



 本文介绍了一个使用Python 3.6和PyCharm实现的简单爬虫程序,该程序能够抓取猫眼电影Top100榜单的数据,并将这些数据保存到本地文件中。爬虫利用requests库获取网页源代码,通过lxml解析网页内容,最终实现了批量抓取数据的目标。
本文介绍了一个使用Python 3.6和PyCharm实现的简单爬虫程序,该程序能够抓取猫眼电影Top100榜单的数据,并将这些数据保存到本地文件中。爬虫利用requests库获取网页源代码,通过lxml解析网页内容,最终实现了批量抓取数据的目标。
大家好,今天小编给大家介绍一个爬虫小程序。
在此,小编用的python版本为3.6,编辑软件为pycharm。
首先我们导入需要的模块。
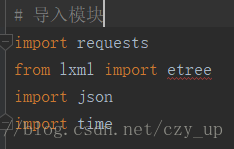
模块大多为第三方模块,我们可通过命令行安装:
Pip install requests
也可通过pycharm设置安装
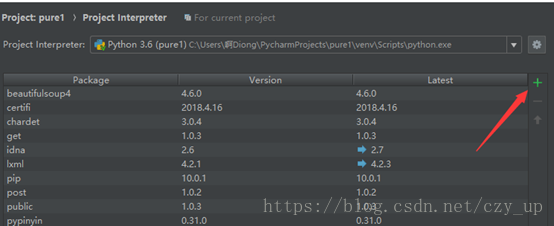
当我们导入好模块之后即可开始编写我们今天的代码
首先我们定义一个函数用于获取我们所需网页源代码

但是由于大多数网页有反爬虫措施,有许多内容限制我们访问,所以我们得加一个请求头,模拟一个浏览器打开网页,这样才可读取网页源代码

读取源代码之后,我们便可寻找我们所需要的信息了,匹配信息有许多种方法,例如beautifulsoup,在这里我们用的是lxml,正则表达式如下:

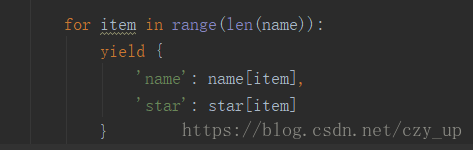
再把我们匹配到的信息遍历出来
然后根据网页网址的特性,将爬我们所需的网站个数

最后将我们找到的信息保存到本地即可

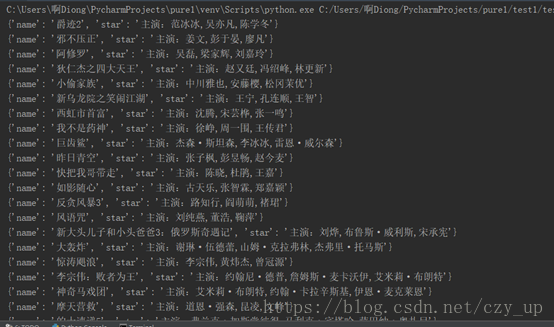
程序运行结果如下
以下是我程序全代码:
# 导入模块 import requests from lxml import etree import json import time class MaoYao(object): def __init__(self): self.header = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.328' '2.140 Safari/537.36 Edge/17.17134' } def getOnePage(self, url): html = requests.get(url, headers=self.header) return html.text def parseOnePage(self, text): html = etree.HTML(text) name = html.xpath('//p[@class="name"]//text()') star = html.xpath('//p[@class="star"]//text()') for item in range(9): yield { 'name': name[item], 'star': star[item] } # 1 @staticmethod def write2File(content): with open(r'C:\Users\啊Diong\Desktop\新建文本文档.txt', 'a', encoding='utf-8') as fp: fp.write(json.dumps(content, ensure_ascii=False) + '\n') # 1 if __name__ == '__main__': maoyan = MaoYao() # 3 try: for offset in range(0, 50, 10): time.sleep(1) url = 'http://maoyan.com/board/6?offset=' + str(offset) html = maoyan.getOnePage(url) text = maoyan.parseOnePage(html) # 3 # 2 for item in text: maoyan.write2File(item) print(item) except: print("")

















 5264
5264

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









