,就像一个学生只会做老师讲过的题,遇到新题就不会了。但尽管有这些挑战,科学家们还是在不断努力,相信未来深度学习模型会有更大的突破和发展。


















 2531
2531

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









