







git下面有一个spark项目,用的版本是1.6.2,据说很稳定的一个版本,因为在2.0以后出来一个sparksession整合df和df 于是将spar库版本升到2.4.3,下面是遇到的问题
1.升级后找不到org.apache.spark.Logging。
1.6.2中用的trait Logging 找不到org.apache.spark.Logging。
在spark2.4.3中对应是org.apache.spark.internal.Logging2.toArray()算子已经被collect替代
3.并且编译报错 missing or invalid dependency detected while loading class file 'ProductRDDFunctions.class'.
Error:scalac: missing or invalid dependency detected while loading class file 'ProductRDDFunctions.class'.
Could not access type Logging in package org.apache.spark,
because it (or its dependencies) are missing. Check your build definition for
missing or conflicting dependencies. (Re-run with `-Ylog-classpath` to see the problematic classpath.)
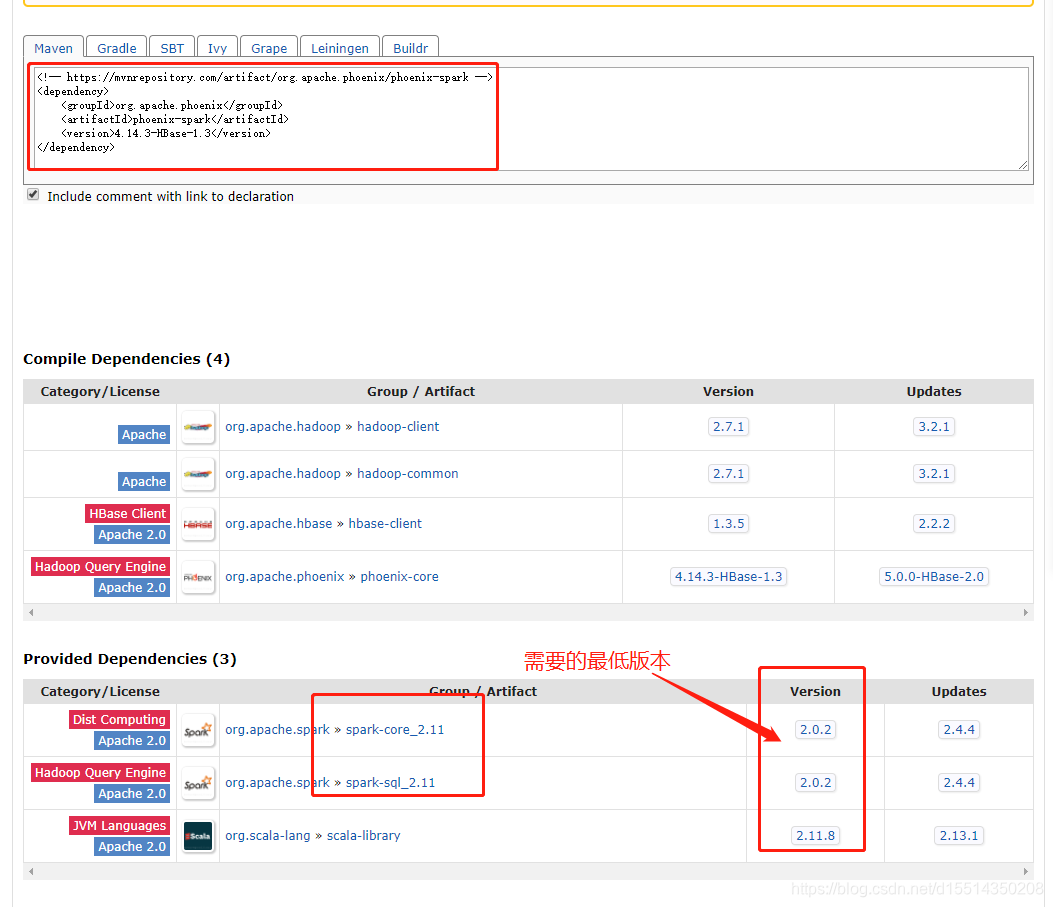
A full rebuild may help if 'ProductRDDFunctions.class' was compiled against an incompatible version of org.apache.spark.进入到ProductRDDFunctions源码属于 phoenix-spark版本4.9.0-hbase-1.2包中,报错提到Could not access type Logging in package org.apache.spark, 上面提到logging在2.4.3中全路径是org.apache.spark.internal.Logging。可以判定jar不匹配导致的
本地用的spark是2.4.3 scala2.11,在maven库中找比较新的版本(自己选用的4.14.3-HBase-1.3版本),更新pom依赖版本后问题解决
4.升级后编译报错算子mean(),问题为解决,后期解决了补上
val test: DataFrame = frame.select("rating", "prediction")
// rating为表中已有的数据,prediction为计算出的预测值
// mean()为取平均值
// 原来的用法
// test.map(x=>math.pow(x.getDouble(0)-x.getDouble(1),2)).mean()
//修改后的用法
val testresult: Dataset[Double] = test.map(x=>math.pow(x.getDouble(0)-x.getDouble(1),2))
val MSE: DataFrame = testresult.describe("mean")
//修改后编译时报错信息
Error:(32, 45) Unable to find encoder for type Double. An implicit Encoder[Double] is needed to store Double instances in a Dataset. Primitive types (Int, String, etc) and Product types (case classes) are supported by importing spark.implicits._ Support for serializing other types will be added in future releases.
val testresult: Dataset[Double] = test.map(x=>math.pow(x.getDouble(0)-x.getDouble(1),2))
//按照报错提示添加implicit var matchError = org.apache.spark.sql.Encoders[DoubleType]依然报错
















 4895
4895

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









